
Dieser Artikel ist auch auf Deutsch verfügbar
When companies migrate to the cloud, they often have a clear vision of the desired infrastructure and software architecture. This usually involves:
- Choosing a cloud provider for managed infrastructure and services
- Implementing Kubernetes for better abstraction and improved collaboration between platform and developer teams
- Using provisioning tools like Terraform to automate infrastructure management and deployment
- Incorporating variant management tools like Helm or Kustomize to deploy different versions of the same application to various environments (e.g., dev or prod)
- Adopting a DevOps work model
- Optionally, implementing GitOps
Typically, the admin team is responsible for delivering this platform, and the final result may look similar to this.
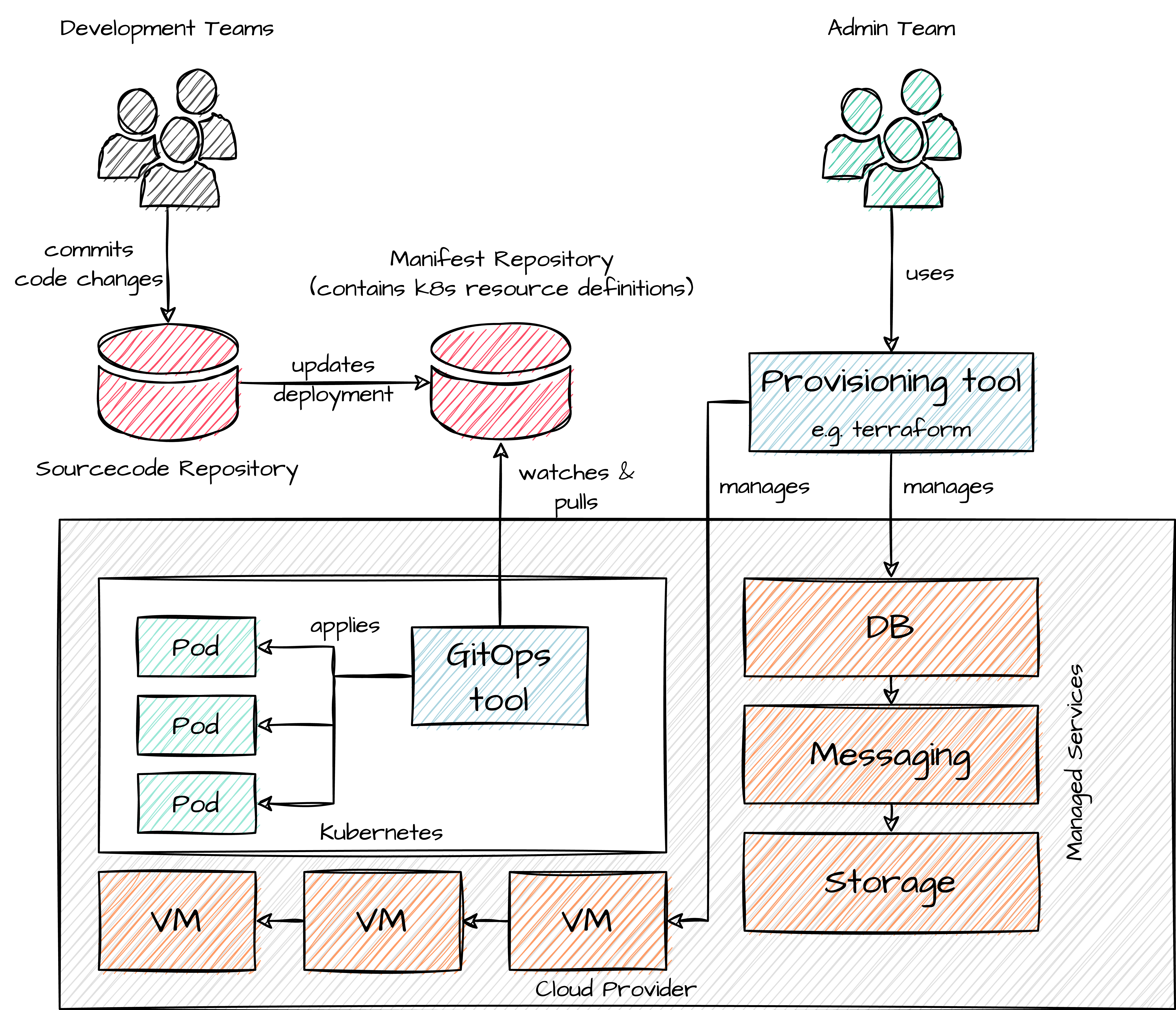
This is a very simplified view. Additionally, there will probably be tools for monitoring, logging, documentation, and API specification. Other teams like quality, security, and testing are also involved and are added to the mix with their demands and wishes.
