
Um die Vorteile und Herausforderungen von Microservices zu verstehen, muss der Begriff „Microservice“ definiert werden. Das bieten die ISA-Prinzipien (Independent Systems Architecture). Die wichtigsten Prinzipien sind:
- Microservices sind nur eine andere Art von Modulen. Sie stehen also in Konkurrenz zu anderen Modularisierungsvarianten wie Java Packages oder JARs.
- Microservice-Module sind als Docker Container oder beispielsweise als Serverless-Funktionen umgesetzt.
- Bei der Implementierung von Microservice gibt es viel mehr Freiheiten. So kann jeder Microservice in einer anderen Programmiersprache geschrieben sein. Daher gibt es zwei Ebenen von Architektur: Die Makro-Architektur umfasst alle Entscheidungen, die alle Microservices beeinflussen. Die Mikro-Architektur sind hingegen die Entscheidungen, die nur einen Microservice beeinflussen. Diese Unterscheidung ist wichtig, weil erst durch Microservices so viele Freiheiten entstehen, dass eine Mikro-Architektur sinnvoll ist.
- Jeder Microservice hat eine eigene Continuous-Delivery-Pipeline. Sonst geht ein wesentlicher Vorteil von Microservices verloren, nämlichen das unabhängige Deployment.
Die ISA-Prinzipien definieren noch weitere Eigenschaften, die aber für diesen Artikel keine Rolle spielen. Microservices bieten durch diese Prinzipien Vorteile in verschiedenen Bereichen.
Organisatorische Vorteile
Der erste Bereich ist die Organisation. Das erscheint zunächst merkwürdig, denn schließlich sind Microservices „nur“ eine Architektur. Aber Architektur hat eben Auswirkungen auf die Organisation.
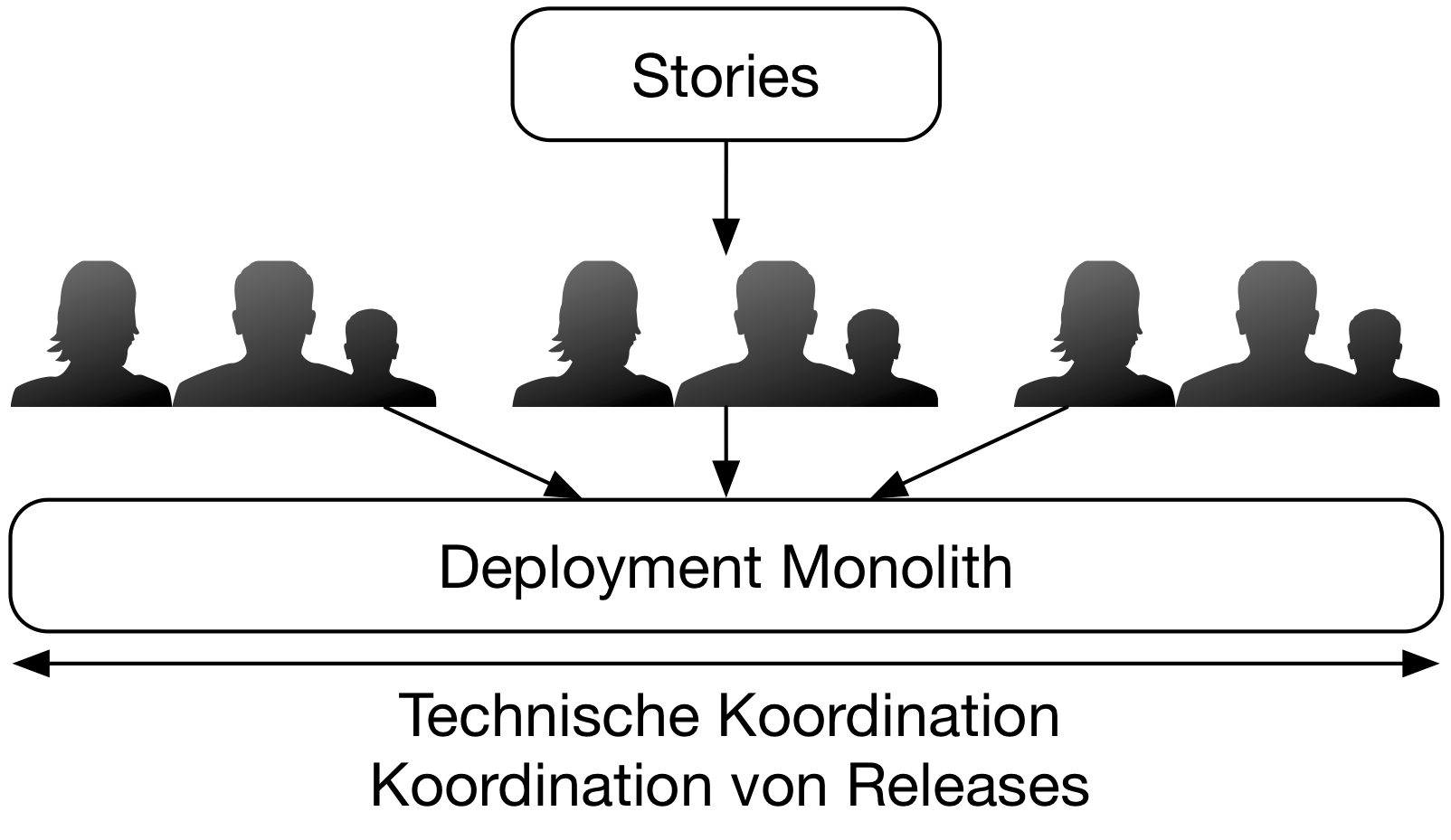
