


Die beiden Fragen „Wie lange dauert es in Ihrem Unternehmen, bis eine Änderung deployt ist, die nur aus einer Zeile geändertem Code besteht?” und „Passiert dies auf einer wiederholbaren und zuverlässigen Basis?” stammen von Mary und Tom Poppendiek und sind die Leitfragen zu Continuous Delivery. In diesem Artikel wollen wir aber nicht über die Konzepte von Continuous Delivery schreiben, sondern über fünf Systeme für die Implementierung von Continuous-Delivery-Pipelines. Da wir uns im Cloud-Zeitalter befinden, schauen wir uns nicht nur Systeme an, die auf eigenen (Cloud-)Servern installiert werden können, sondern auch zwei Systeme, die nur als Cloud-Service angeboten werden.
Atlassian Bamboo: Ergänzung zu JIRA und Confluence
Das erste Continuous-Delivery-System, das wir uns ansehen wollen, ist Bamboo [1] von der Firma Atlassian, die auch für die bekannten Tools JIRA, Confluence und HipChat verantwortlich ist. Bamboo ist ein kommerzielles Produkt, dessen Preisstaffelung unter [2] gefunden werden kann. Neben der klassischen Installation auf den eigenen (Cloud-)Servern bietet Atlassian für seine gesamte Produktpalette eine Cloud-Lösung, für die man eine monatliche Abogebühr zahlen muss. Die Preisstaffelung dazu findet man ebenfalls unter [2]. Auch wenn Bamboo ein kommerzielles Produkt ist, haben Sie als Lizenznehmer Zugriff auf die Sourcen.
Die Installation gestaltet sich denkbar einfach. Es kann ein Archiv von der Webseite [1] geladen werden. Dieses wird entpackt und der Server gestartet. Ein webbasierter Assistent führt dann durch die nächsten Schritte. Vorweg etwas zur Benutzerverwaltung: Wer die Produkte von Atlassian kennt, weiß, dass man JIRA für die zentrale Benutzerverwaltung verwenden kann. Das funktioniert auch mit Bamboo. Benutzer und Gruppenzugehörigkeiten aus JIRA lassen sich in Bamboo ebenfalls verwenden. Bamboo geht mit dem vollmundigen Versprechen „Continuous delivery from code to deployment“ an den Start. Das Featureset spricht dafür, dass dieses Versprechen eingehalten werden kann:
- Trennung von Build und Deployment auf verschiedene Umgebungen
- Unterstützung von Feature- und Story-Branches
- Natives Staging-Konzept
- Integration mit JIRA und HipChat
In Bamboo nennen sich die einzelnen Jobs Build-Pläne. Der erste Schritt ist es einen solchen anzulegen. Build-Pläne werden in Projekten gruppiert. Ein Projekt lässt sich im gleichen Schritt mit anlegen. Innerhalb eines Build-Plans gibt man das Code-Repository an und konfiguriert die benötigten Tasks. Ein Task ist eine Aufgabe, die erledigt werden soll, wie ‘Compile’ oder ‘Test’. Ist dieser Schritt abgeschlossen, hat man die erste Stage schon konfiguriert. Man kann den Plan direkt ausführen und live dabei zusehen, was im Einzelnen passiert. Schlägt ein Test fehl, kann man aus der Fehlermeldung direkt einen Bug in JIRA einstellen (Abb. 1).
