
Microservices are the current hype in the Software Architecture community. However, microservices can be used in many different scenarios to reach different goals. Self-contained Systems (SCS) are one approach to achieve some of those goals while avoiding many common pitfalls.
What are Microservices?
Microservices are not well defined. For the purpose of this article, microservices [1][2] are considered as another way to modularize software. Usually, modules partition a system to simplify design and development. But once the software is built, it becomes just one unit that is deployed as a whole. This is different for microservices: Each microservice can be deployed by itself. However, this is only possible if a technology is used which supports that - e.g. if each microservices is a Docker container. Then, each deployment would replace the Docker container with a different version that is then started and replaces the old Docker container. This also means microservices can use any technology and any platform that seems useful - as long as it runs in a Docker container.
Why Microservices?
There are many different reasons why teams might turn to microservices as an alternative architecture. For example, smaller teams might use microservices because Continuous Delivery is much easier with smaller deployment units. They can also be scaled individually instead of scaling a large deployment monolith.
Large projects might use microservices to scale agile processes. Each team can autonomously develop and deploy its microservices without a lot of coordination with other teams. They can bring features into production independently. Also, almost all technical decisions can be made inside one team. Hardly any coordination is needed any more - neither concerning technology nor concerning new features. That way much larger systems can be build because communication is often the limiting factor.
Self-Contained Systems
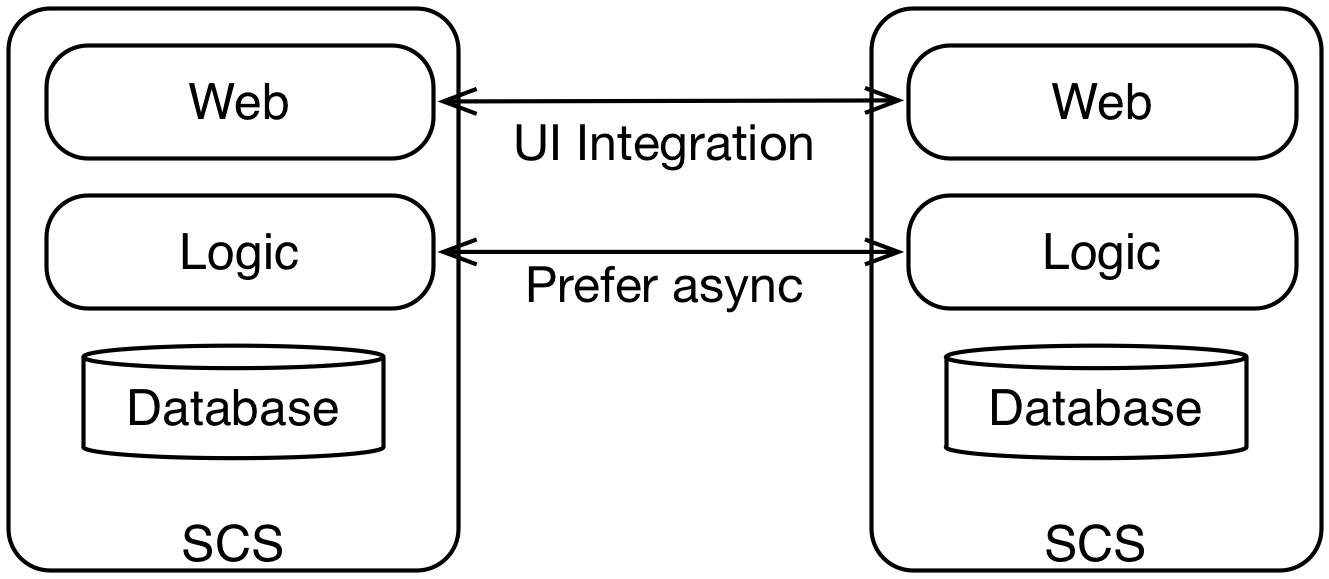
SCS are differ from microservices at a fundamental level: They are well defined. The SCS website [3] includes this definition. SCS are web applications - including the code to render the web interface, the business logic as well as the data and the database. This sets them apart from microservices that are often considered to just provide a REST interface - so the UI is a separate entity. Also, microservices might or might not provide the data.
