
Um die Unterstützung von Innovationen durch Software-Architektur zu betrachten, muss zunächst der Begriff Innovation geklärt werden. Innovation bedeutet, dass neue Produkte und Dienste auf den Markt kommen und damit letztendlich neue Umsatzquellen entstehen. Es ist also nicht ausreichend, einfach nur eine neue Technologie zu entwerfen, sondern die Technologie muss tatsächlich Geld in die Kasse bringen.
Ebenso muss der Begriff Software-Architektur geklärt werden. Oft wird unter der Software-Architektur die Aufteilung eines Systems in verschiedene Komponenten verstanden. Das ist sicher richtig. Schon der Begriff „Architektur“ weist in eine solche Richtung. Es geht um die grobgranulare Gestaltung eines Systems, während Design und Implementierung die fein granulare Arbeit an einem System umfasst. Aber es gibt noch einen weiteren wichtigen Bestandteil der Software-Architektur-Arbeit: Die Software-Architektur muss sicherstellen, dass die notwendigen Qualitätsmerkmale durch geeignete technologische Maßnahmen erreicht werden. Qualitätsmerkmale werden oft nicht-funktionale Anforderungen genannt. Beispielsweise kann Skalierbarkeit oder Sicherheit ein Ziel einer Architektur sein. Dann muss die Architektur Technologien wählen, die solche Ziele unterstützen.
Was benötigt Innovation?
Um Innovation mit Hilfe von Software zu unterstützen, muss die Software zwei Qualitätsmerkmale umsetzten:
- Der Erfolg der Software muss messbar sein. Wenn eine Änderung in der Software zu einem höheren Umsatz führen oder zu mehr Registrierungen soll, dann muss diese Metrik messbar sein. Das ist wichtig, denn oft beeinflussen Änderungen Metriken gar nicht oder verschlechtern sie sogar. So behauptet der ehemalige Chef des Data Minings bei Amazon Ronny Kohavi, dass 60–90 % aller Ideen, die eigentlich eine Metrik verbessern sollen, dieses Ziel nicht erreichen [1]. Ohne ein Feedback durch Metriken kann der Erfolg von Änderungen nicht ermittelt werden.
- Um Maßnahmen zu ergreifen, die eine Metrik ändern sollen, muss die Software änderbar sein. Die Änderungen müssen nicht nur in der Software vorgenommen werden, sondern tatsächlich in Produktion ausgerollt werden und Nutzern zur Verfügung stehen. Nur dann können die Änderungen tatsächlich genutzt werden, Geld einbringen und Metriken erhoben werden.
Diese Aspekte stehen für einen ganz anderen Ansatz bei der Software-Entwicklung. Software kann nicht nach einem längerfristigen Plan entwickelt werden, wenn sie Innovationen unterstützen soll. Wenn beispielsweise eine Website in einem komplexen, langfristigen Projekt komplett neu erstellt wird, dann besteht diese Entwicklung aus einer Vielzahl von Änderungen. Diese Änderungen sollen Metriken wie Umsatz oder Registrierungen verbessern. Da aber alle diese Änderungen gemeinsam umgesetzt werden, kann man kaum noch die Auswirkungen jeder einzelnen Änderung bewerten. Der größte Teil der Änderungen verbessert aber eben nicht den Erfolg der Software. Daher ist ein umfangreiches Projekt kaum sinnvoll. An Stelle solcher Projekte müssen einzelne Änderungen treten, die einzeln bewertet werden können. Nur so können die nicht erfolgreichen Änderungen isoliert und gegebenenfalls zurückgerollt werden.
Änderbare Software: Der heilige Gral
Um viele kleine Änderungen in der Software umzusetzen, muss die Software einfach anpassbar sein. Änderbare Software ist eine Anforderung in sehr vielen Projekten und eine Art heiliger Gral der Software-Entwicklung. Eine saubere Architektur und eine hohe Codequalität sind die üblichen Maßnahmen, um die Änderbarkeit der Software sicherzustellen.
