

This article is also available in English
Die Hypertext Application Language HAL ist eine offene Spezifikation, um die Repräsentationen von RESTful-Ressourcen zu strukturieren. Dazu werden JSON und XML um einen neuen Hypermedia-Typ erweitert. Der initiale Entwurf stammt von Mike Kelly aus dem Jahr 2011 und ist somit schon lange keine Neuheit mehr. Er kommt bereits in vielen API-Projekten zum Einsatz und wird in diversen Artikeln diskutiert. In den letzten Jahren haben wir eine mittelgroße API entwickelt, die komplexe Daten-Ressourcen in einem weltweiten Unternehmensverbund bereitstellt.
Anstatt für die Entwicklung wie so oft die neueste Technologie zu wählen – und auch inspiriert durch das Richardson Maturity Model – sind wir mit HAL als bewährte und ausgereifte Technologie einen pragmatischen Weg gegangen. Im Laufe des Projekts wurden API und Services in mehreren Lebenszyklen entwickelt. Dabei hat das Projektteam für eine auf HAL basierende Architektur viel Praxiserfahrung bei der Konzeption, der Entwicklung, den Betrieb und den Knowledge-Transfer gesammelt.
Grundlagen zu HAL und HATEOAS
Wie bei den meisten Technologien, die schon eine Weile existieren, gibt es online zahlreiche Dokumentationen und Tutorials. Aufgrund dessen begnügt sich der Artikel mit den relevanten Grundlagen. Im Kern ist HAL ein Hypermedia-Format, mit dem sich JSON- oder XML-Repräsentationen verknüpfen lassen. Dabei springen zwei Konzepte ins Auge: das teilweise oder vollständige Einbinden anderer Ressourcen in die Ressource selbst und die formale Verlinkung zu anderen Ressourcen.
Jede HAL-Repräsentation enthält demnach eine Map _links, um von der Ressource ausgehend weiter zu navigieren, und eine optionale Map mit _embedded-Ressourcen, die wiederum _links enthalten – beispielsweise den sogenannten self-Link, unter dem die vollständige Ressource zu finden ist. Die API-Konsumenten konnten sich so auf die angebotenen, zustandsbehafteten Links konzentrieren und blieben unabhängig von fest codierten URIs oder internen IDs. Dabei halfen ihnen bewährte Tools (z. B. in Spring HATEOAS) oder es wurde in Teilen selbst entwickelt.
Die Links einer Ressource lassen sich über ihren Relationsnamen zuordnen und semantisch belegen. Dabei greift HAL auf einen etablierten Standard (RFC 8288) zurück – wie self für die aktuelle Ressource oder previous/next für seitenweises Blättern in einer Listen-Ressource. Diese allgemeinen Relationsnamen kommen somit nur für die grundsätzlichen API-Funktionen zum Einsatz. Für benutzerdefinierte Erweiterungen – in der Sprache der Domain – erlaubt die IANA Registry die Verwendung von Uniform Resource Identifier (URI) als Relationsnamen, die gleichzeitig auf die Dokumentation der Relation verweisen sollen. Für eine Kundenverwaltung beispielsweise könnte ein Link zu allen Bestellungen des Kunden hilfreich sein.
{
"name": "Jon Doe",
"_links": {
"self": {
"href": "http://example.com/customer/123"
},
"http://example.com/rels/customer-orders": {
"href": "http://example.com/customer/123/orders"
}
}
}Das Curie-Konzept (compact URI) hilft dabei, die sperrigen URI-Relationsbezeichner durch einen zweiteiligen Alias für eine parametrisierbare URI zu ersetzen. Im folgenden Beispiel würde die rel=ex:customer-orders auf die Dokumentation in http://example.com/rels/customer-address zeigen:
{
"name": "Jon Doe",
"_links": {
"self": {
"href": "http://example.com/customer/123"
},
"ex:customer-orders": {
"href": "http://example.com/customer/123/orders"
},
"curies": [
{
"href": "http://example.com/rels/{rel}",
"name": "ex",
"templated": true
}
]
},
"_embedded": {
"ex:customer-orders": [
{
"orderNumber": "123ASDF",
"shippingAddress": "Ohlauer Str. 43, 10999 Berlin",
"_links": {
"self": {
"href": "http://example.com/customer/123/orders/ASDF"
},
"ex:customer": {
"href": "http://example.com/customer/123"
}
}
}
]
}
}Domänenspezifische Relationen lassen sich nicht nur als Link-Bezeichner zum Navigieren der Ressourcen nutzen, sondern auch um andere Ressourcen direkt einbinden (etwa bei Eltern-/Kindbeziehungen). Zum Beispiel könnte die fiktive OrderResource eine CustomerAddressResource einbinden und in einem Response an den Client senden – und so das Extra-GET über den rel=ex:customer-address-Link überflüssig machen.
