
Dieser Artikel ist auch auf Deutsch verfügbar
It is no secret that the three largest cloud providers are all based in the USA, which makes processing and storage of sensitive and personal data seem almost impossible due to the US Cloud Act [1]. In order to meet certain compliance requirements for data protection and information security during a cloud migration, part of the system therefore often remains in the company’s own on-premises data center. Another criterion for continuing to operate applications with inhouse infrastructure is incompatibility with the cloud-native paradigm. To avoid high migration costs or even a rewrite, legacy systems often remain in their own on-premises data center. Less critical and newly developed systems naturally find their way into the public or private cloud.
However, the more diversified and distributed the system is, the more complex it becomes to enforce compliance across all systems and platforms. As the IT organization grows, the challenges of effectively ensuring compliance across systems also increase.
Typical challenges in hybrid operating environments
In a historically evolved IT organization with hybrid operating environments, we often encounter the following stumbling blocks:
- Coordination of compliance measures across the IT organization, which is often split into different teams and products.
- Implementing and monitoring existing and future compliance requirements across different operating platforms and software domains.
- Ensuring data integrity and security during transfers between different operating environments.
- Ongoing management of sometimes complex access authorizations in a constantly expanding network of users and system components.
Architecture consulting and architecture reviews often reveal the following: The most pressing issues are not caused by the technology or the code quality, but rather by unsuitable processes and organizational barriers. This is particularly evident in the divergence between departments.
The natural evolution of an IT organization as it moves to the cloud often results in two separate organizational units. One is responsible for the legacy software and infrastructure, while the other one handles the more modern systems in the cloud. The exchange between these areas usually remains unnecessarily restricted due to the presumed profound differences. The result is a fragmented IT landscape in which synergies remain unused and valuable practical knowledge is rarely shared.
Especially smaller companies often fall prey to the deceptive assumption that compliance violations are a problem for the “big fish”. Believing in the principle that “nothing will go wrong” is not only naive, but also clearly negligent. Even smaller companies are not flying under the radar, as the GDPR alone affects many software products for end users. In addition to endangering the privacy of end users, carelessly ignoring data protection vulnerabilities can also jeopardize the reputation of the company and its managers. In many cases, it can even lead to notoriously severe fines. This is especially true when it comes to repeat violations, or if previous evaluations such as penetration tests and security reviews have clearly indicated vulnerabilities or if they were not conducted in the first place.
Simply ignoring the issue is not an option. Consequently, architects and developers need to consistently keep up with modern technologies and proven standard procedures. After all, regulations such as the GDPR demand that data protection is always based on the latest state-of-the-art technology. Although there is frequently updated guidance on the definition of this term [2] along with specific recommendations for action, there is no binding reassurance. This problem is also not resolved by working with auditors, because they usually do not support companies in the detailed implementation of these technical measures. In all actuality, they concentrate more on checking the documented procedures than on the actual implementation. Companies also often overlook that compliance requirements must already be considered during architecture design. The illusion that compliance is an appendage that can be retrofitted later is misleading. A targeted design that takes data protection and information security into account from the very beginning is crucial to avoid costly redesigns later on.
Especially among companies in less regulated industries, there is often a lack of understanding of the critical aspects of their own system that are worth protecting. Taking GDPR compliance as an example, the right to erasure (right to be forgotten) of personal data places high demands on the traceability of data streams.
A typical example is a master data application for customers that is operated in a cloud as well as on-premises. If this application stores personal data, it must be able to identify and irreversibly erase all data requested by a customer. If personal data is stored in different databases, caches, backups, and messaging brokers, complete erasure through manual intervention cannot be guaranteed.
Another problem could arise from the interoperability of the various system components, if data flows through several layers or services and ultimately continues to services like SaaS offerings that are difficult to monitor. An architecture design that considers data protection requirements from the beginning allows these types of data flows to be sensibly managed and monitored.