Für Innovationen ist eine andere Art der Änderbarkeit notwendig: Es sind viele kleine Änderungen, die jeweils einzeln in Produktion gebracht werden. Dazu ist Continuous Delivery [2] ein wichtiges Werkzeug. Im Mittelpunkt von Continuous Delivery steht der Aufbau einer Continuous-Delivery-Pipeline, mit der Änderungen an der Software in Produktion gebracht werden. Sie besteht aus verschiedenen Phasen:
- Der Commit Stage kompiliert die Software, führt die Unit Tests aus und kann die Software außerdem einer statischen Code-Analyse unterziehen. Diese Phase ist daher weitergehend identisch mit dem, was sonst ein Continuous Integration Server durchführt.
- Die nächste Phase sind automatisierte Akzeptanztests. Wie der Name schon verrät, sollen sie sicherstellen, dass der Kunde die Software akzeptiert bzw. abnimmt. Durch die Automatisierung können die Tests sehr häufig ausgeführt werden. Die Tests stellen die korrekte fachliche Implementierung sicher.
- Kapazitätstests stellen sicher, dass die Software die zu erwartende Last mit der notwendigen Performance behandeln kann. Auch diese Tests sind automatisiert.
- Schließlich wird die Software in Produktion gebracht. Das Ausrollen ist ebenfalls automatisiert, so dass keine manuelle Änderung an irgendeinem System notwendig ist.
Ziele von Continuous Delivery
Wesentliches Ziel eine Continuous-Delivery-Pipeline (siehe Abb. 1) ist die Reduktion des Risikos beim Produktivstellen einer Änderung. Oft wird Continuous Delivery mit einer Automatisierung von Software-Installation gleichgesetzt. Die Installation der Software ist aber oft nicht das Grund, warum nicht häufiger deployt wird. Das Deployment ist oft innerhalb eines Tages möglich und damit wären tägliche Deployments denkbar. Oft ist das Problem das mangelnde Vertrauen in die Änderungen und die Angst, Fehler in die Produktion einzuführen. Die Tests in der Pipeline reduzieren dieses Risiko. Darüber hinaus gibt es weitere Maßnahmen. So wird bei einem Blue/Green-Deployment eine komplett neue Umgebung aufgebaut, in der die Software installiert wird. Dann wird auf die neue Umgebung umgeschaltet. Dieses Vorgehen ermöglicht weitere Tests kurz vor der Produktivstellung der Software und erleichtert den Rückfall auf eine alte Version, wenn die neue Version doch nicht zuverlässig funktioniert.
Ein weiteres Ziel von Continuous Delivery ist schnelles Feedback. Wenn in der Software ein Fehler ist, soll der Fehler möglichst schnell gefunden werden. Das ist der Grund, warum die Tests regelmäßig ausgeführt werden. So wird beim nächsten Durchlauf der Pipeline bereits auf einen Fehler aufmerksam gemacht. So bekommt ein Entwickler nach Stunden Feedback, ob seine Änderungen korrekt und nicht erst nach Wochen oder Monaten. Das erleichtert die Fehlersuche. Dieses Vorgehen passt gut zu der notwendigen Unterstützung für Innovation: Änderungen, die bestimmte Geschäftsmetriken verbessern sollen, können ebenfalls schnell darauf abgeklopft werden, ob diese Verbesserungen wirklich eintreten. Daher sollte auch Feedback aus der Produktion eingeholt werden und dort Geschäftsmetriken erhoben werden. Das kann mit denselben Werkzeugen geschehen, die auch technische Metriken erfassen – also Logging und passende Metrik-Werkzeuge. Es könnne aber auch andere Werkzeuge zum Beispiel aus dem Bereich Web-Marketing sein.

Continuous Delivery und Innovation
Continuous Delivery unterstützt also Innovation, weil Software einfacher änderbar wird – und zwar nicht in dem Sinne, dass die Änderung des Sourcecodes einfacher ist, sondern Änderungen tatsächlich in Produktion gebracht werden und für Kunden verfügbar sind. Im Wesentlichen geschieht das durch eine einfachere und zuverlässigere Produktionseinführung. Auch die Idee der Kontrolle der Produktion mit Hilfe von Metriken ist hilfreich, um Innovationen zu evaluieren.