Begonnen haben wir dabei mit statischen Links, dann mit zustandsbehafteten und später – motiviert durch Feedback und tatsächliche Notwendigkeit – hat es die Links verfeinert und die Ressourcen gleich mitgeliefert. Dank des simplen Designs von HAL waren diese Erweiterungen immer transparent und auf Konsumentenseite nur durch die Anzahl der GET-Requests für einen Navigationspfad zu unterscheiden.
Pragmatismus statt Dogmatismus bei der Entwicklung
Im Laufe des Projekts wurden die Module des Systems in mehreren Zyklen mit Frameworks wie Dropwizard, Rails, Grails, Ktor und zuletzt Spring Boot entwickelt. Auf der Makroebene hat sich das Projektteam frühzeitig auf HATEOAS und den Einsatz von HAL/JSON für Architektur und Standards der API festgelegt.
Entwicklung und Betrieb einer HTTP-API, selbst wenn es nur für eine relativ überschaubare Anzahl bekannter Konsumenten ist, hält neben den technischen auch organisatorische Stolpersteine bereit. Unter anderem hat sich während des Projektverlaufes der Begriff API-Hygiene etabliert, denn funktionale und nichtfunktionale Anforderungen trafen aufeinander und die Clients drängten auf eine „in ihren Augen” richtige Lösung. Der Entwicklungsprozess glich oft einem Spagat bei dem Versuch, die Anforderungen pragmatisch und schnell zu erfüllen und das richtige Augenmaß beim Befolgen der REST-Prinzipien für eine zukunftsfähige Architektur zu finden. Es folgen ein paar Beispiele, die zeigen, wie diese Gratwanderung aus Pragmatismus und Dogmatismus im Laufe des Projekts bewältigt wurde.
Distinkte Filterwerte für Listen-Ressourcen
Für eigentlich alle Listen-Ressourcen des Projekts bietet die API über Query-Parameter zusätzliche Filteroptionen an. In Anlehnung an den obligatorischen self-Link finden sich zwei weitere Relationen mit templated-Links in der Response, vorausgefüllt für den aktuellen Filter. Dadurch konnten Anwender und technische Clients weitere Drilldowns auf der Listen-Ressource durchführen. Einer der Links führte zu einer neuen Aggregations-Ressource, die ähnlich wie ein group by in SQL, mögliche Filterwerte (auch min/max und ranges) in Buckets anbietet und so leere Suchergebnisse vermeidet.
{
"_embedded": {
"ex:planes": [
{
"_links": {
"self": {
"href": "http://example.com/planes/123"
}
},
"makeName": "CESSNA",
"modelName": "Skycatcher",
"modelYear": 2018,
"trimLevel": "PERFORMANCE",
"wingCount": 5
}
]
},
"_links": {
"self": {
"href": "http://example.com/planes?makeName=CESSNA&modelName=Skycatcher&modelYear=2018"
},
"ex:planes": {
"href": "http://example.com/planes?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore,sort,page,size}",
"title": "PLANES (Collection)",
"templated": true
},
"ex:planes_agg": {
"href": "http://example.com/planes-agg?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore}",
"title": "PLANES_AGG (Aggregation)",
"templated": true
}
}
}Die Aggregations-Ressource bietet wieder zwei templated-Links, um zur originalen Suchanfrage (Listen-Ressource) zurückzukehren oder weiter auf der Aggregations-Ressource zu filtern. Durch diese parametrisierbare Verknüpfung der beiden korrespondierenden Ressourcen war es Clients möglich, komplexe Workflows abzubilden.