Furthermore, precise knowledge of the criticality of the processed data as well as the services and interfaces that depend on it provides a strong foundation for deciding which parts of the system can be outsourced to a public cloud (e.g. under US control). However, it is also crucial to assess the cost of a cloud migration. It comes as no surprise that many legacy systems are left in on-premises operating environments despite their low criticality. The effort is simply not worth it, despite the attractive benefits offered by cloud operation.
Effective measures
In addition to the usual practice of ensuring compliance in companies, in our experience, the creation of supportive team structures and the adaptation of software delivery and operating processes are among the most effective measures. This includes:
- Establishment of a federal compliance group
- Accessibility of global policies and automated enforcement
- Standardized software delivery pipelines and templates for all operating environments
- Automated self-service interfaces for hybrid operation with pioneer teams
These points are discussed in more detail below.
Federal compliance group
In addition to centrally controlled specifications, other stakeholders, such as security experts and architects, also place more specific demands on the development teams. Some of these requirements are not formulated in specific terms or there is no direct contact person for follow-up questions. Instead, the definition of such requirements is discussed in small circles, while development teams are not directly involved. If development teams were more involved here, their valuable professional and technical expertise would flow into the definition of requirements, which would ultimately lead to practical and implementable specifications.
If requirements remain unclear and vague, they will inevitably be interpreted and implemented differently by the development teams. To make matters worse, in a hybrid setup there are usually separate departments for on-premises and cloud development, which has a negative impact on coordination and information distribution. Therefore, it is important to improve communication and collaboration between the specialist department, legal department, decision-makers, and the development teams.
The data mesh concept addresses such challenges. Data mesh is not some sort of new technology. It is a decentralized socio-technical approach to data management that solves complexity issues through clear team responsibilities and interfaces. This principle can also be applied to IT organizations that lack a particular focus on data management.
