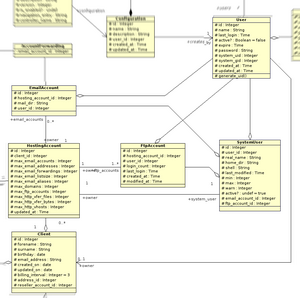
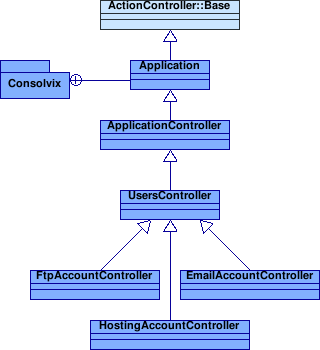
Benutzerauthentifizierung und-Autorisierung Teil 1
Vorweg:
- Authentifizierung (Authentication) = Der Vorgang des Feststellens, ob jemand der ist, den er vorgibt zu sein
- Autorisierung (Authorisation) = Der Vorgang der Überprüfung, ob jemand das darf, was er machen will
- Login = Beginn einer Sitzung, während der Befehle von ein und demselben authentifizierten Benutzer aufgerufen werden
- Web-Applikationsentwiklung = Die Kunst, über ein statusloses Protokoll, welches laut REST-Paradigma auch statuslose Sitzungen verwenden sollte, dem Benutzer gleichzeitig die Illusion einer statusbehafteten Arbeitssitzung als auch die Illusion jener Statuslosigkeit zu schaffen, dass er jederzeit, von überall aus, parallel und ohne Schritte wie Login und "starte Transaktion A" wiederholen zu müssen, jede beliebige Aktion, welche zu genau jenem Zwecke immer eindeutig adressierbar sein soll, zur Erfüllung seiner Arbeit aufrufen kann.
Habe ich ein Problem? Neiiin.. es ist nur... wie kombiniere ich Statuslosigkeit mit der Statushaftigkeit, damit sowohl Otto Dummuser als auch REST-Fetischisten wunschlos glücklich sind? Also Wie verwende ich gleichzeitig die Möglichkeit, ein enorm schickes und ergonomisches HTML-Loginformular als auch HTTP Basic Authorization zur Autorisierung der Benutzer anzuwenden?
Mit dieser Frage habe ich mich (oh, ist heute schon wieder Freitag?!?) nun bald eine Woche herumgeschlagen. Und die frohe Botschaft ist: Beides geht nun. Man kann sich sowohl über ein Sitzungs-Cookie als auch über HTTP Basic Auth. Zugang zu einer Aktion verschaffen. Und das Tolle ist: wenn die Aktion nicht autorisiert ist, wird sowohl ein schickes Loginformular als auch ein HTTP 401 Unauthorized und ein WWW-Authenticate geschickt.
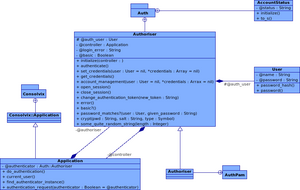
Nun sieht der Authentifizierungs-Prozess also folgendermaßen aus:
- Wenn der Aufruf mittels POST geschah und das Array params[:auth_user] vorhanden ist, wird also ein formularbasierter Login versucht -- mit diesen Daten wird eine Authentifizierung durchgeführt.
- Wenn ein Request mit HTTP Basic-Logindaten im Header ankommt, werden diese ausgewertet, sofern
core::use_http_basic_authwahr ist.
- Wenn kein gültiger User gefunden wurde (die Authentifizierung soweit also fehlgeschlagen ist), wird in der Session geschaut, ob dort ein authentifizierter Benutzer zu finden ist.
- wenn alles obige fehlschlägt, wird je nach dem ob
core::use_http_basic_authwahr oder falsch ist, einWWW-Authenticate-Header losgeschickt und gleichzeitig aber das Loginformular gerendert (dieses wird angezeigt, sobald ein Besucher die HTTP-Autorisierung abbricht). Ansonsten wird nur das Loginformular angezeigt. - wenn ein gültiger Benutzer gefunden wurde, wird fortgefahren mit der aufgerufenen Aktion.
- wenn alles obige fehlschlägt, wird je nach dem ob
Unabhängig davon, ob die Autorisierung über HTTP Basic oder Formular geschieht, wird immer der eingeloggte Benutzer in der Session gespeichert.
Ist core::use_http_basic_auth falsch, wird ein Logout in klassischer Weise über das Beenden der Sitzung und ein Redirect zum Login-Formular bewerkstelligt.
Bei HTTP Basic Authentication ist ein Logout bekanntlich nicht wirklich möglich. Deswegen wird beim Aufruf von /logout geprüft, ob noch eine Benutzer-ID in der Session steht. Wenn ja, wird die Session beendet und ein neuer HTTP Basic Auth.-Header gesetzt. Wenn nicht, dann muss die Session bereits beendet worden (und dies somit der zweite Aufruf von /logout) sein -- dann wird mit den neu eingegebenen Benutzerdaten ein neuer Authentifizierungsversuch gestartet und auf /index umgeleitet.
Unterm Strich kann man sich nun also sowohl formularbasiert als auch über HTTP Basic einloggen und zumindest aus der üblichen Benutzersicht auch ausloggen. Ob HTTP Basic (und später auch Digest-) Autorisierung verwendet werden soll, kann der Admin über die Weboberfläche festlegen.
Stay tuned. mehr im nächsten Post!