{
"_links": {
"self": {
"href": "http://example.com/planes-agg?makeName=CESSNA&modelName=Skycatcher&modelYear=2018"
},
"ex:planes_agg": {
"href": "http://example.com/planes-agg?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore}",
"title": "PLANES_AGG (Aggregation)",
"templated": true
},
"ex:planes": {
"href": "http://example.com/planes?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore,sort,page,size}",
"title": "PLANES (Collection)",
"templated": true
}
},
"makeName": [
"CESSNA"
],
"modelName": [
"Skycatcher"
],
"modelYear": [
2018,
2017
],
"country": [
"GER",
"USA",
"CHL"
],
"trimLevel": [
"ALLTRACK",
"PERFORMANCE",
"DELUXE EDITION"
]
}Massenhaft Zuordnungen ändern über einen Endpunkt
Während des Entwicklungsprozesses traf das Projektteam mehrmals Entscheidungen oder wählte Abkürzungen, mit denen es zunächst nicht glücklich war, die sich aber als die pragmatischste Lösung herausstellte. Eine der Anforderungen war, dass ein zentraler Administrations-Client für eine große Anzahl von Ressourcen Batch-Operationen ausführen können soll. Dieser Client bietet Workflows, die durch einen einzelnen Klick im User Interface (UI) Hunderte von Ressourcen ändern – etwa die Zugehörigkeit zu einem Elternknoten.
Gleichzeitig wollten die Projektbeteiligten keine Client-spezifischen Endpunkte oder komplexe Transfer-Ressourcen einführen und es mit der bestehenden, uniformen API in Einklang bringen. Für derartige Sonderfälle wurden die REST-Grundregeln dezent ignoriert und eine Relation-Ressource (ohne Payload und Mediatype) entwickelt, die die Ressourcen-IDs im URI Template erwartet und nur PUT- und DELETE-Operationen kennt. Im nachfolgenden Beispiel ist das für den Link rel=ex:model-planes zu sehen.
{
"_links": {
"self": {
"href": "http://example.com/models/123"
},
"ex:planes": {
"href": "http://example.com/planes?modelId=123"
},
"ex:model-planes": [
{
"href": "http://example.com/models/123/planes/{planeIds}",
"title": "MODEL has PLANES",
"name": "modelHasPlanesTemplated",
"templated": true
},
{
"href": "http://example.com/models/123/planes/1,2,3,4,5",
"title": "MODEL has PLANES",
"name": "modelHasPlanes"
}
],
"curies": // …
}
}HTTP-Methoden in den HAL-Links
Die Spezifikation von HAL-Links bietet erst einmal keine Mittel, um herauszufinden, welche Mediatypes im Einsatz sind und welche HTTP-Methoden – zusätzlich zu GET – für eine bestimmte Ressource erlaubt sind. Um das zu erfahren, sind zusätzliche OPTIONS- und HEAD-Requests nötig, was in der Praxis jedoch nur selten so implementiert wird. Stattdessen wird das oft hart kodiert, etwa indem Entwickler initial die Swagger-Dokumentation oder gar den API-Quellcode heranziehen.
Spring HATEOAS bietet mit der Affordances API einen ausgereiften Ansatz, um nach HTTP-Methoden getrennte Endpunkte unter einem Relationsnamen zu bündeln. Im Standard-HAL-Mediatype ist zunächst keine Veränderung sichtbar (weiterhin nur die GET-Relation gemäß Konvention) – dazu ist eine Erweiterung wie HAL Forms nötig, die zu einem aufgeblähten LinkObject führt. Im Rahmen des Projekts hat man sich für einen einfachen Weg entschieden und das Original LinkObject um ein benutzerdefiniertes methods-Attribut erweitert. Dazu haben wir ausgehend vom URI-Pfad der GET-Relation – mit Java reflection (cached) und Projektkonventionen – die Spring Endpunkt-Annotationen @PutMapping und @DeleteMapping ausgewertet und auf diese Weise das methods-Attribut befüllt.