Um allerdings Continuous Delivery wirklich umsetzten zu können, muss die Software und die Architektur dieses Vorgehen unterstützen. Eine Continuous-Delivery-Pipeline lässt sich nur umsetzen, wenn die Software geeignet entworfen ist:
- Sie muss einfach deploybar und testbar sein. Da die Pipeline um wesentlichen Software tests und deployt, wird dann die Umsetzung der Pipeline wesentlichen einfacher.
- Wenn die Software in mehrere unabhängig deploybare Module aufgeteilt wird, kann für jedes Modul eine eigene Pipeline umgesetzt werden. Das vereinfacht die Umsetzung der Pipeline und ermöglicht auch einen schnelleren Durchlauf durch die Pipeline.
Letztendlich erlaubt Continuous Delivery also so, Änderbarkeit von Software durch weitere Maßnahmen zu unterstützen: Die Software-Architektur muss dafür sorgen, dass das Deployment der Software möglichst einfach ist. Dann kann durch Continuous Delivery die Software einfacher änderbar werden (Abb. 2).
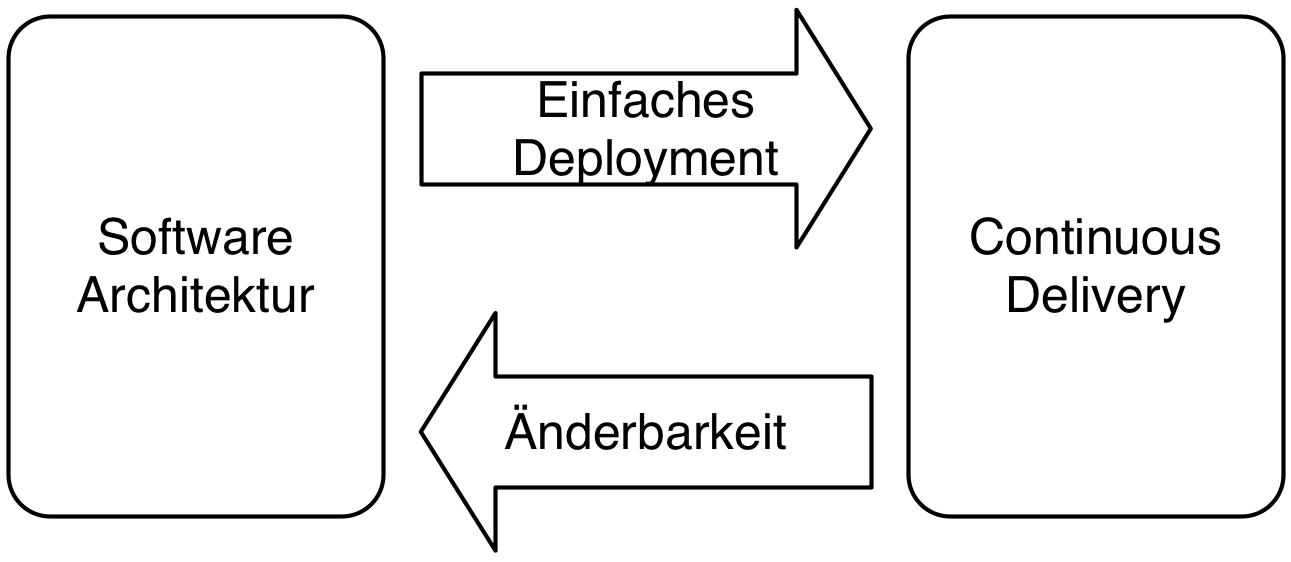
Software-Architektur für Continuous Delivery?
Die Frage ist nun, wie Architektur Continuous Delivery unterstützen kann. Eine Möglichkeit sind Microservices [3][4]. Microservices sind eine besondere Art der Modularisierung von Software. Module dienen dazu, eine Software in kleine Einheiten zu zerteilen, so dass ein Entwickler nur jeweils ein solches Modul verstehen muss, um es zu ändern. Später werden dann alle Module zusammengesetzt und gemeinsam deployt.
Microservices wählen einen anderen Ansatz: Microservices sind Module, die einzeln in Produktion gebracht werden. Sie können als getrennte Prozesse, in virtuellen Maschinen oder auch in Docker Containern als leichtgewichtige Alternative zu virtuellen Maschinen umgesetzt sein. Microservices können über REST oder Messaging integriert werden. Sie können auch auf Ebene der Web UI beispielsweise über Links zusammengesetzt werden. Schließlich ist auch die Replikation von Daten eine mögliche Form der Integration.