Once the platform is ready to use and handed over to the development teams, the company expects the development teams to jump happily on the bandwagon, to embrace the new possibilities and responsibilities and magically become more productive and agile.
Why development teams may not accept the new way?
In reality, the acceptance by the software development teams is probably very slow or teams are reluctant to adopt the new way. Is it not a dream that everybody can have end-to-end responsibility, working with cool new technologies like Kubernetes and Container Runtimes and using new architectural patterns like microservices?
There are probably several reasons why that’s not the case.
New responsibilities are scary
If a development team previously “only” had the responsibility for building the software and another team took care of the operation, now having the responsibility for operational and security constraints can be daunting. It is no longer sufficient to write well-structured, maintainable code; teams must also be knowledgeable about application performance and how it meets operational and security requirements.
The traditional division between software development and operations is not without flaws (first and foremost: the broken and unreliable feedback loop and different goals which lead to regular conflicts) but this is where most teams start from and have a comfortable area of expertise. With increased responsibility, there is a higher likelihood of making mistakes. Depending on the failure and governance culture, this can result in a reluctance to take on new responsibilities.
Too many new tools and paradigms
The good intention of introducing Container Technologies and Kubernetes is to have a better interface to bring software into operation. This is better than having a written manual with instructions that could be misinterpreted or could contain failures. Developers are, however, not used to defining operational aspects in this detail for their applications. It is not only the Kubernetes terminology to learn, but also:
- How to define operational aspects like requests and limits for the application, or a good set for replicas
- How to monitor the application or provide good metrics for them
- How to use and configure the monitoring system to provide insights into the application
- How to provide tracing capabilities and how to build cross-application visibility
- How to use variant management/packaging tools like helm or kustomize
- How to set up the development environment to have a cloud similar environment, probably with tools to simulate local clusters or managed services like kind or localstack
- How to build well-defined, small, secure container images
- How to follow best practices for container images
- How to set up a repository structure to allow a GitOps workflow
The expectation is that with Kubernetes and all the necessary tools in place, developers no longer have to worry about operational tasks and can focus exclusively on business objectives, leaving the platform to manage everything else. However, in practice, the development process in such an environment can be significantly different, to the point where a subset of the team members may need to focus solely on configuring and optimizing the tools. Depending on the size or number of teams, this could become a burden that developers try to avoid.
Based on the cognitive load theory by John Sweller, if we map it to software development, the introduction of new technologies, tools, and paradigms increases the extraneous load and takes away the focus from the part that matters for the team: the domain complexity and domain problems to solve.