{
"_links": {
"self": {
"href": "http://example.com/customer/jon-doe",
"title": "Jon Doe (age 30)",
"methods": ["GET", "PUT"]
}
},
"name": "Jon Doe",
"birthday": "1990-01-01"
}Relationen als Einstiegspunkte für die Dokumentation
Die Dokumentation der API ist ebenso wichtig wie die API selbst, gerade dann, wenn die API wie im vorliegenden Fall in einem komplexen Konsumenten-Ökosystem genutzt wird. Häufig kommen dazu Definitionssprachen wie Swagger/OpenAPI, RAML oder Blueprint zum Einsatz. Sie werden damit über die dazugehörige Software-Tools-Dokumentation für Menschen generiert. Gute Beispiele dafür sind Swagger UI und Redoc – basierend auf der OpenAPI-Spezifikation. Es ist erwähnenswert, dass sich viele dieser Dokumentations-Tools nahtlos in die API integrieren lassen, zum Beispiel durch Client-Rendering.
Anfänglich haben wir auf Swagger/OpenAPI gesetzt und das dort mögliche Tagging im Quellcode von Endpunkten als Bindeglied zu den Relationen verwendet. Obwohl das Tool die Erstellung und Pflege der Dokumentation vereinfachte, hat es durch den Fokus auf URIs und Endpunkte – statt Links – den Hypermedia-Vorteil von REST kompromittiert. Im Laufe der Zeit zeigte sich, wie API-Konsumenten die angebotenen Relationen ignorierten und Annahmen trafen, die auf dem Lesen von URIs und dem daraus resultierenden „vermeintlichen Verständnis” basierten. In jüngerer Zeit hat man sich deshalb dafür entschieden, URIs und interne IDs in der Dokumentation zu verstecken und Swagger UI durch den HAL Explorer, ein generisches Tool zur Exploration HAL-basierter APIs, zu ersetzen.
Für die API wurde ein angepasster Dokumentationsansatz gewählt. Zum einen wurden Profile-Ressourcen (siehe ALPS JsonSchema) für alle exponierten Modelle (Repräsentation) eingeführt und zum anderen Relations-Ressourcen erstellt, über die es Details wie Endpunkte, Mediatypes, Status-Codes und Extra-Markdown für Architectural Decisions (ADRs) zu erfahren gab. Diese beiden Ressourcen-Typen hat das Unternehmen miteinander verknüpft und in einem Relationen-Register als Start-Ressource der API bereitgestellt.
<h1>Documentation for rel='planes'</h1>
<div id="deprecation">
<h2>Deprecation</h2>false
</div>
<div id="description">
<h2>Description</h2>
<h3>PLANES (Collection)</h3>
<p>Lorem Ipsum Lorem Ipsum Lorem Ipsum …</p>
</div>
<div id="endpoints">
<h2>Endpoints</h2>
<ul>
<li>GET http://example.com/planes{?makeName,modelName,modelYear,...,sort,page,size}</li>
<li>POST http://example.com/planes</li>
</ul>
</div>
<div id="profiles">
<h2>Profile (Schema)</h2>
<ul>
<li><a href="http://example.com/profile/PlaneResource">PlaneResource</a></li>
</ul>
</div>{
"type": "object",
"id": "urn:jsonschema:com:example:resource:PlaneResource",
"description": "Profile for com.example.resource.PlaneResource",
"properties": {
"links": {
"type": "array",
"items": {
"type": "object",
"$ref": "urn:jsonschema:org:springframework:hateoas:Link"
}
},
"urn": {
"type": "string",
"readonly": true
},
"country": {
"type": "string",
"code": [
"GER",
"USA",
"CHL"
]
},
"makeName": {
"type": "object",
"$ref": "urn:jsonschema:com:example:NameValue"
},
"modelName": {
"type": "object",
"$ref": "urn:jsonschema:com:example:NameValue"
},
"trimLevel": {
"type": "object",
"$ref": "urn:jsonschema:com:example:NameValue"
}
}
}{
"_links": {
"self": {
"href": "http://example.com/planes/123"
},
"ex:planes": {
"href": "http://example.com/planes/"
},
"profile": {
"href": "http://example.com/profile/PlaneResource",
},
"curies": "…"
}
}Dieses Konstrukt funktioniert wunderbar mit dem HAL-Explorer, wie in Abbildung 1 zu sehen ist. Jede Link-Relation wird über das docs Icon zu ihrer Dokumentation verlinkt, dabei wird der Curie-Kennzeichner automatisch in die entsprechende URI übersetzt.