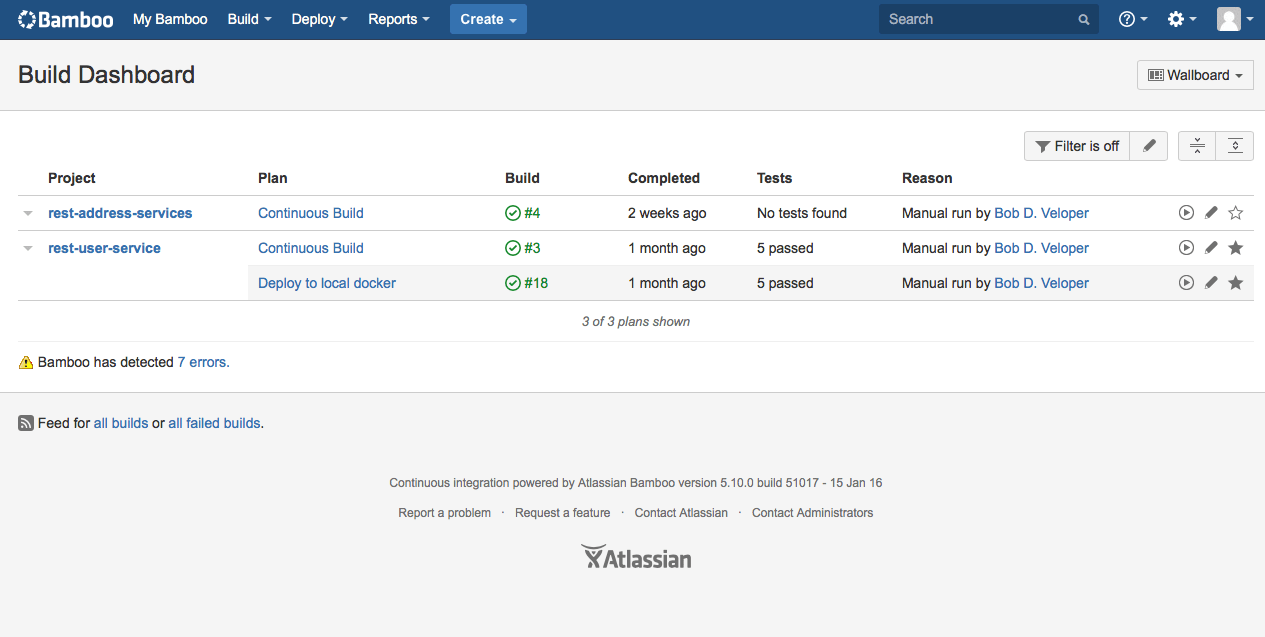
Die nächste Stage wären weiterführende Tests, z.B. Integrationstests. Innerhalb des Build-Plans erstellt man eine neue Stage und konfiguriert die benötigten Tasks. Denkbar wären der Checkout, Compile, Deploy in eine lokale Docker-Infrastruktur oder das Ausführen der Integrationstests. So kann man Schritt für Schritt die eigene Continuous-Delivery-Pipeline erweitern.
Ein weiteres interessantes Feature ist die Unterstützung von Feature- und Story-Branches. Wenn man für den Master einen Build-Plan konfiguriert hat, erkennt Bamboo die davon abgezweigten Branches und kopiert den Build-Plan für diesen Branch. Dieses Feature ist für Git, Mercurial und Subversion verfügbar. Zusätzlich kann man konfigurieren, ob der Branch automatisch gelöscht werden soll. Dafür gibt es verschiedene Strategien. Genaueres erfährt man unter [3]. Bamboo kann Änderungen eines Branches direkt zurück in den Ursprungs-Branch mergen. Auch hierfür gibt es zwei Strategien, die unter [3] detaillierter erklärt sind. Wenn eines Tages der Zeitpunkt kommt – wir hoffen früher als später–, an dem man sein Produkt auf Servern deployen will, die außerhalb der Entwicklung liegen, helfen die Bamboo-Deployment-Projekte.
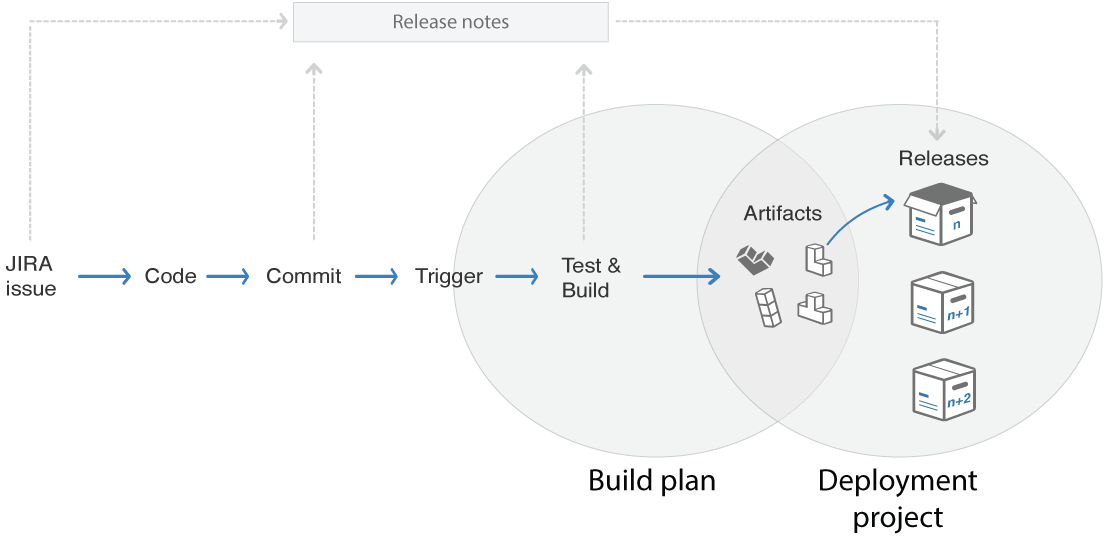
Wie in Abbildung 2 schematisch zu sehen ist, werden die Artefakte aus den Build-Plänen für die Deployment-Projekte herangezogen. Somit ist es möglich, verschiedene Sourcecode-Stände für die Deployments heranzuziehen. In der Konfiguration eines Deployment-Projekts wählt man den zugrunde liegenden Build-Plan und den zugrunde liegenden Branch. Als Ziel für das Deployment werden Docker, Amazon S3, Heroku und eigene Server unterstützt. Weitere Deployment-Ziele lassen sich mit Add-ons nachrüsten.