Die Alternative zu Microservices ist ein Deployment Monolith, in dem alle Module zusammen deployt werden. Es ist nicht möglich, ein Feature in einem Modul zu implementieren und dann nur dieses Modul zu deployen. Also muss das Deployment koordiniert werden: Alle Module müssen in einer Version vorliegen, die tatsächlich sinnvoll deployt werden kann. Außerdem muss der Deployment Monolith eine gemeinsame technische Basis haben – z.B. die Java Virtual Machine oder eine bestimmte Programmiersprache. Im Falle von Java müssen alle Bibliotheken in nur einer festgelegten Version vorhanden sein. Das erfordert, dass alle Module mit diesen Bibliotheksversionen umgesetzt sind und dass diese technische Basis auch mit allen Teams koordiniert wird (siehe Abbildung 1).
Im Gegensatz dazu können Microservices einzeln deployt werden und jeweils andere technologische Entscheidungen umsetzen (siehe Abbildung 2). Die technologischen Entscheidungen müssen nicht unbedingt dazu führen, dass jeder Microservice in einer anderen Programmiersprache implementiert ist, aber beispielsweise kann ein Team eine neue Version einer Library mit einem Bugfix ausliefern, ohne dass die anderen Microservices beeinflusst werden. Durch Microservices werden die Teams also unabhängiger. Insbesondere ich keine Koordinierung bei den Deployments mehr notwendig. Das macht beispielsweise den Release Train aus dem SAFe Framework zur Skalierung von agilen Prozessen überflüssig, weil Releases und Deployments eben nicht mehr koordiniert werden müssen, und erleichtert so das agile Vorgehen auch in großen Projekten.