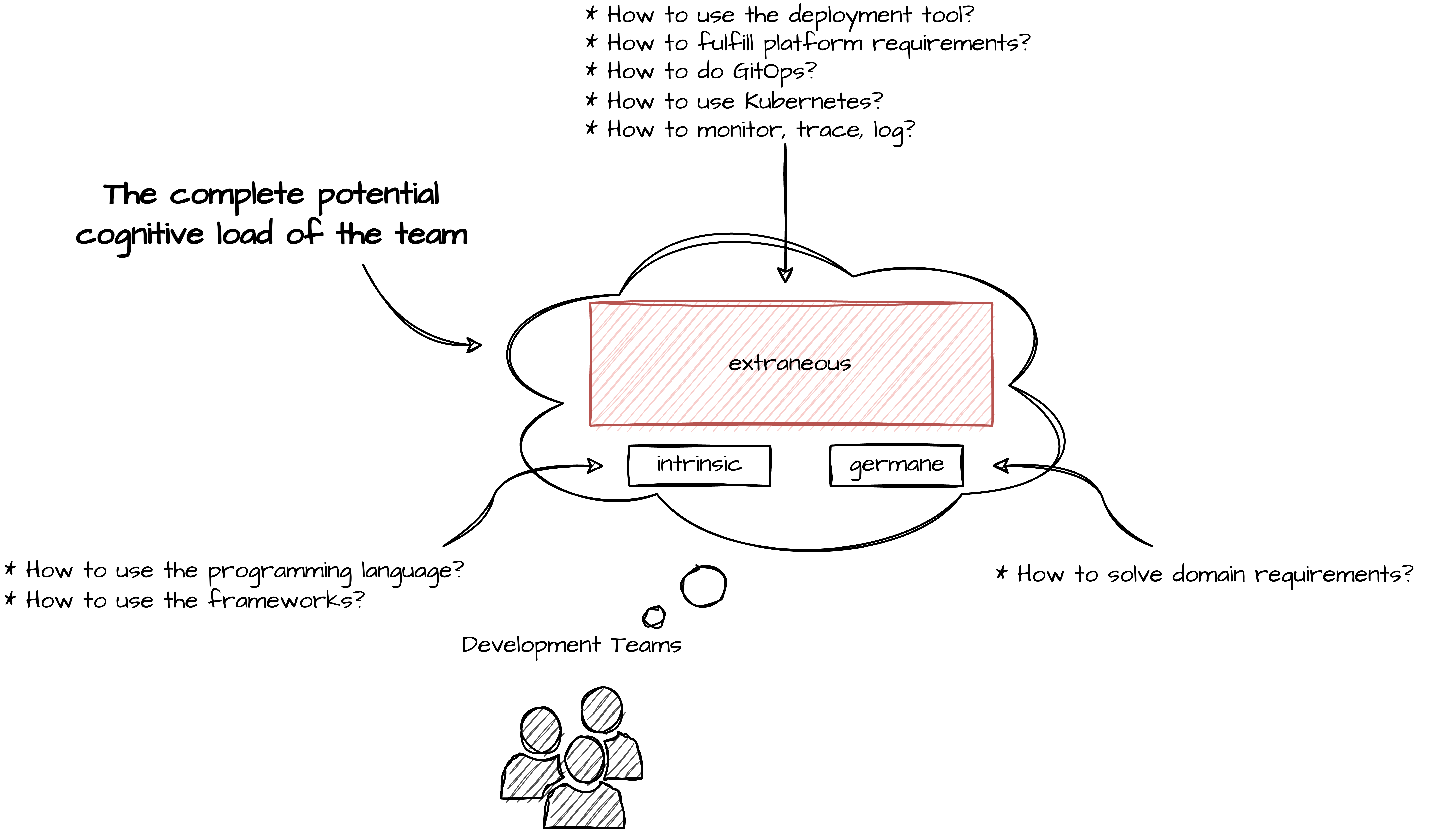
Discoverability and Ownership
In a complex environment where several teams are working on several services, most platforms lack discoverability and ownership. Typical questions that are raised and can’t be answered are:
- What services are running on our platform?
- What is the purpose of the service, and where can I find the fitting documentation and API description for it?
- Which team owns this particular service?
- Are there libraries or images which are used by all teams to ease e.g. some operational, security, or visibility constraints?
- How are services linked to each other?
- Which services use external services like managed databases?
This information can be found in every development environment but is thinly spread all over the place. Some information can be found live on the platform, while others are spread over wikis, documents, repositories, or in the worst scenario, inside the head of some developers and admins. Keeping an overview for the development teams is quite hard.
