Es begab sich zu einer Zeit, als das ARPANET noch blühte und ein Hacker noch ein Hacker und kein von kriminellen Konotationen bevorurteilter Zeitgenosse war, als -- aus heutiger Sicht -- eines der größten Verbrechen der Computer-Industrie begangen wurde: das File Transfer Protocol wurde erfunden und standardisiert. Seitdem sind vermutlich Hunderttausende armer Internetznutzer bereits Opfer der -- aus heutigen Sicht -- hirnrissigen Tatsache geworden, dass FTP ein Plain Text-Protokoll ohne Kennwortverschlüsselung ist. Und während Telnet mittlerweile ein Schattendasein im Lichte von SSH führt (tut es das?!), findet sich noch immer auf jedem Shared Hosting System standardmäßig ein FTP-Zugang für jeden. Von SFTP, RSync oder WebDAV über SSH, SCP und Fish scheint noch nie ein Mensch zuvor gehört zu haben.
Ein Grund mehr also, für mein "imaginäres" Hostingunternehmen Consolving ein weiteres Alleinstellungsmerkmal aufzupolieren: "Bei uns greifen sie stets über erwiesenermaßen sichere Verschlüsselungstechnologien auf Ihre Daten zu!" -- klingt irgendwie gut, weckt Kundenvertrauen, macht das Ganze für erfahrenere Internetnutzer umso attraktiver usw.
Also ran und gleich mal SFTP eingerichtet, das ist mit RSSH (Restricted SSH) sehr einfach. Einfach in /etc/rssh.conf eintragen, dass alle betreffenden Benutzer rsync, scp und sftp nutzen dürfen, und bei den betreffenden Benutzern /usr/bin/rssh als Shell eintragen. Einen Haken hat die Geschichte, und die kann sehr wohl auch zu einem internen Sicherheitsproblem werden: SSH erlaubt es in der "out of the Box"-Variante nicht, die Benutzer in ihr Homeverzeichnis zu "Chrooten" (man verzeihe bitte die vielen Sprachvergewaltigungen an dieser Stelle...). Für eine Shared Hosting-Umgebung mit mehreren Duzend oder gar Hunderten von Kunden ist das natürlich unhaltbar.
Schließlich bin ich doch wieder auf FTP zurückekommen, denn was ProFTP so alles bietet (MySQL-Unterstützung, umfangreiches Quota-Handling, detaillierte und flexible Zugriffsverwaltung pro Host, Gruppe, Klasse, Benutzer, Verzeichnis bis hin zur einzelnen Datei), deckt sich perfekt mit meinen Systemanforderungen. Und als Sagnehäubchen kommt mit mod_tls auch noch verschlüsseltes FTP (FTPS, nicht zu verwechseln mit SFTP, welches ein SSH-Subsystem ist!) hinzu. Das einzige Problem mit FTPS ist, dass längst nicht jeder FTP-Client es untersützt, und außerdem nicht auf Port 20/21 (Daten/Steuerung), sondern auf Port 989 und 990. Diese werden aber duch die meisten Firewalls standardmäßig blockiert (*winkewink* an DVZ@FH Bochum! *grml*) und während viele Internetnutzer bei "Port 21" noch eine leise Glocke bimmeln hören, dürfte "Port 990" vollkommene Ahnungslosigkeit hervorrufen.