Beispielsweise kann in einer E-Commerce-Anwendung die Registrierung ein eigener Microservice sein, der die UI im Web anbietet, die gesamte Logik implementiert und auch die Daten hält. Eine Änderung in der Registrierung kann vollständig in diesem Microservices abgebildet werden und mit einem einzigen Deployment in Produktion gebracht werden.
Für Continuous Delivery hat das Vorteile:
- Die Umsetzung der Continuous-Delivery-Pipeline ist wesentlich einfacher, weil ein Microservice eine relative kleine Einheit ist, die außerdem getrennt von anderen Microservices in Produktion gebracht werden kann. Eine Continuous-Delivery-Pipeline für eine solche kleine Einheit ist einfach umsetzbar. Ansätze wie Blue/Green-Deployment sind wegen der geringeren Größe der deploybaren Einheiten ebenfalls einfacher umsetzbar.
- Ebenso ist die Integration anderer Systemen kein so großes Problem, weil ein Microservice weniger andere Systeme integriert als wenn das gesamte System deployt wird.
- Der Durchlauf durch die Pipeline ist schneller, weil es für einen Microservice weniger Test gibt als für das gesamte System.
- Auch das Risiko eines Deployments ist geringer: Nur jeweils ein Microservices wird deployt. Alle anderen bleiben unverändert und können daher auch nicht plötzlich Fehler enthalten.
Microservices zur Skalierung von Agilität
Aber Microservices vereinfachen nicht nur Continuous Delivery. Sie unterstützen auch Agilität. Das Ziel agiler Software-Entwicklung ist, Software schnell in Produktion zu bringen – beispielsweise durch vierzehntägige Iterationen, in denen neue Features geplant und umgesetzt werden. Aus der Produktion geht dann Feedback zurück in die Entwicklung.
Für ein großes komplexes System ist dieses Vorgehen alleine schon schwer realisierbar, weil das Deployment aufwändig ist. Ebenso ist es schwierig, das Feedback tatsächlich zu erheben. Außerdem muss für das gesamte System eine gemeinsame technische Basis ausgewählt werden. So muss die Programmiersprache und auch die verwendeten Libraries für das gesamte System vorgegeben werden. Und ein Release umfasst immer das gesamt System. Also müssen Releases und Technologien für das gesamte System koordiniert werden.
Je mehr Personen an der Entwicklung des Systems beteiligt sind, desto schwieriger wird die Koordination. Die Arbeit aller Entwickler muss in einem Release zu einem sinnvollen Ganzen zusammengestellt werden. Ebenso muss die technische Basis zwischen allen Entwicklern koordiniert werden. Schon das Update einer Library als Bugfix kann bedeuten, dass irgendwo Fehler auftauchen, weil es zwar bestimmte Fehler behebt, aber vielleicht andere neu einführt.
Architektur und Organisation
Laut dem Gesetz von Conway [5] gibt es eine Beziehung zwischen Software-Architektur und der Organisation, die die Software erstellt. Das Gesetz besagt, dass die Kommunikationsstrukturen in der Organisation der Architektur entsprechen. Das ist eigentlich logisch – wenn zwei Teams oder Entwickler zusammenarbeiten, werden sie eine Schnittstelle in der Architektur definieren, um so die Zusammenarbeit zu organisieren. Umgekehrt muss eine Schnittstelle in der Architektur zwischen verschiedenen Teams oder Entwicklern abgestimmt werden. Das Gesetz von Conway wird oft als eine Begrenzung der Architektur interpretiert: Ein Team kann nur solche Architekturen umsetzten, die seiner Organisation entspricht. Wenn beispielsweise ein UI-Team, ein Backend-Team und ein Datenbank-Team aufgesetzt werden, dann wird die Software diese drei schichten haben.