A data mesh concept that has proven to be very successful involves the formation of a federated governance group in the form of a community or guild made up of representatives from the development teams, the specialist department, and the platform teams. This group coordinates regularly scheduled meetings and sets up communication channels where all stakeholders can ask questions and express concerns. If an equivalent group were to be set up for compliance needs, it would be supported by compliance experts or the legal department and other stakeholders. Such a community would build a necessary bridge between compliance, architecture, and development so that they can agree on specific architectural decisions, good practices, and global policies (Figure 1). To enforce global policies more effectively, automated policy management and monitoring is recommended for the data mesh concept. [3].
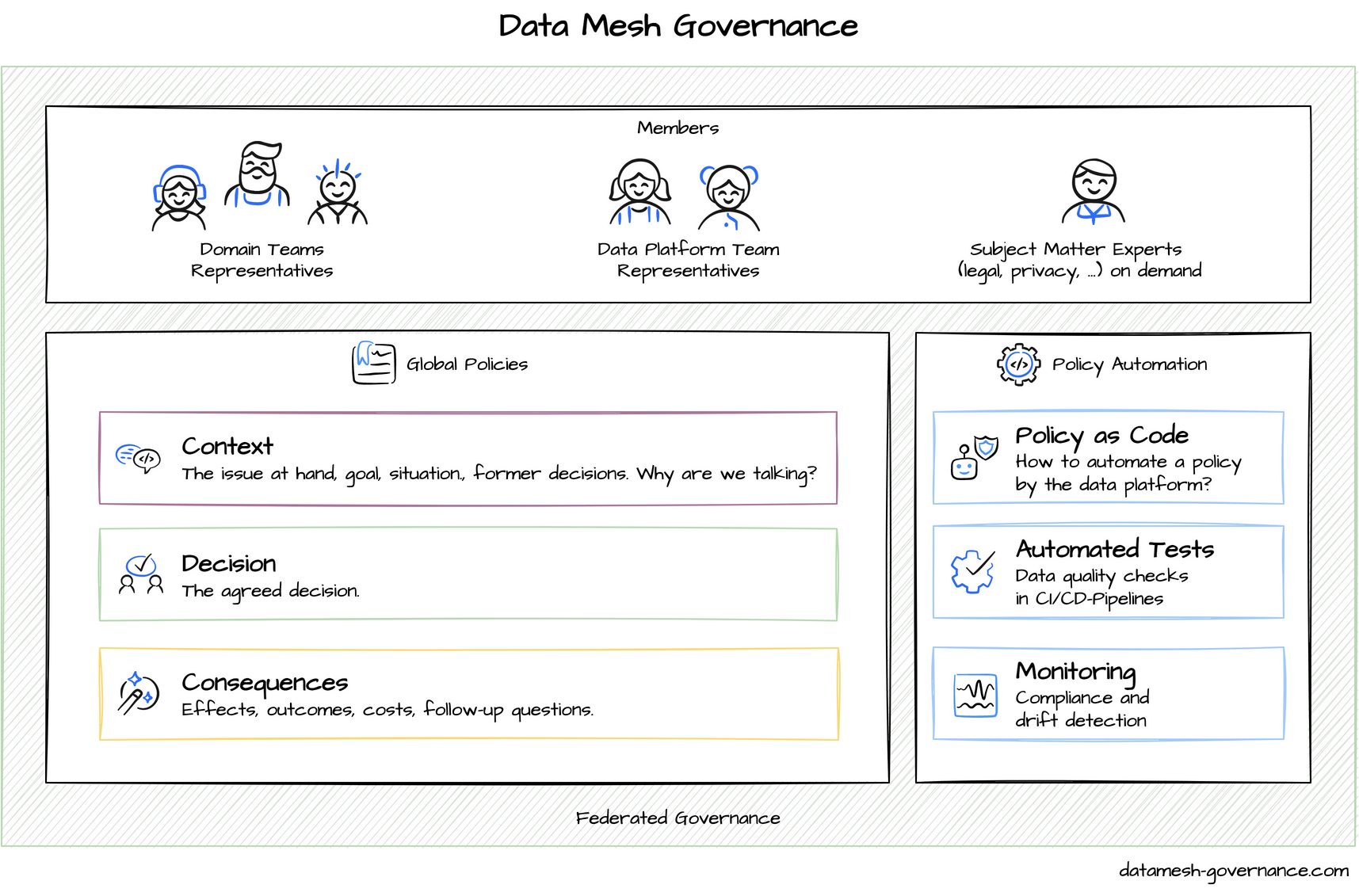
Automated policy management
The specific challenge in hybrid operating environments is that compliance requirements must be met for each platform and each location, possibly with varying legal situations. This increases the coordination effort and makes it harder to establish, monitor, and enforce compliance guidelines.
Public cloud providers offer well-integrated tools for monitoring, evaluating, and enforcing policies. However, these tools are often proprietary and cannot be used for other operating environments. For example, AWS Compliance & Auditing Services offer monitoring of resource configurations in addition to a standard audit log for people and service account activities.
These out-of-the-box features are often not available in an on-premises operating environment. Besides having to acquire the necessary expertise for this task, the applied tools and processes must be selected and adapted in a dedicated manner.
Descriptions of compliance requirements are often shared in wikis and requirements documents for communication with the implementation teams. Readme and configuration files, including code, then conceal the actual implementations or even additional specifications that are not documented elsewhere or result from the implementation according to the “state of the art”.
The data mesh concept recommends providing centrally managed, machine-readable policy descriptions (policy as code) that can be used automatically for validation and enforcement (automated policy enforcement).
One challenge that can hardly be avoided is that policies as code inevitably have to replicate existing compliance descriptions, since non-technical departments cannot realistically be expected to formulate their requirements in machine-readable formats and languages. Nevertheless, communicating the advantages can promote mutual understanding. Having said that, there are advantages to treating policies as code, since known principles of software development are used. Policies are thus testable and versionable using the typical means for code. Policies essentially represent configurations for a policy engine that handles the evaluation of rules (policy evaluation).
However, if companies use hybrid operating environments, however, they should limit themselves to a technology for describing and evaluating policies that is supported by all operating environments. This way, redundancies are avoided. It also makes it easier to migrate system components to a different operating environment (e.g. a cloud) at a later date.
