Bei der Vorbereitung zu meinem nächsten Vortrag zum Thema Regular Expressions musste ich schmerzerfüllt feststellen, dass LaTeX beim Versuch, Regexen vernünftig zu formatieren, ein ganz schön widerwärtiges Biest sein kann. Um diese Aufgabe etwas zu erleichtern und außerdem den Aufbau der Regexen dem Publikum etwas strukturierter vorstellen zu können, bediene ich mich nun folgender LaTeX-Kommandos:
\definecolor{White}{rgb}{1,1,1}
\definecolor{Grey}{rgb}{0.5,0.5,0.5}
\definecolor{Brown}{rgb}{0.3,0.3,0}
\definecolor{Red}{rgb}{0.7,0,0}
\definecolor{Green}{rgb}{0,0.7,0}
\definecolor{Darkblue}{rgb}{0,0,0.5}
\definecolor{Violet}{rgb}{0.8,0,0.9}
\definecolor{Orange}{rgb}{0.8,0.4,0}
\newcommand{\RegEx}[1]{/#1/}
\newcommand{\LargeRegEx}[1]{{\large /#1/}}
\newcommand{\Or}{\textcolor{Brown}{\textbar}}
\newcommand{\Kleene}{\textcolor{Violet}{*}}
\newcommand{\OneOrMore}{\textcolor{Violet}{+}}
\newcommand{\ZeroOrOne}{\textcolor{Violet}{?}}
\newcommand{\Begin}{\textcolor{Brown}{\^{}}}
\newcommand{\End}{\textcolor{Brown}{\textdollar}}
\newcommand{\MLBegin}{\textcolor{Brown}{\Escape{A}}}
\newcommand{\MLEnd}{\textcolor{Brown}{\Escape{Z}}}
\newcommand{\Escape}[1]{\textbackslash{}#1}
\newcommand{\Wordchar}{\textcolor{Darkblue}{\Escape{w}}}
\newcommand{\Space}{\textcolor{Darkblue}{\Escape{s}}}
\newcommand{\Nonwordchar}{\textcolor{Darkblue}{\Escape{W}}}
\newcommand{\Digit}{\textcolor{Darkblue}{\Escape{d}}}
\newcommand{\Match}[1]{$($#1$)$}
\newcommand{\Matches}[1]{\textcolor{Darkblue}{\textbackslash{}#1}}
\newcommand{\Repeat}[1]{\textcolor{Violet}{${$#1$}$}}
\newcommand{\AnyOf}[1]{\textcolor{Green}{$[$#1$]$}}
\newcommand{\NoneOf}[1]{\textcolor{Red}{$[$\^{}#1$]$}}
\newcommand{\AnyNumberOf}[1]{#1\Kleene}
\newcommand{\OneOrMoreOf}[1]{#1\OneOrMore}
\newcommand{\ZeroOrOneOf}[1]{#1\ZeroOrOne}
\newcommand{\Modifier}[1]{\textcolor{Orange}{#1}}
Diese Anweisungen müssen for dem \begin{document}-Stanza stehen, damit man innerhalb des Dokuments dann z.B. folgende Regex inklusive Syntaxhighlighting darstellen kann:
/^[\w\d._%+-]+@[\w\d.-]+.\w{2,4}$/
wird in LaTeX zu:
\RegEx{\Begin\OneOrMoreOf{\AnyOf{\Wordchar\Digit.\_\%+-}}@\OneOrMoreOf{\AnyOf{\Wordchar\Digit.-}}\Escape{.}\Wordchar\Repeat{2,4}\End}
Gerendert wird das dann in etwa so:
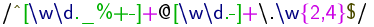
Bei der Darstellung der Sonderzeichen in LaTeX hat mir dieses Dokument sehr geholfen: Everybody Loves Regular Expressions!