Microservices nutzen das Gesetz von Conway, um die Architektur an der Organisation auszurichten. Das System besteht aus Microservices, die jeweils von einem Team verantwortet werden. So stellt die Organisation sicher, dass die Architektur umgesetzt wird. Die Teams müssen dann für jede Komponente UI, Backend und Datenbank umsetzten können. Solche cross-funktionalen Teams sind aber auch aus Sicht der agilen Software-Entwicklung wünschenswert, damit die Teams möglichst unabhängig voneinander arbeiten können.
Durch Microservices können diese Teams tatsächlich weitgehend unabhängig voneinander Feature in Produktion bringen, da Microservices unabhängiges Deployment erlauben. Wenn der fachliche Schnitt der Microservices gut ist, kann auch die Implementierung weitgehend unabhängig erfolgen. Zusätzlich kann jedes Team technische Entscheidung eigenständig treffen (Abb. 3).
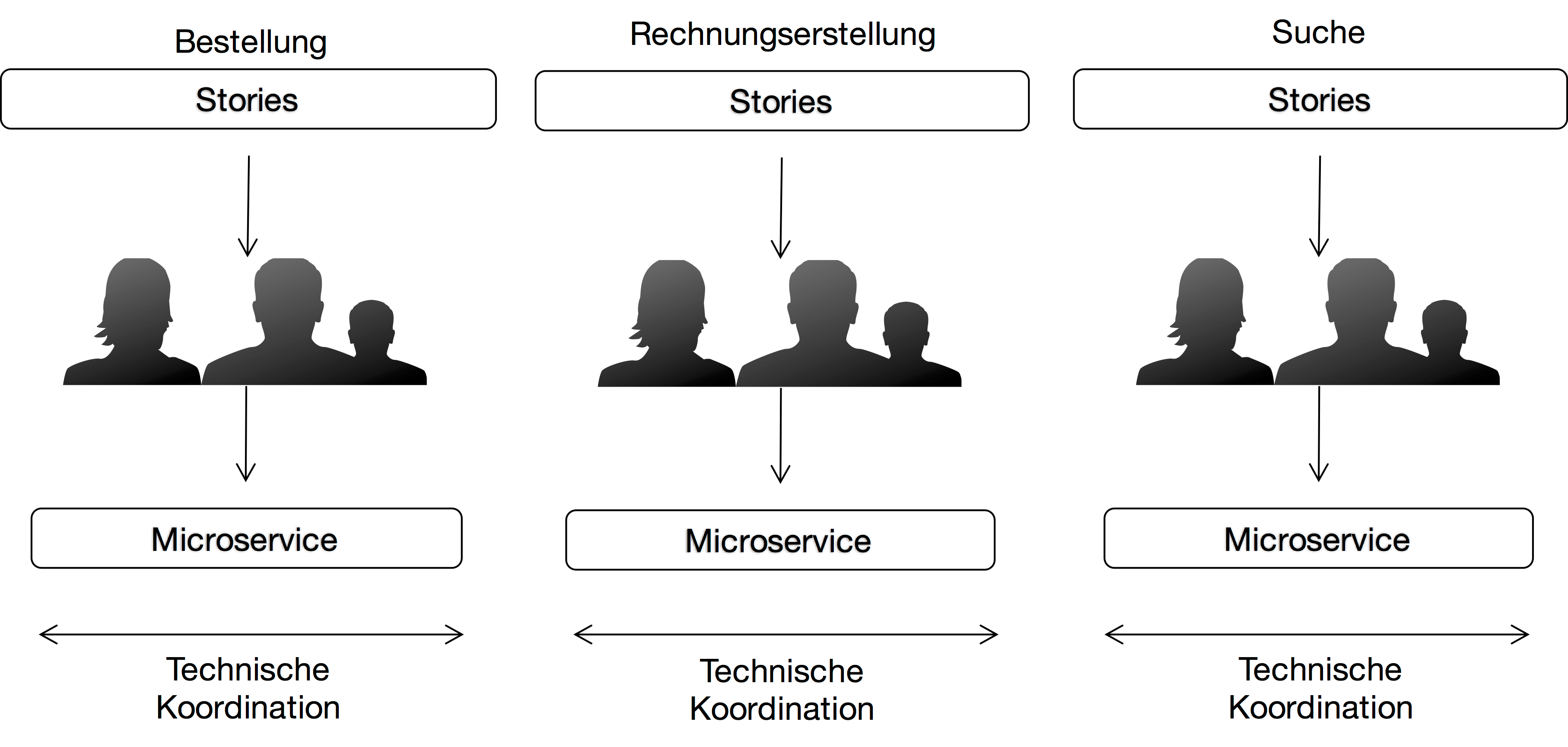
Wie schon erwähnt, sind Microservices Prozesse, virtuelle Maschinen oder Docker Container. Also kann jeder Microservice in einer anderen Programmiersprach auf einer anderen Plattform implementiert sein. Es ist daher nicht notwendig, den Teams Technologien vorzuschreiben. Natürlich kann man dennoch die Technologie-Wahl beschränken, aber die Architektur erzwingt das nicht. Wenn die gesamte Anwendung nur ein Prozess ist, müsst die technische Basis weitgehend festgelegt sein. Im Falle von Java müssten sogar die Version jeder Bibliothek genau definiert werden, weil nur eine Version einer Bibliothek in einem System genutzt werden kann.