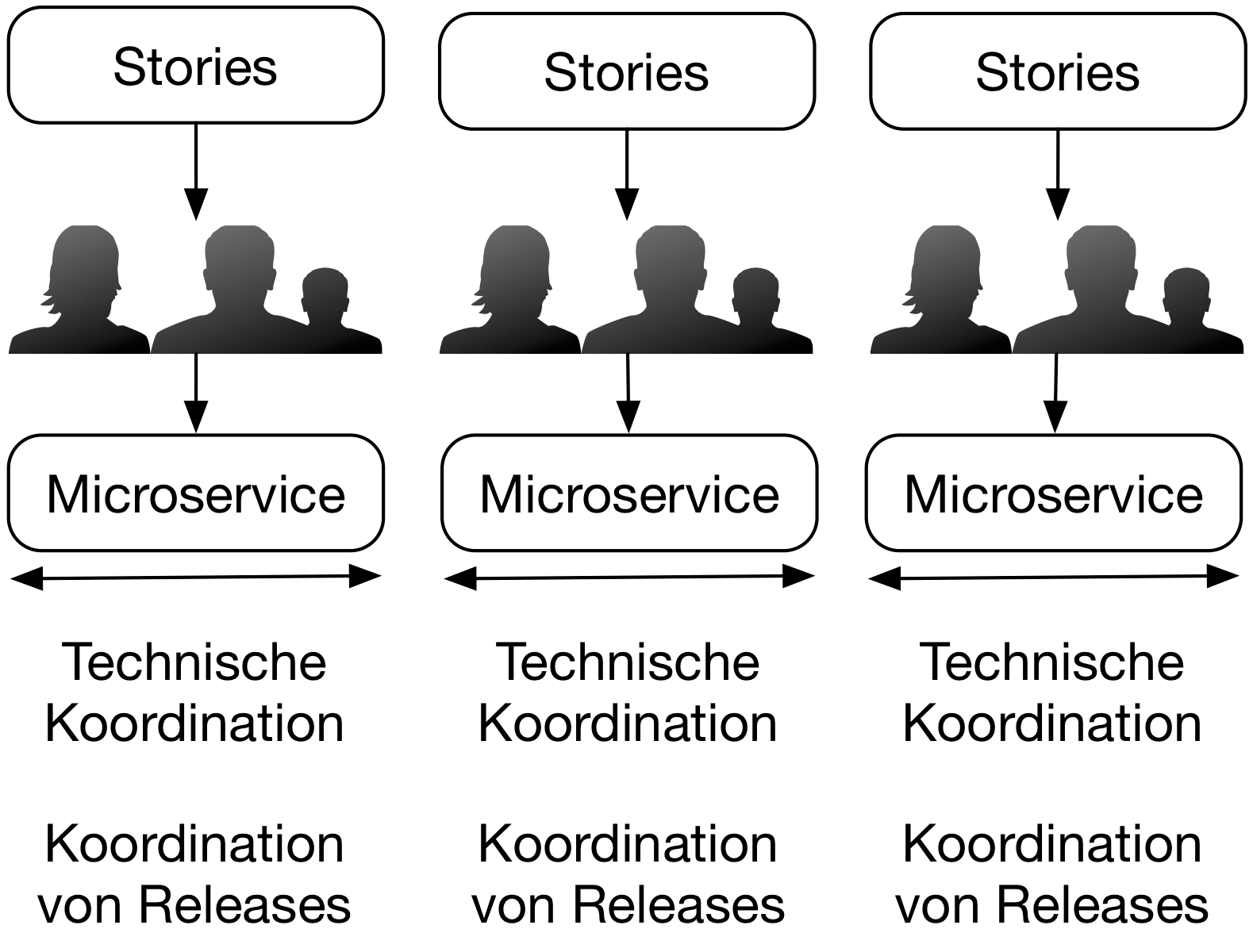
Die Microservices sollten idealerweise jeweils einen Bounded Context implementieren. Das ist ein Teil der Fachlichkeit, der ein eigenes Domänenmodell hat. So kann es in einem ECommerce-System den Lieferprozess geben. Das Domänenmodell für den Bounded Context Lieferprozess kennt beispielsweise Lieferadressen oder die Größen und Gewichte der Waren. Für die Rechnungslegung muss das Domänenmodell hingegen die Preise, Steuern und die Rechnungsadressen kennen. Die Domänenmodelle bilden jeweils einige Use Cases vollständig ab. Daher kann oft eine Fachlichkeit durch Änderung von nur einem Bounded Context umgesetzt werden. Wenn der Bounded Context in einem Microservice implementiert ist, kann er unabhängig von den anderen Bounded Contexts und Microservices deployt werden. So entsteht eine große fachliche Unabhängigkeit: Ein Feature verursacht Änderungen an einem Bounded Context, der in einem Microservice implementiert ist, so dass die Änderungen mit nur einem Deployment in Produktion gebracht werden können.
Durch Microservices entsteht also ein hohes Maß an technischer Unabhängigkeit und durch Bounded Context ein hohes Maß an fachlicher Unabhängigkeit, so dass die Teams sich selbst organisieren können. Letztendlich erlaubt die Microservices-Architektur es, ein großes Projekt in mehrere kleine, unabhängige Projekte aufzuteilen, was beispielsweise den Kommunikationsaufwand und die Risiken reduziert.