Tools are not solving organizational processes
Just because the tools allow a continuous deployment, does not mean it happens automatically. Traditionally, different teams have had the responsibility for specific parts of the deployment, like testing, release management, and security checks. These are not always technical teams, but are more focused on documentation and processes to be fulfilled. But to go in the direction of continuous deployment, these steps have to be automated. As the non-technical teams probably cannot provide this automation and may additionally feel uncomfortable giving away responsibility and trust into code only, they may search for a way to map the traditional processes to the new paradigms, which leads to fuzzy, process-oriented demands on the development teams. The requirements from the past for processes and documentation are now reflected in the build and delivery pipelines. Development teams have the feeling of using the new tools not as intended, so they can play out their strengths, but to use them to please the processes which were always there. It feels like selling old wine in new bottles, suppressing motivation and innovation.
A paradigm shift does not just happen because of the correct tooling alone.
Wrong focus on automation
The way to a better developer experience is to automate everything and provide self-services to the development teams. Most of the time, however, the self-services lack a view of the development flow as a whole. The teams’ responsibilities are focused on classic disciplines like security, operation, and development and may have an impact on tool choice and setup.
So starting the automation from here can lead to very tool-focused automation. Every team will provide self-services for their part, probably in different ways. One team provides automation via a self-service portal, the next via tickets, and another maybe via pull requests.
When we look from a development team perspective, the demand is more on higher level self-services. These self-services need to simplify the whole process for the following processes:
- “What do I have to do to get a new service live?“
- “What do I have to do to provide a new library to other teams”?
With too fine-grained self-services, they have to understand which of them are needed to fulfil these tasks, so the overarching knowledge of all self-services and how they are connected sticks to the development team. It adds to the cognitive load already increased by all the new tools.
Self-Service and automation alone do not automatically simplify and improve the development cycle if it is not focused on a common goal.
Kubernetes is not the best abstraction for developers
Kubernetes had a huge impact on our understanding of how we want to operate software, similar to the Cloud. It abstracts operational concepts and provides us with a way to express them in declarative form. It provides us with the possibility to define all parts of our application such as load-balancing, placement, routing, and scaling as we see fit in the form of resources. If we want to run a stateful application we have to create a StatefulSet, Service, PersistentVolumeClaim, Ingress resource, and maybe many more. We can define everything, but it lacks a focus on the application itself and is not completely developer-friendly. Additionally, it is error-prone, and Kubernetes does not provide any guidance on how to implement best practices in the first place. This isn’t compelling for development teams that just want to focus on developing features. It can be exhausting, even if rewarding, to build up profound knowledge in Kubernetes.
Kubernetes is a platform for building platforms. It's a better place to start; not the endgame.
— Kelsey Hightower (@kelseyhightower) November 27, 2017
We‘d love to show you a tweet right here. To do that, we need your consent to load third party content from twitter.com
Kubernetes is the engine of the platform, not the platform itself. So it is meant to build better abstractions on top for development teams to be able to more easily consume and focus on what has to be managed by the developers. In most platforms, this idea is under-represented and leaves the teams to find their way how to deal with the new possibilities.
Imbalance between the abundance of developers and the relative scarcity of operational experts
The DevOps approach tries to bring development and operational experts closer together, in the best case to work together in one team. The same is true for other teams like testing or quality teams. Organizations try to follow DevOps by implementing SRE as described by Google. But as we often have to admit, we are not Google. Rarely are we working in an environment that is as engineering-focused as Google. Most of the time we are in an organization that attempts to modernize its internal development process and has fewer operational experts than people with development expertise. So being a copycat of the development and operational concepts of Google without having the same organizational constraints leads to unsatisfactory results and demotivated teams.
Platform Engineering as a new approach
Platform Engineering tries to tackle some of these gaps to make the migration to self-sufficient teams easier. Platform Engineering understands all processes and tools as a support for development teams to get things done and out of the door. The goal of the platform engineering team is to solve obstacles and ease operational needs for the development teams. It hides the complexity and interdisciplinary of actions and measures behind a common offer to the development teams: the platform.