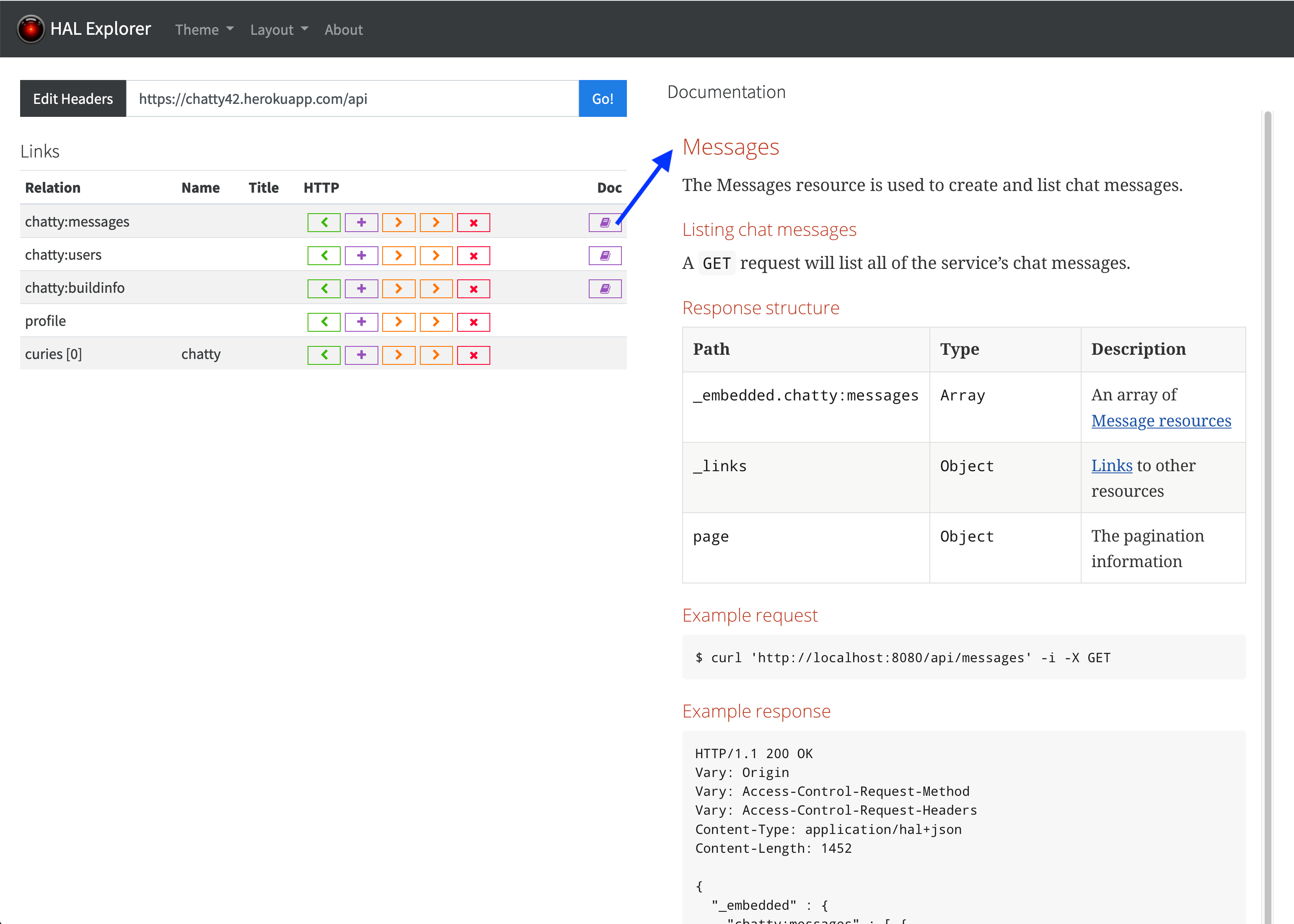
Relationen als Abhängigkeit im Client
Wir haben auch mehrere Konsumenten des Backends entwickelt. Der vermutlich komplexeste Client war ein Administrations-Tool. Es war dazu gedacht, die Daten der ETL-Prozesse noch mit weiteren Informationen anzureichern oder zu korrigieren. Die Anzahl der Nutzer:innen war naturgemäß klein – die Anforderungen dafür höchst dynamisch – sie wuchsen nahezu organisch mit den jeweils neu hinzukommenden Daten.