The open source software Open Policy Agent(OPA) is an established tool. Contrary to what recent articles and presentations on this tool suggest, it is not limited to cloud environments like Kubernetes. There are undoubtedly more powerful policy engines. However, they are often strongly tied to a specific operating environment and are thus less suitable for a uniform standard in hybrid operation. By contrast, the Open Policy Agent can be integrated into the system landscape as a central service, concurrent process, or library. Therefore, it represents a flexible option for decentralized evaluation of policies regardless of the operating environment being used. Realistically, however, it may still be necessary to use additional tools for special policies, e.g. for inter-service communication.
Various policies can be defined in operational use, for example:
- Network policies: Similar to distributed firewall rules, they control the traffic flow between services based on metadata and topology.
- Limitation of permitted container image sources: These policies determine which base images and container registries are allowed in order to release only verified images for use (see code listing 1)
- Validation of metadata: Before deployment, mandatory metadata is checked, e.g. system criticality and data classification (data privacy level). Based on this validation, a decision can be made as to whether deployment in a specific operating environment with specific requirements (such as latencies, licenses, or certifications) is permitted.
- Prohibition of privileged container rights: To reduce the risk of security vulnerabilities, policies prevent containers from being operated with excessive privileges.
- Resource limitation: Used to limit access to resources and prevent improper use.
violation[{"msg": msg}] {
container := input.review.object.spec.containers[_]
satisfied := [good | repo = input.parameters.repos[_] ; good = startswith(container.image, repo)]
not any(satisfied)
msg := sprintf("container <%v> has an invalid image repo <%v>, allowed repos are %v", [container.name, container.image, input.parameters.repos])
}Code Listing 1: Open Policy Agent Gatekeeper – Constraint template for permitted container registry. Source: Open Policy Agent Gatekeeper Library
Policy engines can also be used outside the operating context. Policies on configurations or the structure of system documentation can be validated early in the development process. [4]. It is only necessary for a process to perform automated validations. This can be easily implemented in a pipeline that obtains global policies from a central OCI registry or an object store. Signing and versioning are used to ensure the trustworthiness of the derived policies.
Standardized software delivery processes
Besides the use of central policies for operation and automated evaluation in code and documentation pipelines, the use of a uniform software delivery pipeline for all operating environments of a hybrid setup is a tried-and-tested strategy. A large part of the necessary quality, security, and supply chain analysis processes often take place in software delivery pipelines. However, standardizing the software delivery pipeline also means that supporting team structures, such as a platform team, are required to maintain and tweak a uniform software delivery pipeline description.
The decision not to develop the software delivery pipeline centrally and not to make it mandatory makes sense, because it gives the development teams more freedom during implementation. However, experience shown that, although team-owned pipelines tend to be better adapted to the team processes, they often contain outdated software versions and policies. Organizations with high compliance requirements are therefore better advised to offer a consolidated and centrally managed software delivery pipeline as a service to development teams. This service can include providing the necessary infrastructure and managing templates for different types of applications. Focusing on the development teams as customers increases the likelihood of acceptance and continuous expansion of the pipeline to meet their needs.
Platform engineering as a service
A common struggle for development teams in regulated industries seems to be deployment capabilities. Not every one of these organizations wants to immediately introduce a continuous deployment workflow where a production deployment is triggered for every code change, no matter how small. Nevertheless, an independent deployment capability after a release is essential for fast feedback cycles, e.g. feedback from customers for new features and fixes, or simply feedback from the system that a deployment has failed due to incorrect configuration. The smaller and more frequent deployments are, the easier troubleshooting is.