Technische Vorteile
Auf technische Ebene haben Microservices ebenfalls zahlreiche Vorteile:
- Module sollten entkoppelt sein. Bei klassischen Modulen bedeutet Entkopplung, dass eine Änderung an einem Modul die anderen Module nicht beeinflusst, so dass die Module unabhängig weiterentwickelt werden können. Microservices bieten Entkopplung auch auf anderen Ebenen: Technische Entscheidungen und Deployment hat der Artikel schon erwähnt. Auch die Skalierbarkeit kann pro Microservice erfolgen. Und wenn ein Microservice ausfällt, laufen die anderen weiter, so dass auch ein Ausfall isoliert ist. Schließlich können die Microservices beispielsweise durch Firewalls gegeneinander isoliert werden, was die Sicherheit erhöht. So bieten Microservice eine Entkopplung auch in ganz anderen Bereichen als nur Entwicklung wie klassische Module das tun.
- Für die Architektur haben Microservices den Vorteil, dass die Module klar voneinander abgegrenzt sind. Wären die Module hingegen Java Packages und keine Microservices, so kann eine Abhängigkeit zwischen Modulen sich sehr schnell einschleichen. Es ist nicht immer klar, aus welchem Package die gerade benutzte Klasse kommt und ob man dieses Packages wirklich in der aktuellen Klasse nutzen darf. Microservices haben hingegen beispielsweise REST-Schnittstellen. Es ist also offensichtlich, wenn ein Microservice einen anderen Microservice nutzt und wenn eine neue Abhängigkeit eingeführt wird. Der Entwickler sollte sich dann Gedanken machen, ob diese Abhängigkeit wirklich aus der Architektur-Perspektive sinnvoll ist. So entsteht eine Art Architektur-Firewall, denn neue Abhängigkeiten sind nicht so leicht einzuführen.
- Wenn ein Microservice nicht mehr wartbar ist, kann er neu geschrieben werden. Dazu kann auch eine andere Programmiersprache genutzt werden, so dass das Neuschreiben ein kleines Greenfield-Projekt ist. Bei einem Deployment Monolithen wäre die Implementierung des neuen Moduls an die technischen Entscheidungen der anderen Module gebunden – beispielsweise bezüglich Programmiersprache und Framework. Das mach oft eine enge Integration notwendig und erschwert die Ablösung einzelner Module erheblich.
- Schließlich kann jeder Microservice getrennt deployt werden. Eine Continuous-Delivery-Pipeline für einen einzelnen Microservice umzusetzen, ist viel einfacher als für einen Deployment Monolithen. Der Microservice ist technisch weniger komplex, kann schneller und einfacher deployt werden und schließlich implementiert der Microservice nur wenige Features, so dass viel weniger Tests notwendig sind. Ab einer bestimmten Deployment-Geschwindigkeit ist die Aufteilung in Microservices alternativlos, weil Deployment Monolithen so groß und kompliziert sind, dass selbst bei einer vollständigen und effizienten Automatisierung von Tests und Deployment ein Deployment mehrmals pro Tag unmöglich bleibt. Wenn der Monolith wochenlang getestet wird und das Deployment einen Tag dauert, dann ist es unrealistisch anzunehmen, dass Deployments mehrmals pro Tag möglich sind.
- Auf technischer Ebene ergeben sich die Vorteile also vor allem dadurch, dass Microservices eine wesentliche Eigenschaft von Modulen verstärken, nämlich die Entkopplung. So können nicht nur Teams unabhängiger arbeiten, sondern Microservices auch einzeln neu geschrieben werden und getrennt deployt werden, was Continuous Delivery vereinfacht.
Herausforderungen
Natürlich bieten Microservices auch neue Herausforderungen:
- Da es viel mehr deploybare Artefakte gibt, steigt der Aufwand im Betrieb. Dem muss man mit einem hohen Maß an Automatisierung und einer passenden Microservices-Infrastruktur begegnen. Allerdings ist es zumindest für den ersten Microservice noch nicht notwendig, eine vollständige Microservices-Umgebung aufzubauen. Aber natürlich ist es ab einer bestimmten Anzahl von Microservices unmöglich, die Microservices ohne Optimierungen im Betrieb in Produktion zu halten.
