Hallo Welt, ich lebe noch! Und heute kam ich mal wieder etwas mehr voran als die letzten Tage, wo ich im wesentlichen am Klassendesign herumgefeilt und mir gedanken zum Aufbau meiner Programm-Module gemacht habe. Zweiteres wäre einen eigenen Eintrag wert (der auch schon seit drei Tagen in Mache ist...), auf ersteres werde ich jetzt eingehen.
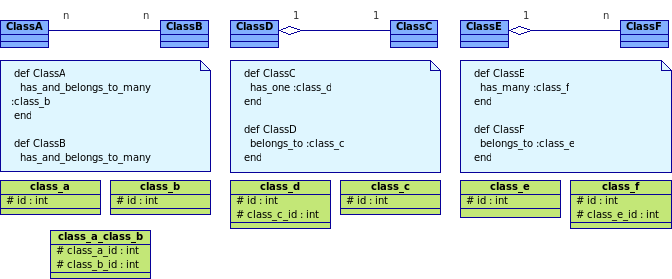
Mittlerweile besteht das Datenbankschema für Consolvix aus etwas über 40 Tabellen und Views, was sich natürlich auch auf Applikationsebene wiederspiegelt. Nicht gerade wenig, und viele Tabellen speichern doch in etwa das gleiche: Logindaten. Einfach, weil ich zu blind war um zu sehen wie man diesen ominösen universellen "User" nun auf Datenbankebene abbilden kann (siehe "Neues aus der Modellier-Ecke"). Nun fiel es mir heute wie Schuppen von den Augen, als ich ich feststellte dass trotz reiflicher Überlegungen zur Klassenhierarchie bei den Benutzerkonten (siehe "Benutzerverwaltung") meine Überlegungen nicht weit genug geführt hatte: Aus Polymorphie zwischen User, EmailAccount und SystemUser mach Aggregation, und zwar nicht vom Benutzer ausgehend, sondern zum Benutzer hin. Auf Datenbankebene bedeutet das: mache eine Tabelle User(id, name, real_name, uid, gid,...) und erstelle für jeden FTP-Account, E-Mail-Account etc. einen neuen Datensatz, dessen Inhalt dann aggregiert wird. Auf Applikationsebene "hat" ein EMailAccount dann ein User-Objekt, wo Logindaten etc. drinstehen. Für die Anwendungen wie der Mailserver, die direkt auf die Daten in einer Tabelle zugreifen können müssen, kommen dann einfach Views zum Tragen.
Eine schöne View ist z.B. die, die aus Systembenutzern, Benutzern und FTP-Kontodaten die Tabelle für die FTP-VirtualHosts bzw. FTP-Accounts zusammenbaut:
