Nach einem äußerst interessanten Vortrag in Essen über Themen aus der Quantenmechanik von Prof. Dr. Anton Zeilinger persönlich ergab es sich vorhin, dass Philipp und ich und ich zu einer kleinen Diskussionsrunde zusammenfanden, um ein Wenig über das Thema Konfigurationsverwaltung auf Webservern zu diskutieren. Dabei kam es, wie in solchen Diskussionen "leider" üblich, zu jeder Menge neuer Ideen, die ich am liebsten schon von Anfang an in meine Diplomarbeit eingebaut hätte.
Nachdem ich nun in meiner Serververwaltungs-Applikation so etwas wie Konfigurationsversionen eingebaut habe, stellte sich eine weitere, alles andere als triviale Frage: Wie ist das mit Konfigurationsdateien? Bekanntlich habe ich es zur Prämisse gemacht, dass Konfigurationsdateien, sofern sie sich nicht durch Datenbankeinträge ersetzen lassen, direkt von Consolvix bearbeitet werden und nicht jedes Mal aus Datenbankeinträgen generiert werden (uns somit händische Änderungen womöglich rückgängig machen). Um hier auch verschiedene Konfigurationen mit verschiedenen Einstellungen zu erlauben, wäre es denkbar, jeder Konfigurationsdatei z.B. eine entsprechende Endung zu geben die mit dem Schlüssel der jeweils aktiven Konfiguration in der Datenbank übereinstimmt. Diesen Gedanken habe ich nicht weiter verfolgt, da er mir etwas umständlich erschien. Wesentlich besser finde ich die Idee, generell alle Konfigurationsdateien (z.B. das komplette /etc-Verzeichnis) mit Subversion zu
verwalten. So könnte man Konfigurationen ändern wie man lustig ist, und wenn mal irgendwann das halbe System dadurch abgeschossen sein sollte, dann checkt man eben eine ältere Konfiguration aus und versucht es von neuem. Um dann noch aus verschiedenen Systemkonfigurationen (Produktion, Wartung, ...) wählen zu können, könnte man immer noch mit Branching arbeiten: Für jede mögliche Konfiguration wird einfach ein neuer Zweig des Repositorys angelegt. Nachdem ich dann mal kurz Gebrauch vom allwissenden Dämon Google gemacht hatte, stieß ich auf ein e Beschreibung, wie man mittels SWIG die Subversion-Bindings für Ruby installiert (für Debian-Benutzer ist es noch einfacher: apt-get install libsvn-ruby ;-)). Besser noch: nach weiterem Googlen fand ich dann das Rails-Plugin acts_as_subversioned für versioniertes ActiveRecord, das Datenbankentitäten versioniert abspeichert! Etwas derartiges wäre eigentlich für mein Gesamtsystem von Anfang an sehr praktisch gewesen -- ich fürchte aber, dass es etwas zu viel Zeit kosten würde, das jetzt noch einzubauen (nach Ende der Diplomarbeit werde ich es aber auf jeden Fall weiter verfolgen!)
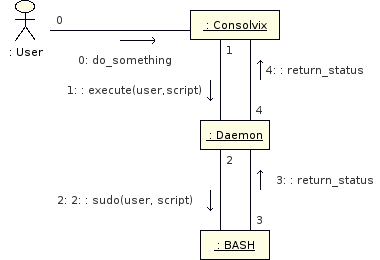
Ein weiteres Thema des o.g. Brainstormings war: Wie lasse ich Consolvix Veränderungen am System vornehmen, wenn diese nicht über die Datenbank abgefackelt werden? Momentan habe ich den Benutzer www-data einfach in die Gruppen gepackt, die Zugriff auf die zu den Diensten gehörenden Ordner hat, die es konfigurieren soll (Beispielsweise Gruppe subversion für /var/svn) Auf lange Sicht müsste dazu Consolvix aber root-Reche bekommen -- und spätestens hier sollten sämtliche Alarmglocken losklingeln. Also werde ich vermutlich folgende Lösung verwenden: Für alle durchzuführenden Änderungen im System wird ein Shell-Kommando oder -Script erstellt. Dieses wird an einen kleinen Dämon mit setuid=root weitergereicht, der genau zwei Kommandos ausführt: sudo <Benutzer> und das angegebene Kommando/Script. <Benutzer> ist hierbei immer die UID des gerade in Consolvix eingeloggten Benutzers. So wird sichergestellt, dass Consolvix selbst immer ein unprivilegierter Dienst bleibt und alle durchzuführenden Kommandos immer als der User ausgeführt werden, der gerade in Consolvix eingeloggt ist. Das geht, weil System- und Consolvix-Benutzer identisch sind.
Eine Idee war es, die so generierten Kommandos zuerst in ein Subversion-Repository einzuchecken, damit diese vom o.g. Dämon zuerst ausgecheckt und dann durchgeführt werden. Der Hintergedanke dazu war der, dass das erste Zielsystem für Consolvix aus einem Test- und einem Produktionssystem bestehen wird. Im Testsystem werden iterativ Änderungen vorgenommen und erst wenn das System zufriedenstellend lauft, werden diese auch am Produktionssystem vorgenommen. Hier wäre die Idee mit Subversion nicht schlecht, denn so würde sichergestellt werden, dass, ähnlich wie bei Rails-Migrations, immer alle Änderungen in der richtigen Reihenfolge und genau so durchgeführt werden.
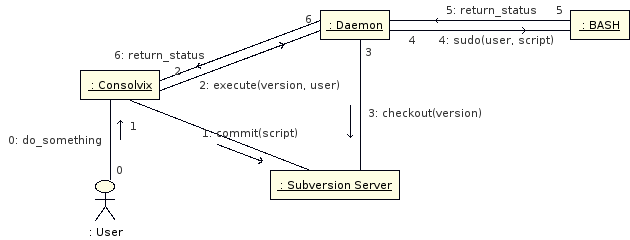
Allerdings verletzt das die andere Arbeitsprämisse, nämlich dass manuelle Änderungen im System genauso behandelt werden sollen wie von Consolvix durchgeführte -- und jedes Mal manuell ein Shell-Skript zu erstellen, dieses einzuchecken und dann ausführen zu lassen ist gelinde gesagt etwas umständlich. Im Mainframe-Bereich ist das zwar Praxis, aber wir betreiben ja nur einen kleinen Linux-Server... Ich denke, dass in die Richtung noch mehr Gedanken folgen werden, aber bis auf Weiteres werde ich erstmal so weitermachen wie bisher.