- Microservices haben getrennte Datenbank-Schemata und kommunizieren über das Netzwerk miteinander. Daher können die Daten der Microservices nicht gemeinsam in einer Transaktion geändert werden. Also treten zwischen den Microservices Inkonsistenzen auf. Wichtig ist die fachliche Aufteilung der Bounded Context: Wenn die Bounded Context Rechnungslegung und Lieferprozess als Microservices ausgeführt sind, dann wäre eine Inkonsistenz nur zwischen Rechnungslegung und Lieferprozess möglich. Konkret könnte es für eine Bestellung eine Rechnung aber noch keine Lieferung geben oder es gibt keine Rechnung aber eine Lieferung, weil die Information über die Bestellung noch nicht bei allen Microservices angekommen ist. Die Daten zur Rechnung oder Lieferung sind aber konsistent. Sie liegen jeweils in einem Microservice. Inkonsistenzen gibt es aber nur zwischen den Microservices. Da die Inkonsistenzen zudem nur vorübergehend sind, sind sie meistens akzeptabel. Probleme treten dann auf, wenn abhängige Nachrichten sich überholen: Wenn die Stornierung eintrifft, aber die Bestellung selber noch gar nicht angelegt ist, wird die Stornierung vermutlich ignoriert. Kommt dann die Bestellung doch noch an, kann es passieren, dass sie ausgeliefert wird, obwohl sie eigentlich storniert sein sollte.
- Die Microservices sind wie schon erwähnt sehr gut gegeneinander isoliert, so dass Architektur-Verstöße schwierig sind. Das bedeutet aber auch, dass eine komplette Umstrukturierung des Systems über alle Microservices hinweg schwierig ist. Ein solcher grundlegender Umbau ist aber immer schwierig und weist auf ein fundamentales Architektur-Problem hin. Darauf zu optimieren, dass man mit einem solchen desaströsen Architektur-Fehlschlag umgehen kann, erscheint wenig sinnvoll. Außerdem ist die Aufteilung in Bounded Context meistens sehr stabil.
- Wenn es zwischen den Microservices viele Abhängigkeiten gibt, kann der Ausfall eines Microservice dazu führen, dass auch alle abhängigen Microservices ausfallen und schließlich das gesamte System ausfällt. Daher müssen Microservices resilient sein: Sie dürfen nicht ausfallen, wenn ein anderer Microservice ausfällt. Natürlich können die Microservices ihre Features einschränken oder Fehlermeldungen erzeugen. Auf jeden Fall müssen Fehlerkaskaden vermieden werden, die zu einem Ausfall des Gesamtsystems führen.
- Schließlich geht die Einführung von Microservices mit zahlreichen neuen Technologien einher: Microservices-Framework, Docker, Kubernetes, Monitoring, Logging und vieles mehr. Aber wie schon angemerkt können die Technologien schrittweise eingeführt werden. Es ist nicht notwendig, eine Infrastruktur für hunderte Microservices aufzubauen, wenn nur einige wenige zunächst betrieben werden sollen.
Ansätze für Microservices
Wie schon erwähnt, sollten Microservices nach Bounded Contexts aufgeteilt sein. Aber einige Projekte wählen andere Ansätze. Beispielsweise teilen sie die Microservices nach Schichten auf (Abbildung 3): Auf der untersten Schicht sind Persistenz-Microservices, die alle Daten für ein Domänenobjekt wie einen Kunden enthalten. Darauf setzt dann eine Schicht mit Logik-Microservices auf, die zum Beispiel den Bestellungsprozess implementiert. Dann gibt es noch eine UI, die ebenfalls in einem Microservice umgesetzt ist oder beispielsweise eine Single Page App oder eine mobile Anwendung ist.