CREATE VIEW proftp_virtual_hosts AS
SELECT
`users`.`name` AS name,
`users`.`password` AS password,
IF (`ftp_accounts`.`home_dir`,
`ftp_accounts`.`home_dir`,
`system_users`.`home_dir`
) AS document_root,
`ftp_accounts`.`login_count` AS login_count,
`ftp_accounts`.`last_accessed` AS last_accessed,
`ftp_accounts`.`last_modified` AS last_modified,
IF (`system_users`.`shell`,
`system_users`.`shell`,
'/bin/false'
) AS shell,
`users`.`system_uid` AS uid,
`users`.`system_gid` AS gid
FROM
`ftp_accounts`,
`system_users` RIGHT JOIN `users` ON (`system_users`.`user_id` = `users`.`id`)
-- access_rights AS a
WHERE
`users`.`id` = `ftp_accounts`.`user_id`
AND `ftp_accounts`.`is_disabled?` = 0
AND `users`.`is_disabled?` = 0
Resultat:
| Field | Type | Null | Default |
| id | int(10) | No | |
| login_count | int(11) | No | 0 |
| last_accessed | datetime | No | 0000-00-00 00:00:00 |
| last_modified | datetime | No | 0000-00-00 00:00:00 |
| is_disabled? | tinyint(1) | No | 0 |
| user_id | int(11) | No | |
| home_dir | varchar(35) | No | |
Der FTP-Server kann dann auf die Daten zugreifen, als wäre es eine ganz normale Tabelle (ja, Zugriffszeiten und login_count lässt sich auch über die View aktualisieren), aber auf Applikationsebene ergeben sich durch das Auslagern der gemeinsamen "Benutzer"-Daten erhebliche Vorteile in der Rechteverwaltung. So kann dort bei der Authentisierung immer mit dem Benutzer-Objekt ohne Unterscheidung, ob es nun ein E-Mail oder FTP-Konto ist, gearbeitet werden. Im Klassendiagramm, sprich auf Applikationsebene, sieht obiger Zusammenhang so aus:
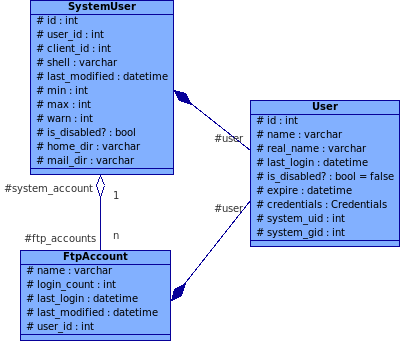