Because each SCS has its own web interface, SCSs should not have a shared UI. That way a change or a new business feature can usually be contained to one SCS. No matter whether the change would just require a small tweak to the logic or require a lot of modifications to not just the logic but also the data structures, database and UI - all of this is included in the SCS. So the change can be contained in a single SCS.
SCS might also provide an API to call the logic from the outside. However, the API is optional. It might be used to access the logic e.g. from a mobile app. However, in that case a change might require changes to the SCS and the mobile app - so it becomes more complicated to implement the change.
A system that just provides an API is not an SCS by definition. It might still be considered a useful architecture, of course - but it would not be called SCS.
As you can see the definition for a Self-Contained System excludes quite a few types of microservices systems and is therefore very precise.
Limiting each change to a single SCS is an important goal. As mentioned above microservices and also SCS are independent deployment units. So if a change or a new feature just requires one SCS to be updated, only one SCS needs to be deployed. This is much easier than deploying a multitude of microservices and coordinating changes across various microservices.
Investing all the effort to make modules of a system individually deployable makes little sense if developers end up deploying more than one module for each change. Also, deployments that cover multiple microservices are quite hard. If microservices communicate through an interfaces that needs to be updated, care must be taken not to break the communication during the update process. That requires backwards compatibility or versioning of interfaces - which adds to the complexity of the system.
SCS and Organization
Organization is core to the definition of an SCS. One of the rules is: An SCS should be owned by one team. If the SCS is rather small, a team might also work on multiple SCS. But multiple teams might never work on a single SCS - because that would require too much communication and coordination. It just doesn’t make any sense to separate a system into decoupled modules but then have several teams work on one module.
Thus, a feature would ideally be implemented by a single team in a single SCS, so teams can work on features in isolation and decide about the implementation and the architecture.
But each SCS can also use different technologies. Not just frameworks but also programming languages and even databases. This means technical decision can be made by each team. It goes without saying that standards can still be set and enforced. But even then, a team might decide about introducing an update or a bug fix for a library it uses without having to organize meetings with all the other teams.
Integrating SCS
Ideally, Self-Contained Systems should be as decoupled as possible and not communicate with each other at all. However, the SCS are still part of a larger system. Therefore, some kind of integration is needed.
Communication to other SCS can be done in different way:
An integration on the UI level is the preferred approach. For example, a product search in one SCS can link to a page containing product details that is provided by a different SCS. Links are a powerful feature that drives the world-wide web. But sometimes parts of one web page should be included in another web page, e.g. a shopping cart should be displayed in the header of each page of a e-commerce website . This can be done using transclusion [4], i.e. including parts of a web page in another web page with JavaScript code or on the server-side using Edge or Server Side Includes (ESI / SSI).
Of course, SCS sometimes might need to call each other. Preferably, that should be done asynchronously. Asynchronous communication has many advantages: It decouples the systems and avoids error cascade. If asynchronous communication is used, a temporary unavailability is no big issue.
SCS can also communicate synchronously if this is necessary. However, the systems then are more tightly coupled and error cascades might occur - in particular, if synchronous request happen during request processing. At other times, this might still work fine. You might even argue that this would actually be asynchronous communication because even if the communication is delayed for some time, both systems just work fine.
It is important to note that asynchronous communication does not really depend on the protocol [5]. Asynchronous communication can be easily implemented using messaging protocols like AMQP or JMS. However, it is also possible to use REST for asynchronous communication, e.g. by polling data from an Atom feed. The Atom format is usually used to subscribe to blogs. To get updates, the feed is polled. Thus, it is possible to do asynchronous communication over a synchronous protocol.