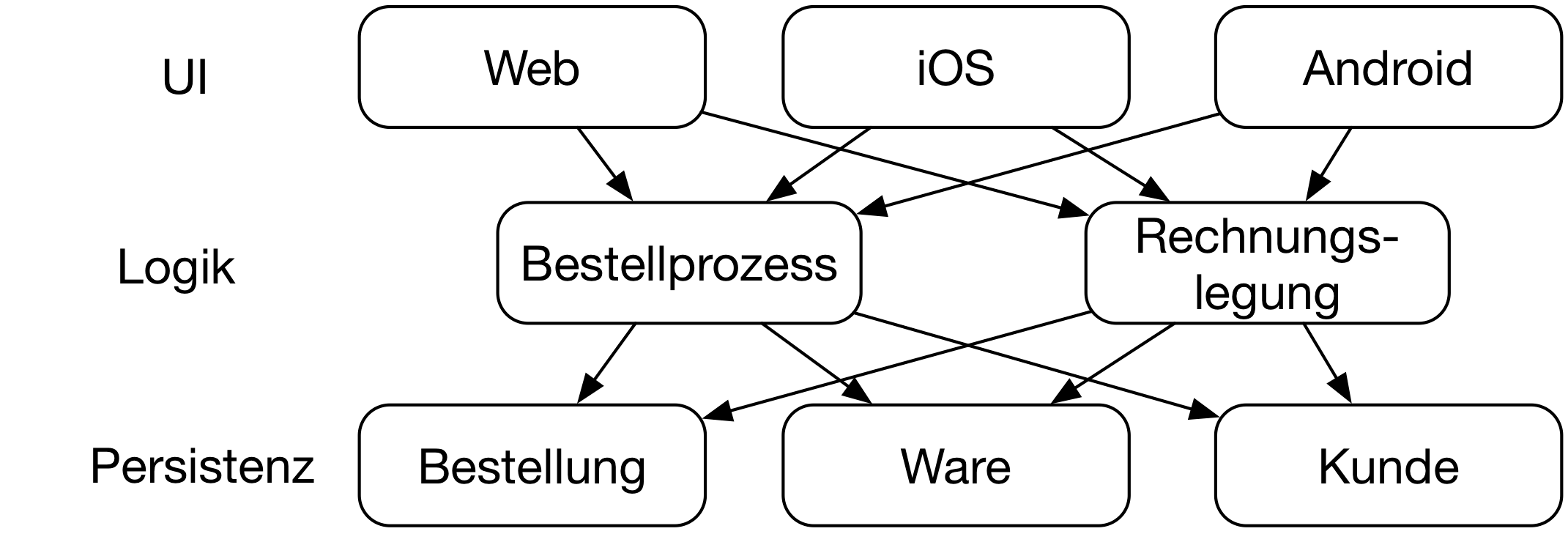
Ein Problem mit dieser Architektur ist, dass sie sehr viel Kommunikation benötigt: Von der UI müssen die Aufrufe an die Logik-Microservices gehen. Die Logik-Microservices rufen dann Persistenz-Microservices auf und zwar mehrfach, weil die Geschäftsprozesse typischerweise unterschiedliche Domänenobjekte aus unterschiedlichen Persistenz-Microservices benutzen. Die Kommunikation muss synchron sein, weil die Geschäftsprozesse direkt auf die Daten zugreifen und sie ändern müssen. Wenn einer der Persistenz-Microservices ausfällt, müssen die Logik-Microservices damit umgehen, was schwierig ist, da sie eigentlich auf die Daten angewiesen sind.
Aber auch Änderungen sind bei einem solchen Schnitt schwierig: Eine typische Änderung umfasst einen Geschäftsprozess und beeinflusst daher alle Schichten: Zusätzliche Daten müssen in den Persistenz-Microservices verwaltet werden, die Logik-Microservices müssen angepasst werden und die UI muss ebenfalls modifiziert werden, damit der Benutzer den Ablauf und die Daten verwalten kann.
Dieser Architektur-Ansatz ermöglicht also keine fachlich unabhängigen Microservices. Daher müssen sich die Teams für fachliche Änderungen eng abstimmen. So ist eine Selbst-Organisation der Teams praktisch unmöglich.
