Ruby kennt keine Strings.
Traurig, aber wahr. Ruby kennt nur irgendwie vermurkste Byte-Arrays, und deswegen musste ich leider heute bei einer formatierten Ausgabe wie dieser
User.find(:all).each do |user|
if user.valid_system_user?
puts "#{user.name.ljust(12, '.')} #{user.real_name[0..24].ljust(25, '.')} " +
"#{user.uid.to_s.rjust(5)} #{user.gid.to_s.rjust(5)} " +
"#{user.home_dir.ljust(23, '.')} #{File.exists?(user.home_dir).to_s.rjust(5)}"
end
end
folgendes feststellen:
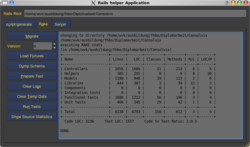
name real name UID GID home dir exists?
wvk......... Xxxxxx xxx Xxxxxxx....... 1001 1001 /home/wvk.............. true
phl......... Xxxxxxx Xxxßxxxxxx...... 1078 100 /home/phl.............. false
ua.......... Xxx Xxxxxxxxx............ 510 100 /home/ua............... false
pg.......... Xxxxxxx Xxxxxx........... 505 505 /home/pg............... false
...
Na, wem fällt's auf? Genau, dem Kollegen mit dem "ß" im Namen fehlt ein '.'. Unschwer zu erraten, woran das liegt: rjust und ljust verwenden intern natürlich die length-Methode von Ruby, um die Länge des darzustellenden Strings zu ermitteln. Diese liefert aber nur bei den Standard-ASCII-Zeichen das richtige Ergebnis, bei anderen UTF8-Codierten Zeichen zwischen 1 und 3 zu viel:
~# irb
irb(main):001:0> "ß".length
=> 2
irb(main):002:0> "€".length
=> 3
Nanu. Um das Problem mit der falsch erkannten Stringlänge zu umgehen, könnte man folgendes verwenden:
$KCODE = 'u'
require 'jcode'
und dann, statt length, jlength verwenden. Dieser hässlichster aller Workarounds die mir diese Woche begegnet sind, funktioniert wie man es von jeder String-Funktion erwarten würde:
irb
irb(main):001:0> $KCODE = 'u'
=> "u"
irb(main):002:0> require 'jcode'
=> true
irb(main):003:0> 'äöü'.jlength
=> 3
irb(main):004:0> '€'.jlength
=> 1
Na bitte, wer sagt's denn. Aber was bringt das jetzt in Verbindung mit rjust? Nur so viel dass man beim selber neu Implementieren der Methoden eine zuverlässige Längenangebe hat (die Methoden jljust bzw. jrjust stellt jcode nämlich nicht zur Verfügung):
class String
def jljust(len, char = ' ')
if len > self.jlength
self + char * (len - self.jlength)
else
self
end
end
def jrjust(len, char = ' ')
if len > self.jlength
char * (len - self.jlength) + self
else
self
end
end
end
In verbindung mit dem neuen Code
User.find(:all).each do |user|
if user.valid_system_user?
puts "#{user.name.jljust(12, '.')} #{user.real_name[0..24].jljust(25, '.')} " +
"#{user.uid.to_s.jrjust(5)} #{user.gid.to_s.jrjust(5)} " +
"#{user.home_dir.jljust(23, '.')} #{File.exists?(user.home_dir).to_s.jrjust(5)}"
end
end
sieht das Ergebnis dann auch so aus wie es aussehen sollte:
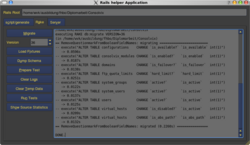
name real name UID GID home dir exists?
wvk......... Xxxxxx xxx Xxxxxxx....... 1001 1001 /home/wvk.............. true
phl......... Xxxxxxx Xxxßxxxxxx....... 1078 100 /home/phl.............. false
ua.......... Xxx Xxxxxxxxx............ 510 100 /home/ua............... false
pg.......... Xxxxxxx Xxxxxx........... 505 505 /home/pg............... false
...
Mehr zum Thema Unicode-Horror in Verbindung mit Rails gibt's unter http://wiki.rubyonrails.org/rails/pages/HowToUseUnicodeStrings zu lesen.