Data replication
During request processing an SCS should not communicate with any other system synchronously. However, it might still need data from other systems. It seems to be impossible get the data asynchronously - because they are needed during the processing of the request. To enable asynchronous communication it might be necessary to replicate the data. That way, data would be copied to the other system. There would be no need to call another system if this data is needed to process a request - it is already available in the other system.
Of course, this means that data is stored redundantly. This might cause inconsistencies. Some changes might not have made their way to all replicas. There are several ways to deal with this issue:
One system should be the source of truth for each data item. That way, it is possible to replace any data with the latest version from the original source.
Event sourcing advocates focus on the events and treat databases as just a snapshot of the state after all events have been processed. If the data is corrupt, it can be recreated by reprocessing the events.
The additional effort for replicating data and the potential inconsistencies are the price that must be paid for the decoupling. Decoupling is an important goal for any microservices system and therefore it might make sense to also replicate data. However, it would still be possible to get data from other SCS synchronously. Synchronous communication is not forbidden - it is just the least preferred option.
SCS Architecture
Cutting a system into SCSs can be done by a vertical decomposition. The system has to be separated into multiple parts that each have a UI, logic and database. This might be done by implementing a group of use cases in each SCS. Each SCS is then responsible for the complete implementation of the use cases - including UI, logic and database. For example, in an e-commerce application choosing the payment method and choosing the method of delivery are two related use cases. They might end up in one SCS. The SCS then contains the data to implement these use cases, i.e. rates for the different delivery methods. Obviously, this data would later be needed to actually delivery the order. Therefore, the data might be replicated to other SCSs that implement these parts of the system.
It might also make sense to look at a customer journey. In an e-commerce system a customer will usually first search for products, put product in a shopping cart, then register or log in, and finally, check out. Later on, he / she might be looking at the current status of his / her order. Each of these stages might be implemented in an SCS - again with data, logic, and UI.
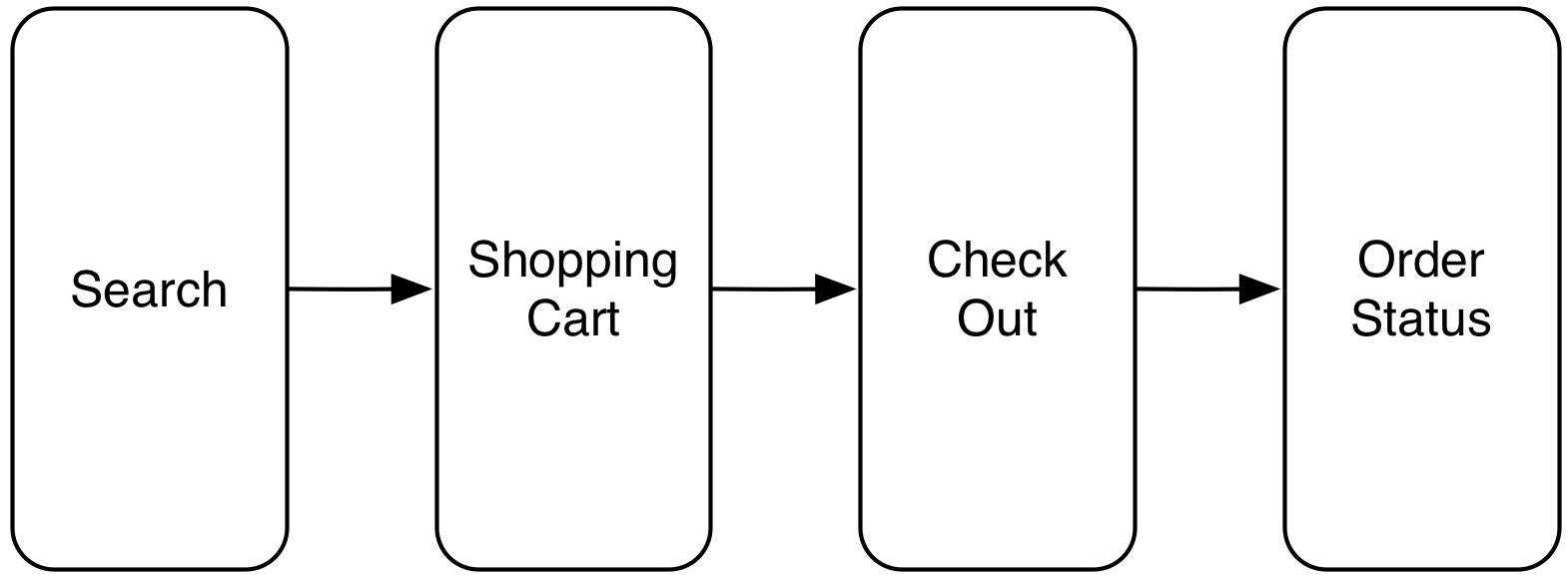
These approaches ensure that the separation into SCS results in a clear separation into modules that are each responsible for a part of the domain logic. This architecture also increases the chance that changes are local to one SCS. Usually, a change will only cover related use cases - and those are implemented in one SCS.
Who is doing it?