Eine Annehmlichkeit beim Einsatz gereifter Technologien ist die große Verfügbarkeit von ebenfalls ausgereiften Tools und Open-Source-Bibliotheken zur Implementierung der Clients. Hauptsächlich eingesetzt wurde Traverson, eine Hypermedia-API beziehungsweise ein HATEOAS-Client für Node.js, um über die HAL-Links zu navigieren. Traverson bietet eine Fülle aneinanderreihbare Methoden, um von einer Start-Ressource ausgehend nur über Relationen durch die API zu navigieren. Ein typischer Request sieht daher wie folgt aus:
const childList = await traverson
.from("http://example.com")
.withRequestOptions(apiRequestHeaders)
.jsonHal()
.newRequest()
.withTemplateParameters({ parentId })
.follow("ex:planes", "ex:models")
.getResource()
.result;Unter der Haube holt sich Traverson die Start-Ressource und durchsucht diese nach der URL für die Relation ex:planes. Sofern die Relation wie im Beispiel templated ist, werden die parentId eingesetzt und die finale URI zusammengebaut. Die zurückgelieferte Ressource des Requests wird dann nach ex:models analysiert. Ein weiterer GET-Request folgt, um das Ergebnis zu holen. Die Verwendung von Labeln und Verkettung von Aufrufen hat das Finden und Lesen von Ressourcen stark vereinfacht und die Kohäsion von API und Konsumenten auf das Notwendigste reduziert. Die eindeutigen Relationsbezeichner machten den Client unabhängig von der eingesetzten Umgebung und vereinfachten die Auffindbarkeit in der Codebasis, was vor allem bei Änderungen im Backend schnelles Feedback möglich machte.
Ausblick
Es gibt viele Alternativen zu HAL, die unserer Meinung nach alle zu viel „geschwätziger” Kontrolle über das finale Ausgabeformat greifen (siehe Siren, UBER, Collection+JSON) und dann letztlich nicht so viel Mehrwert bieten.
Bei HAL bleibt der Kern der Ressource bestehen und lässt sich nach Belieben erweitern. Alle URI-Änderungen passieren hinter den Kulissen und solange die Relationen und ihre Semantik bestehen bleiben, muss clientseitig nichts angepasst werden. Und dort, wo Änderungen nicht vermeidbar waren, ließ sich die Deprecation-Information auf einem Standard HAL-Attribut mitteilen und die Relation später entfernen. Theoretisch hätten die API-Clients niemals URIs selbst erstellen oder manipulieren müssen und somit einen häufigen Fehler vermeiden können.
Die größte Hürde beim Einsatz von HAL ist sicherlich organisatorischer Natur, denn HAL ist nichts weiter als eine Konvention und hängt allein vom Commitment der Leute im Projekt ab. Denn es verlangt nach viel Disziplin der Entwickler, nicht von den HAL-Konzepten abzuweichen und nach Abkürzungen zu suchen. Diese Herausforderung zeigte sich zu Projektanfang und auch später bei personellen Wechseln, allerdings ist die Lernkurve flach und das Design der API gut verständlich. HAL ist sicherlich nicht perfekt für REST-APIs, jedoch fanden sich immer Wege, es zu erweitern, ohne dass die vielen Vorteile oder das grundsätzliche Konzept von HAL verloren gingen.