Ganz ähnlich, nur noch die eine oder andere Tabelle mehr erfordernd, sieht es mit den E-Mailkonten aus. Bei der Unten aufgeführten Lösung wird nicht mehr zwischen "virtuellen" und "echten" E-Mail-Konten unterschieden. Jedes E-Mailkonto "ist" bzw. "hat" auch einen Benutzer ("hate", weil Komposition -- obwohl eigentlich der "ist ein"-Gedanke durch Vererbung hadinter steckt und die Komposition an die Stelle der Polymorphie tritt). Dem E-Mailserver ist es egal, ob dieser "E-Mailbenutzer" nun auch ein Systemkonto besitzt (eindeutige UID/GID) oder ob es sich dabei um einen "virtuellen Benutzer" handelt, der in diesem Fall immer die UID/GID 5000 hat. Auch Consolvix' Authorisierungsfunktionen ist es herzlich egal, ob sich da via Web-Interface nun ein reiner E-Mailbenutzer oder etwas anderes einloggt, denn diese benutzen nur die im User-Objekt gespeicherten Informationen -- insbesondere sind sämtliche Zugriffsrechte allein am User gekoppelt.
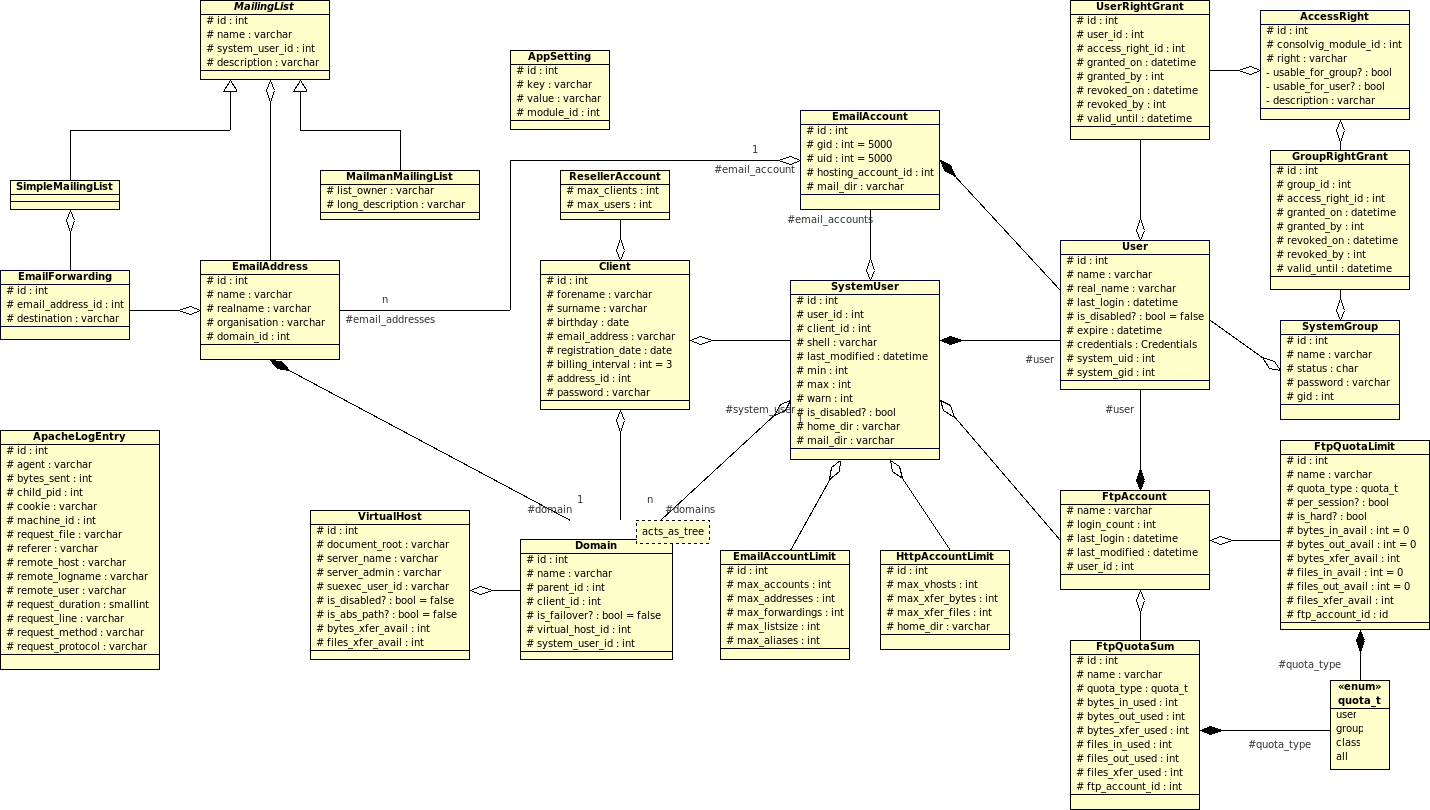
Nundenn, so sieht der wichtigste Teil des E-Mail-"Subsystems" aus:
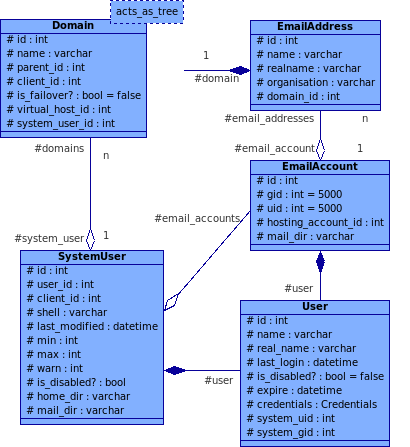
Die E-Mailadresse stellt eine eigene Entität dar, weil offensichtlich mehrere E-Mailadresse für das gleiche POP/IMAP-Konto bestimmt sein können. Dass die Domain in der E-Mailadresse nochmal über einen Fremdschlüssel referenziert ist, macht die ganze Sache noch eine kleine Stufe komplifizierter, aber es soll ja ein konsistentes Datenbankschema sein. Dennoch beinhaltet obiges Scheme noch ein u.U. signifikantes Problem, und wer es herausfindet der kriegt von mir einen HTTP-Keks ;-)
Wie auch immer, der E-Mailserver benötigt eine einzige schön aufbereitete Tabelle, um seine Mails zu liefern. Deswegen übernimmt auch hier eine hübsche kleine View das. Bis auf die Subqueries, auf die ich unten kurz eingehe, sollte alles auch ohne Kommentare halbwegs selbsterklärend sein, ansonsten einfach einen Kommentar schreiben, ich erläutere gerne mehr.