However, there are often deployment processes for the production environment where deployment and operation must be carried out by a separate operations team. Consequently, the development team is not allowed to deploy to the production environment or run their own services. The headaches caused by these deployments are no secret, but they are accepted on the grounds that it is done for compliance reasons and cannot be implemented any other way. (Example: Separation of functions between incompatible tasks from the IT baseline protection module ORP.1.A4)
The underlying strategy is that tighter monitoring and separation of responsibilities between development and operations teams minimizes risks to the production environment. However, this strict separation is only a simple solution to the problem of minimizing risk for fear of being found to be non-compliant during audits of the operating concept. However, implementing the most restrictive possible configuration of existing regulations in order to be “on the safe side” is not the critical factor. Companies would be doing themselves a great favor by adopting a risk-oriented approach at this point. Measures should be aligned with the company’s objectives. This way, measures are created that are appropriate for the respective context and are not driven by a maximum need for security.
Potential corporate goals in this context:
- Fast time-to-market through efficient software delivery processes
- Simplified hiring and more flexible deployment of employees thanks to lower expertise requirement
- Greater employee satisfaction thanks to shorter waiting times and fewer blockages
By creating a true self-service operating platform, development teams are empowered to take over the operation of their own services without having full access rights to the production environment. Even the differentiation of the underlying operating environment can be abstracted to such an extent that only a tag in the metadata of a deployment manifest represents an indicator and the actual operating environment remains completely hidden from the development teams.
Example of Heroku as a self-service platform
Heroku is a prime example of a highly abstracted application platform whose underlying infrastructure cannot be accessed by users. This platform offers application deployments, the use of various persistence products, comprehensive monitoring, and many other complementary services that are easy to use. Obviously not every company has the resources to build a Heroku clone. However, investing in a more abstract platform can be worthwhile to free yourself from the fear-driven shackles that make software development in highly regulated industries so stressful. It’s also worth assessing whether many features, e.g. for policy enforcement, can already be covered by existing tooling.
Kubernetes is rightly described as a complex monster. However, it is undeniably a good tool for building a self-service platform without getting stuck in years of inhouse development. It comes with preinstalled features for policy validation and enforcement and can be easily expanded using selective inhouse developments or Kubernetes-native open source software.
Another consideration point for hybrid operating environments that should not be underestimated is that Kubernetes can run on many platforms. This means that it offers a standardized operating interface despite different operating environments.
A highly abstracted self-service platform has key advantages:
- Uniform, decentralized, and automated enforcement and monitoring of applied policies
- Compliance “by design” for cross-sectional services such as logging and access control as a preventive and supportive control system
- Self-service operation by the development teams leads to rapid response times in the event of incidents and promotes ownership.
Practice has shown that the separation of development and operational responsibility does not automatically lead to secure operations. It is not uncommon for companies to have all-powerful operations teams that are able and allowed to do everything, but do not always handle this power prudently.
This happens quite naturally when an operations department is installed as a central bottleneck. The resulting high workload prompts them to take shortcuts. People are allocated to authorization groups that only require approximately similar authorizations. Consequently, they are given too much power.
The configuration of firewall rules is also often a tedious manual task that often requires several iterations. Therefore, it comes to no surprise that lax settings tend to be made here to prevent a mountain of tasks from piling up. All of these developments are understandable and are symptomatic of the fact that the development teams are placing too many restrictions on autonomous operation.
The first step on the path to a self-service platform is to set up an organizational unit for platform engineering. This new department differs from an operations department because a self-service platform is developed as a service. It should be regarded as an internal product whose users at least consist of the development teams [5]. This platform can be used by the development teams voluntarily in the initial implementation phases, but it could eventually become the standard procedure for operations. Renaming the operations department will not be enough, because the typical way of continuing to maintain a ticket-based order placement principle will remain, with the prospect of delegating more and more business activities to the development teams via the self-service platform.
Pioneer teams
A tried-and-tested strategy is to start a self-service platform with one or a few pioneer teams in order to pursue user-oriented development. Similar principles apply here as for normal product development. These pioneer teams are development teams that will migrate their applications before the general availability of the new operating platform.
The pioneer team and the platform team work in close collaboration. The focus is on product development that is distinguished by its direct, continuous exchange with the users, which in this case is the pioneer team. This leads to practical feedback and ensures that platform development is geared towards real requirements.