Die Microservices sind zwar technisch immer noch entkoppelt, aber das nützt nicht viel. Wenn ein Feature in Produktion gebracht werden soll, müssen mehrere Microservices koordiniert deployt werden, weil das Feature in mehreren Microservices implementiert ist. Ebenso können die Microservices immer noch isoliert ausfallen, aber wegen der vielen Abhängigkeiten ist es schwierig, die anderen Microservices gegen den Ausfall abzusichern. Auch Continuous Delivery ist nicht mehr so einfach umsetzbar: Natürlich können die Continuous-Delivery-Pipelines immer noch unabhängig sein, aber Tests für neue Features müssen sich über mehrere Microservices erstrecken. Also ist es schwieriger, die Tests auf die Pipelines aufzuteilen. Und selbst wenn die Continuous-Delivery-Pipelines unabhängig sind, nützt das nicht viel, weil ein neues Features Änderungen in mehreren Microservices und damit den Durchlauf mehrerer Continuous-Delivery-Pipelines benötigt.
Herausforderungen wie die zusätzliche Komplexität im Betrieb verringern sich bei diesem Ansatz nicht. Im Gegenteil: Die Umsetzung von Resilience wird sogar schwieriger.
Zentrale Datenbank
Ähnliches gilt für eine zentrale Datenbank. Sie enthält ein Schema, das alle Microservices nutzen. Wie schon bei der Aufteilung in Schichten begrenzt das die Unabhängigkeit der Systeme, weil so die Persistenzschicht geteilt wird. Hinzu kommt, dass die Architektur-Firewalls kompromittiert werden. Mit einer gemeinsamen Persistenz-Schicht ist es einfach möglich, die Daten anderer Microservices zu nutzen und so unabsichtlich Abhängigkeiten aufzubauen. Erfahrungsgemäß sind Abhängigkeiten auf der Datenbank-Ebene besonders eng und schwer zu entfernen. Es ist wichtig, diese Herausforderung zu kennen, denn erschreckend häufig werden Microservices mit einer zentralen Datenbank kombiniert. Das kann dann zu erheblichen Architektur-Herausforderungen führen.
Auf Ebene der Fachlichkeit ist es also wichtig, eine vernünftige Aufteilung des Systems zu definieren, weil sonst die Abhängigkeiten zwischen den fachlichen Modulen zu großen Problemen führen. Leider nehmen viele Projekte jedoch an, dass die Nutzung von Microservices alleine die Modularisierung verbessern wird. Da Microservices aber nur eine andere Art von Modulen sind, ist das natürlich nicht so.
Serverless
Technisch sind Microservices meistens mit Docker oder Kubernetes umgesetzt. Ein Microservice ist dann als ein Docker-Container implementiert. Das erlaubt Technologie-Freiheit: Was in dem Docker Container läuft, kann in jeder Programmiersprache geschrieben sein. Gleichzeitig werden Probleme wie Service Discovery oder Load Balancing gelöst [1].
Eine Alternative ist Serverless. Dieser Ansatz abstrahiert von Servern. Die kleinste Einheit bei Function as a Service (FaaS) sind Functions, die auf Events reagieren. Ein solcher Event kann ein REST-Aufruf sein oder das Hinzufügen eines Datensatzes in einer Datenbank. Diese Functions werden erst dann hochgefahren, wenn tatsächlich Requests vorliegen und skalieren abhängig von der Last. Das erlaubt ein anderes ökonomisches Modell. Eine Funktion, die gerade nicht aufgerufen wird, verursacht keine Kosten und daher müssen auch keine Kosten berechnet werden. Ebenso kann eine Funktion, die nur wenig genutzt wird, preiswert oder kostenlos angeboten werden. So können viel kleinere Microservices realisiert werden, weil die Kosten für eine Funktion vernachlässigt werden können.
Eine Implementierung von Serverless ist Amazon Lambda. Es unterstützt Java, Node.js, C# und Python. Das Serverless Application Model (SAM) erlaubt es, mehrere Funktionen zusammenzufassen und so auch größere Projekte übersichtlich umzusetzen. Für das eigene Rechenzentrum gibt es Lösungen auf der Basis von Kubernetes wie beispielsweise kubeless.
Auf der Ebene der Architektur erlaubt Serverless kleinere Microservices. Außerdem ist die Kopplung über Events vorgegeben. Auch ein synchroner REST-Call von außen wird intern in einen Event umgewandelt. Dafür sind die Technologien eingeschränkt: Es werden nicht alle Programmiersprachen unterstützt, die in einem Docker Container laufen können. Und schließlich ist FaaS nicht genug: Datenbanken und Infrastruktur für Kommunikation aber auch Monitoring ist notwendig. Diese Technologien werden von dem jeweiligen Cloud-Anbieter zur Verfügung gestellt. Dadurch entstehen natürlich zusätzliche Abhängigkeiten. Oft wird die Architektur eher zu einem Ansatz, bei dem die Serverless-Funktionen nur noch Glue Code zur Koordination verschiedener anderer Cloud-Dienste werden.