CREATE VIEW `postfix_accounts` AS
SELECT
CONCAT(`name`, '@', (SELECT `value` FROM `app_settings` WHERE `key` = 'mail_domain_name')) AS `account`,
`name`,
`real_name`,
`password`,
`quota`,
IF (`email_accounts`.`mail_dir`,
`email_accounts`.`mail_dir`,
CONCAT(`home_dir`, '/mail/', `name`, '/Maildir/')
) AS `maildir`,
(SELECT `system_uid`
FROM `users` JOIN `app_settings` ON (`users`.`name` = `app_settings`.`value`)
WHERE `app_settings`.`key` = 'mailbox_user_name'
) AS `uid`,
(SELECT `system_gid`
FROM `system_groups` JOIN `app_settings` ON (`system_groups`.`name` = `app_settings`.`value`)
WHERE `app_settings`.`key` = 'mailbox_group_name'
) AS `gid`
FROM
(`system_users` RIGHT JOIN `users` ON `system_users`.`user_id` = `users`.`id`),
`email_accounts`
WHERE
`users`.`id` = `email_accounts`.`user_id`
AND `email_accounts`.`is_disabled?` = 0;
Resultat:
| Field | Type | Null | Default |
| account | varchar(301) | Yes | NULL |
| name | varchar(50) | No | |
| real_name | varchar(32) | No | |
| password | varchar(40) | No | x |
| quota | varchar(10) | No | |
| maildir | varchar(97) | Yes | NULL |
| uid | int(11) | Yes | NULL |
| gid | int(11) | Yes | NULL |
So, und was hat das mit den Subqueries auf sich? Wie ich noch nirgends erwähnt habe, gibt es für Consolvix eine eigene Entität, AppSettings, in der konfigurierbare Einstellunen gespeichert werden. Man kann ja nicht erwarten, dass die Systemkonfiguration in die Datenbank ausgelagert wird und dann die verwaltende Applikation für sich selbst wieder auf Konfigurationsdateien zurückgreift :-) -- jedenfalls wird in der Tabelle app_settings jeweils ein Schlüssel-Wert-Paar gespeichert, mit Angabe des zugehörigen Moduls. Innerhalb der Applikation ermöglicht die folgende Methode, diese Einstellungen schnell und einfach zu erhalten:
def setting(setting_name)
setting = AppSetting.find_by_key(setting_name,
:conditions => {:module_id => @current_module.id,
:version => @current_module.version} )
setting.value
end
Und wer genau hinschaut, entdeckt im wesentlichen genau die SQL-Abfrage als Subquery in den Views. Was im Datenbankschema noch nicht umgesetzt ist, ist jedoch die Versionierung der Module etc. Überhaupt bin ich noch unentschlossen, was die Versionierung der Applikationseinstellungen angeht. Denn nochmals je eine Subquery um Modul-ID und aktuelle Version herauszufinden scheint mir gegenärtig etwas übertrieben, auch wenn man da mit Stored Procedures ja einiges machen kann. Da mich zur Zeit aber ohnehin das Gefühl beschleicht, mehr ER-Modellierung als RoR zu machen, werde ich es erstmal dabei belassen.
Und für die UML-Liebhaber, hier ein Schnappschuss des wichtigsten Teils des Klassendiagramms:
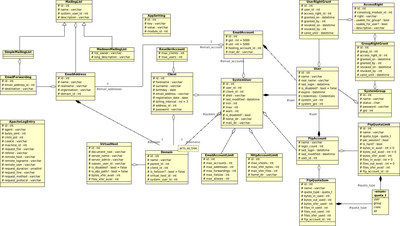
Stay tuned, Folks!