Globale Vorgaben für das gesamte Projekt stellen die Makro-Architektur dar. Dazu zählt beispielsweise das Kommunikationsprotokoll, beispielsweise REST oder Messaging. Nur wenn das Protokoll einheitlich ist, können tatsächlich Module zusammenarbeiten. Betriebliche Aspekte wie Monitoring, Deployment oder der Umgang mit Logs können ebenfalls Teil der Marko-Architektur sein Das beschneidet die Freiheit der Teams kaum, reduziert aber den Aufwand beim Betrieb erheblich, da einheitliche Lösungen genutzt werden können. Die Mikro-Architektur sind jene Entscheidungen, die jedes Team selber treffen kann. Dazu kann die Programmiersprache und die Plattform gehören.
Microservices ermöglichen es, den größten Teil der Entscheidungen in den Teams als Teil der Mikro-Architektur zu treffen. Das unterstützt die Selbstorganisation und erlaubt den Teams, ungewöhnliche Wege zu gehen und neue Technologien zu nutzen, ohne sich mit anderen Teams zu koordinieren. Das sind natürlich gute Voraussetzungen, um innovative Konzepte umzusetzen.
Fazit
Ein wichtiges Fazit ist, dass Software nicht nur durch hohe Codequalität und saubere Architektur änderbar ist. Eine Continuous-Delivery-Pipeline erreicht ebenfalls eine bessere Änderbarkeit, weil durch Tests und automatisches Deployment Änderungen sehr einfach in Produktion gebracht werden können. Die Änderbarkeit der Software ist aber nur ein Grund, warum Continuous Delivery gut zu Innovation passt. Ebenso wichtig ist, dass Continuous Delivery eine Auswertung des Erfolgs in der Produktion ermöglicht. Das ist für Innovation wichtig, denn nur der Erfolg gegenüber dem Kunden zeigt, ob eine Änderung wirklich eine echte Innovation ist.
Microservices unterstützen Continuous Delivery, weil sie Software in unabhängig deploybare Komponenten aufteilt. So können Continuous-Delivery-Konzepte wesentlich einfacher umgesetzt werden. Außerdem erlauben Microservices es den einzelnen Teams, Änderungen unabhängig von den anderen Teams in Produktion zu bringen und auch eigene, unabhängige technologische Entscheidungen zu treffen. Das erlaubt mehr Experimente und damit eine einfachere Umsetzung innovativer Lösungen.
Links & Literatur
-
Jez Humble;Joanne Molesky;Barry O‘Reilly: Lean Enterprise: How High Performance Organizations Innovate at Scale, O’Reilly Media, 2015, ISBN 978–1449368425 ↩
-
Eberhard Wolff: Continuous Delivery: Der pragmatische Einstieg, 2. Auflage, dpunkt.verlag, 2016, ISBN 978–3864903717 ↩
-
Eberhard Wolff: Microservices: Grundlagen flexibler Softwarearchitekturen, dpunkt.verlag, 2015, ISBN 978–3864903137 ↩
-
Eberhard Wolff: Microservices Primer: A Short Overview, Createspace, 2016, ISBN 978–1523472130 (kostenlos unter http://microservices–book.com/primer.html) ↩