It is not only an organizational change, but we expect some qualities to come with it.
Treat your platform as a product
As products for the end customer, the platform shall be understood as a product for the developers. It means that the offering is an option and can be ignored by development teams if it does not fulfil their needs or solve their issues. So, as with any other product competing in a market, it has to understand the needs of its customers and win them over. Of course, in reality there is no second option, but it is still an important driver to focus on developer needs and not to build a platform to be an over-engineered playground of platform teams’ technical desires for personal fulfillment. Every task, every automation, and every improvement is focused on making the software delivery better, quicker, safer, or more stable.
Additionally, handling it as a product means working continuously on the platform and improving it. It is not finished, as there are always new ideas that have to be reflected by the platform, e.g. new vulnerabilities, new tools, new approaches, new bug fixes, etc…
Build transparency
The platform shall provide transparency about the platform offerings but also the ownership and existence of software artifacts and their dependencies. There has to be a central place to gather all the information available in all the different places to get an overview, to make environments with hundreds of services and libraries manageable.
A lot of the time, we would discuss some kind of developer portal as a main entry point for every development team, which gives us a starting point.
A possible product for a platform to provide this capability is Backstage, which gains traction lately.
Higher level self-services
Self-services shall solve development needs and shall not be tool-centric. So self-services are not:
- Setting up a new repository
- Setting up a new build and deploy pipeline
- Setting up a new runtime platform for the service
They shall be focused on the whole development flow:
- Setting up everything needed to build a new library
- Setting up everything needed to bring a new service into production
- Provide all the needed infrastructure together with the new service
- Bake in all best practices into a service had to interact with the runtime platform (integration with observability stack and sane defaults for resource demands and placement) → some kind of automated service templates to start from
It shall improve the daily work of the development teams. The platform team has to find the balance between abstraction and flexibility of the tooling without losing the comprehensibility of what happens behind the curtain.
The platform shall simplify the 90% common feature has to improve the acceptance and ease the team’s reluctance, but shall not prevent a possible divergence from the golden path.
Automate and shift-left governance
In every organization, we have an explicit or implicit understanding of what makes software ready for production. This materializes in the form of quality gates, processes, or manual checks. These constraints are probably located in different areas, like:
- Functional acceptance (does the software provide all the functionality we expect and does it correctly)
- Quality (does the software fulfil our quality standards by checking code constraints or architectural constraints)
- Test coverage (is the software well-tested)
- Operational constraints (does the deployment fulfil all best practices defined by the platform team like placement and resource usage needs)
- Security constraints (does the software contain any vulnerabilities not allowed in production, does it fulfil all security best practices?)
These tasks are traditionally either done manually or at least with manual interaction and checks, and are part of a release process that may lack quick feedback. For example, that the deployment does not fulfil all operational constraints may happen in the very last stage before deployment, which makes the whole process slow and complicated.
The platform shall always have the idea of continuous deployment in mind when building up the tooling. So it means it shall automate everything on the way, but at the same time, it shall give quick and early feedback to development teams, meaning a shift-left as much as possible to not wait until the very last moment to tell that a quality gate may break.
Even if other constraints and regulations prohibit a real continuous deployment to the production environment, the mindset of both the development and platform teams shall make it at least technically possible.
Does it solve all our problems?
Like any other approach, Platform Engineering is not a silver bullet. Simply adopting new processes, ideas, and tools is insufficient if the organization is resistant to change and wishes to maintain old structures. Platform Engineering may highlight silo thinking by revealing friction between team goals, but it does not automatically resolve these issues. A willingness to embrace change and prioritize continuous improvement as an organizational mindset is critical. The danger of Platform Engineering is that it may end up merely attaching a new label to old processes and structures, attempting to force-fit the old organization into a new idea, much like how many companies now claim to be agile. Without the proper mindset and organizational framework, Platform Engineering may ultimately develop the same negative connotation as any other “new” approach.