Nichtsdestoweniger habe ich nun probehalber einen sicheren FTP-Server eingerichtet (sicher heißt, eine Verbindung ist ausschließlich über TLS möglich) und das funktioniert soweit einwandfrei. Dass in einer Willkommensmail an zukünftige Kunden erklärt wird, wie dieser mit dieser vom de Facto-Standard abweichenden Konfiguration umzugehen hat, versteht sich von selbst :-)
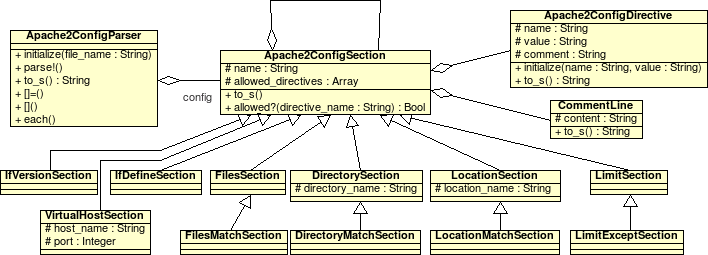
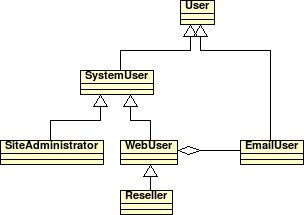
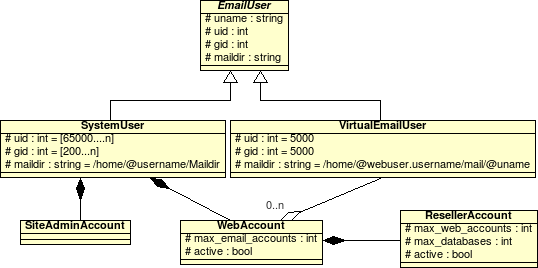
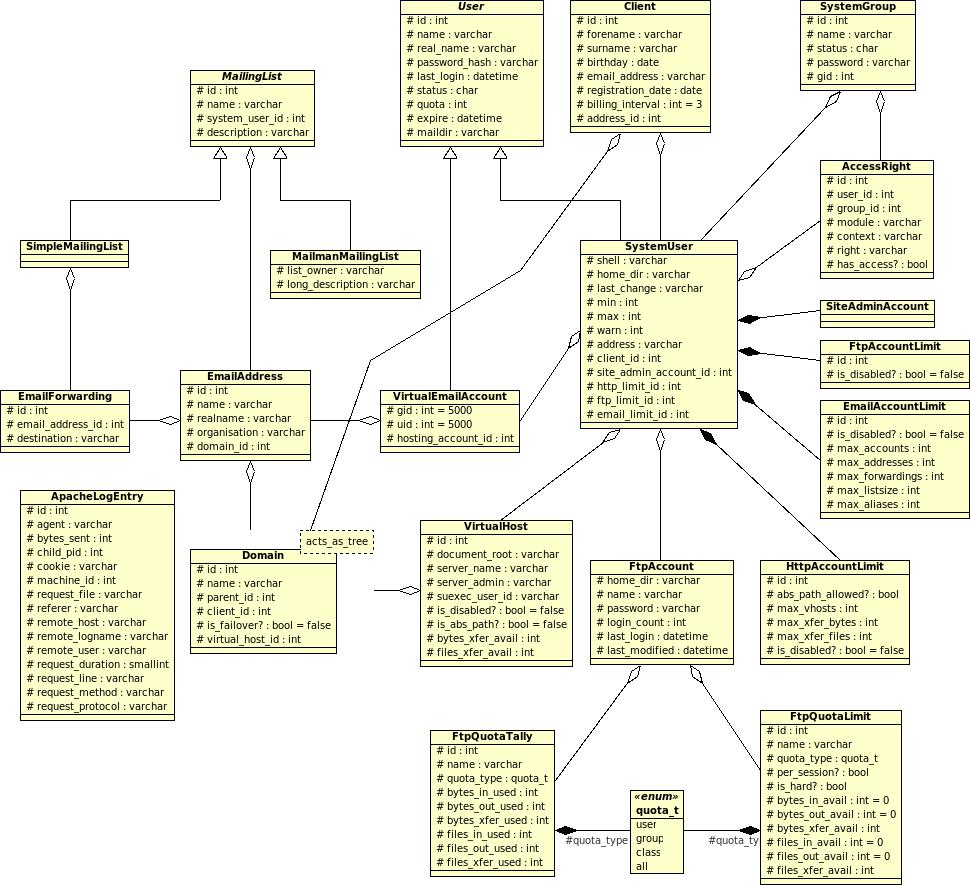
Was nun als nächstes mit Hilfe von ProFTP sehr elegant umgesetzt (und in Consolvix integriert!) werden wird, ist ein Quotasystem und die Benutzerverwaltung. ProFTP ermöglicht den Einsatz virtueller Benutzerkonten über MySQL, was es auch sinnvoll und attraktiv macht, jedem Kunden beliebig viele FTP-Zugänge zur Verfügung zu stellen. Die Idee dahinter: Der Kunde (sprich der ihm zugeordnete Systembenutzer) erhält maximal Q MB Plattenspeicher zur Verfügung gestellt. Das wird in die Quotatabelle eingetragen (und nicht, wie ich erst plante, in die Benutzertabelle). Der Benutzer kann nun neue, virtuelle FTP-Benutzer anlegen und ihnen X MB (< Q, natürlich) Platenplatz zuordnen, bis ΣX = Q. ProFTP's Quotasystem sorgt dafür, dass sowohl die einzelnen Benutzer ihr X, als auch alle Benutzer zusammen (vorgegeben über eine Gruppen-Quota-Regel in der Quotatabelle) Q niemals oder nur kurzzeitig überschreiten.
Durch die geschickte Verwendung von Aggregation (Klassendiagramm folgt später) und die Verwendung der passenden Views auf DB-Ebene kann können so buchhalterische Vorgaben und deren technische einhaltung durch Setzen eines einzigen Wertes, also ohne jegliche Möglichkeit der Dateninkonsistenz, umgesetzt werden.
Doch damit nicht genug: Apache ermöglicht es, Loggingausgaben direkt in eine MySQL-Datenbank zu schreiben. Um das (z.B. monatliche) HTTP-Transfervolumen eines Kunden zu ermitteln, braucht man also nicht mehr als ein SELECT SUM(size) FROM transfer WHERE hostname=[host eines Kunden].
So langsam fängt sie Sache an, wirklich Spaß zu machen ;-)