So kann Serverless als technische Weiterentwicklung von Microservices interpretiert werden: Kleinere Services, weniger Technologie-Freiheit und mehr Nutzung von vorhandenen Bausteinen.
Deployment Monolithen
Eine weitere Alternative zu Microservices sind natürlich Deployment Monolithen. Das ist zunächst eine Aussage über das Deployment: Die Anwendung wird als Ganzes deployt. Wie schon dargestellt, haben Deployment Monolithen einige technische Einschränkungen. Aber ein Deployment Monolith hat auch einen Vorteil: Das Deployment ist einfach und der Betrieb ebenfalls. Es müssen nicht eine Vielzahl von Microservices in Produktion gebracht werden und dort überwacht werden, sondern nur ein Deployment Monolith.
Leider sind wohl strukturierte Deployment Monolithen in der Praxis die Ausnahme. Der Grund dafür ist die mangelnde Trennung der Module voneinander. Es ist sehr einfach, eine Klasse aus einem anderen Modul zu nutzen und so Abhängigkeiten einzubauen, die eigentlich nicht erlaubt sind. Oft merken Entwickler das noch nicht einmal, so dass über die Zeit die Struktur des Deployment Monolithen verloren geht. Daher überrascht es, dass in der aktuellen Diskussion Deployment Monolithen als Lösung präsentiert werden, denn gerade bei der Strukturierung haben Deployment Monolithen meistens erhebliche Defizite und das sollte mittlerweile auch jedem Entwickler klar sein, denn jeder Entwickler hat wohl schon einmal an einem solchen schlecht strukturieren Deployment Monolithen gearbeitet.
Microservices haben beispielsweise REST-Schnittstellen und erzwingen daher wie schon erwähnt die Modulgrenzen. Modulgrenzen können in einem Deployment Monolithen natürlich auch erzwungen werden. Dazu können Architetur-Management-Werkzeuge wie Structure 101, jQAssistant oder Sotograph dienen. Sie warnen Entwickler, wenn sie Modulgrenzen überschreiten. Es gibt aber auch andere Möglichkeiten: So erzeugt die Build-Reihenfolge ebenfalls klare Modulgrenzen. Wenn ein Modul vor einem anderen gebaut wird, kann es das andere Modul nicht nutzen, weil es durch den späteren Build-Zeitpunkt schlicht nicht zur Verfügung steht.
Über einen Deployment Monolithen ohne solche Maßnahmen zu diskutieren, macht wenig Sinn: Sie haben eben nach einiger Zeit keine sinnvolle Strukturierung mehr und man kann nicht mehr von Architektur sprechen.
Aber selbst ein perfekt strukturierter Deployment Monolith ist eben ein Deployment Monolith. Und das begrenzt die mögliche Deployment-Geschwindigkeit. Wenn der Monolith Wochen oder Monate getestet werden muss und da Deployment einen Tag in Anspruch nimmt, dann wird es praktisch unmöglich, den Monolithen mehrfach pro Tag zu deployen, wie dies mit Microservices möglich ist. Und selbst wenn das möglich wäre: Es ist unsinnig zum Erreichen dieses Ziels eine Änderung an der Architektur von vorne herein auszuschließen.
Also können Deployment Monolithen ein sinnvoller Kompromiss sein, wenn man ein Architektur-Management einführt und mit der niedrigen Deployment-Geschwindigkeit leben kann. Selbst dann kann ein Deployment Monolith keine Entkopplung bieten wie die Microservices tun: Der Technologie Stack ist festgelegt, das Deployment muss koordiniert werden und nur das ganze System kann skaliert werden. Gerade wegen der immer noch zunehmenden Bedeutung von Continuous Delivery sind Deployment Monolithen nicht wirklich zukunftsweisend.
Quellen
-
Eberhard Wolff: Technologien für Microservices, JavaMagazin 9.18 ↩