There is a considerable number of projects that use SCS and companies that implemented the approach successfully [6]. These include Otto - #3 in the e-commerce business, after Amazon and eBay. Otto created a new e-commerce website that provides 85% of the revenue with SCSs. Each team at Otto implements one step in the customer journey in one SCS.
Another example is Kühne + Nagel - a logistics company with more than 60.000 employees and more than $20bn in revenue. SCSs have proven that they work in practise and solve many crucial issues that a lot of organizations face nowadays.
Challenges
Of course, there are challenges when implementing SCS. The focus on UI integration means that a common foundation must be defined. If links are used to integrate SCS, the UIs of the SCSs can be quite diverse. However, if transclusion is used to integrate parts of a web page from multiple sources, a common set of CSS might have to be define. The same is true if the system should have a common look and feel. Common assets on a shared asset server might be an option. Care has to be taken to keep the SCSs as independent from each other as possible. Sharing assets is a very strong dependency.
At the end of the day, this is not very different from what other means of communication (like REST) require: A definition of an interface to ensure that all systems can actually talk to each other. The only difference is that in the case of SCSs, it is about common UI elements and a shared UI.
Sometimes the SCS concept cannot be fully implemented because data is stored in backend systems. Ideally, an SCS would include all logic and data in its own system. However, the backend system might be beyond the reach of the project. This means, the data and parts of the logic would remain in the backend system. This seems like a contradiction: Shouldn’t all the logic be in the SCS and therefore the frontend? The pragmatic approach is to use as many ideas form the SCS approach as possible, i.e. the focus on UI integration, asynchronous communication and data replication. These can also be applied to the integration with backend systems. Maybe you cannot get all logic in the frontend, but the approach will still help you to understand how backend systems can be handled.
Conclusion
Self-Contained Systems provide a way to split a system into individually deployable units - essentially microservices. They focus on loose coupling, enabled by data replication, asynchronous communication and UI integration. This helps to build systems from actually decoupled services, and therefore focuses on the strengths of microservices. Experience shows that this approach is working quite well for large and small projects alike.
If you want to take a closer look at Self-Contained Services, this website [3] contains a lot of material. It is licensed under a Create Commons license (CC BY-SA 3.0) and can therefore easily be used for your own purposes. The website is hosted on Github [7] - so feel free to submit issues and pull requests.
Links & Literature
-
Microservices: Flexible Software Architectures, Eberhard Wolff, 2016, ISBN 978–1523361250 ↩
-
Microservices Primer: A Short Overview, Eberhard Wolff, 2016, download for free at http://microservices–book.com/primer.html ↩
-
https://www.innoq.com/en/blog/why-restful-communication-between-microservices-can-be-perfectly-fine/ ↩