- Teams that have to meet especially low or complex compliance requirements
- Teams that have particularly low or high operational requirements
- Teams that greatly benefit from improved delivery performance
- Newly established teams that lack historical exposure to the operations
- High-performing teams, due to low workload or extensive cross-functional expertise
Instead of trying to create a platform that is as complete as possible using Heroku as an example, the objective is to prioritize the features that promise the greatest benefit to the development teams in a targeted and needs-based manner. In specific terms, this means that development begins with core functions that solve acute problems, such as independent configuration of firewall rules. This functionality can be implemented through mechanisms such as pull requests and subsequent code reviews by the platform team. It can also be implemented through user-friendly interfaces (such as graphical user interfaces) that facilitate automated validations based on global policies in the background.
A special aspect of platform development with a pioneer team is the support of the pioneer team during the migration process. The focus here is on promoting independent usage of the new platform, which is a key prerequisite for effective ownership later on. An important byproduct should be concise, easily accessible product documentation to facilitate independent onboarding by the pioneer team and subsequent development teams. Detailed descriptions of the platform architecture should not be explicitly required for use. They belong in the architecture documentation for the platform team.
The assumptions underlying the platform development should be evaluated no later than right after successful migration of the pioneer team’s services. At this point, it is important to assess aspects such as the improvement of feature turnaround times, the simplification of debugging and troubleshooting, and the effectiveness of policy enforcement. A regularly scheduled review of these key figures shows progress in relation to the underlying business objectives. This evaluation does not have to be fully automated. In practice, quarterly evaluation through value stream mapping sessions, surveys, and manual transfer of key figures from ticket systems and CI servers has proven to be sufficient.
Pioneer teams also play a crucial role in the process of establishing new platforms, because they can contribute to greater credibility, transparency, and confidence building. Their experience and opinions carry particular weight with other development teams within the organization. By sharing their experiences with the platform (for example, at internal conferences), they indirectly become ambassadors for platform use by reporting on its benefits as well as its challenges. A platform engineering department continues to act as a control body for the infrastructure, just as an operations department did previously. It ensures that binding rules are automatically enforced and that specifications are implemented in operations. Despite the development teams’ aspirations for autonomy, the underlying infrastructure remains an essential backbone by providing the necessary infrastructure such as policy engines (see: Governance through Infrastructure by Gregor Hohpe [6]). The benefits of delegating responsibilities to development teams remain unaffected. They can continue to collect domain-specific requirements in their own sphere of influence and elaborate corresponding policies in a federated compliance group.
Experience shows that the need for support for development teams initially increases during the transition to a new platform before the desired independence of the users and the associated reduction in support costs happens. Clearly delineated support structures should be defined to reduce the risk of overworking the platform engineering department. According to the Team Topologies concept, the formation of “enabling teams” or “traveling experts” is suitable for this purpose. This support team structure offers support and coaching for a defined service area, such as:
- Support with database and resource configuration
- Support with the test and delivery pipeline
- Support with threat modeling and derivation of policies
- Support with incidents
Summary
Compliance is not a bureaucratic end in itself. Legal requirements, such as those of the GDPR, primarily serve to protect end users. Damage to corporate reputation, fines, and the personal liability of decision-makers are immediate risks that should be considered. In an effort to effectively address these challenges, this article has presented various technical and organizational measures and concepts that help satisfy compliance requirements in hybrid operating environments:
- Establishing a federated compliance group that simultaneously pools expertise, distributes information, and promotes cross-divisional collaboration.
- Making global guidelines transparent, coupled with automated enforcement
- Developing standardized software delivery pipelines and templates as a supporting and monitoring tool
- Providing automated self-service offerings for operations and centralized policy control and validation
- Deploying pioneer teams for needs-based implementation of centrally controlled measures
-
GDPR and Cloud Act: Legal risks associated with transferring data to the USA ↩︎
-
The Software Architect Elevator, p. 267: Hohpe Gregor. 2020. The Software Architect Elevator: Redefining the Architect’s Role in the Digital Enterprise (version First edition) First ed. Sebastopol California: O’Reilly Media. ↩︎