Bamboo basiert auf so genannten Agenten. Damit können Build-Pläne und auch Deployment-Projekte auf anderen Servern ausgeführt werden. Somit ist es möglich, bei größeren Projekten oder Unternehmen viele Pläne parallel auszuführen. Seit Neuestem ist auch ein Agent für iOS-basierte Builds verfügbar.
Damit das Entwicklungsteam schnelles Feedback bekommt, unterstützt Bamboo verschiedene Notification-Schemas. Zum einem gibt es die klassische E-Mail, und zum anderen wird das hauseigene Chatsystem HipChat unterstützt. Mittels Add-on lässt sich auch Slack nachrüsten.
Bamboo lässt sich mit Add-ons erweitern. Im Vergleich zu Jenkins ist das Angebot an Add-ons wesentlich geringer, allerdings ist die Qualität hier vergleichsweise höher. Man kann jedoch auch mit dem zur Verfügung stehenden SDK eigene Erweiterungen programmieren.
Vor allem, wenn man andere Tools von Atlassian, wie JIRA oder Confluence, bereits im Einsatz hat, bietet sich Bamboo an. Die Trennung zwischen Build und Deployment ergibt Sinn und ist gut gelöst. Bamboo ist mehr als nur einen Blick wert und bietet Umsteigern von Jenkins auch ein Migrationstool.
TeamCity: Gute Skalierung
Die Firma JetBrains, unter Entwicklern vor allem bekannt für ihre IDEs (u.a. IntelliJ IDEA und WebStorm), bietet mit TeamCity [4] eine Continuous-Delivery-Lösung für den Self-Hosting-Bereich. Als Grundlage für diesen Artikel kam Version 9.1.6 zum Einsatz. TeamCity wird in zwei unterschiedlichen Lizenzvarianten angeboten: in der kostenfreien Professional-Server-Lizenz und in der Enterprise-Server-Lizenz. Erstere eignet sich vor allem für den Einstieg und bei kleineren Projekten, ist allerdings beschränkt auf zwanzig Build Configurations (so werden hier die Jobs genannt) und drei Build Agents zur parallelen Durchführung von Builds. Bei Bedarf lässt sich diese Lizenz in Schritten von einem Agenten und zehn Build Configurations kostenpflichtig erweitern. Darüber hinaus ist der Support für die Professional-Server-Lizenz auf Forum und Issue Tracker beschränkt, während Enterprise-Kunden einen bevorzugten E-Mail-Support in Anspruch nehmen dürfen.
Die Installationsprozedur ist gut dokumentiert, und die grundsätzliche Einrichtung für Datenbank oder Admin-Nutzer ist mithilfe des Einrichtungsassistenten ebenfalls einfach gestaltet, sodass TeamCity schnell einsatzbereit ist. Server- sowie projektspezifische Einstellungen werden mit einer Administrationsoberfläche verwaltet, die sich eher an technisch versierte Nutzer richtet. Eine Nutzerverwaltung ist integriert, es lassen sich aber auch LDAP oder Windows Active Directory als Quelle [5] nutzen. Der Zugriff auf Projekte lässt sich bei aktivierter Per-Project-Permissions-Einstellung über Gruppen und Rollen steuern und ermöglicht somit auch das Umsetzen komplexerer Anforderungen an das Zugriffsmodell.
Das Einrichten neuer Projekte gestaltet sich mithilfe des Assistenten einfach, und es können hierarchische Projektstrukturen erstellt werden. Projekte dienen als Container für Subprojekte oder Build Configurations. TeamCity unterscheidet nicht zwischen Build- und Deployment-Jobs. Es stehen verschiedene Runner wie Ant, Maven, SBT oder Command Line zur Verfügung, welche die einzelnen Schritte eins Jobs entsprechend ihrer Konfiguration ausführen.
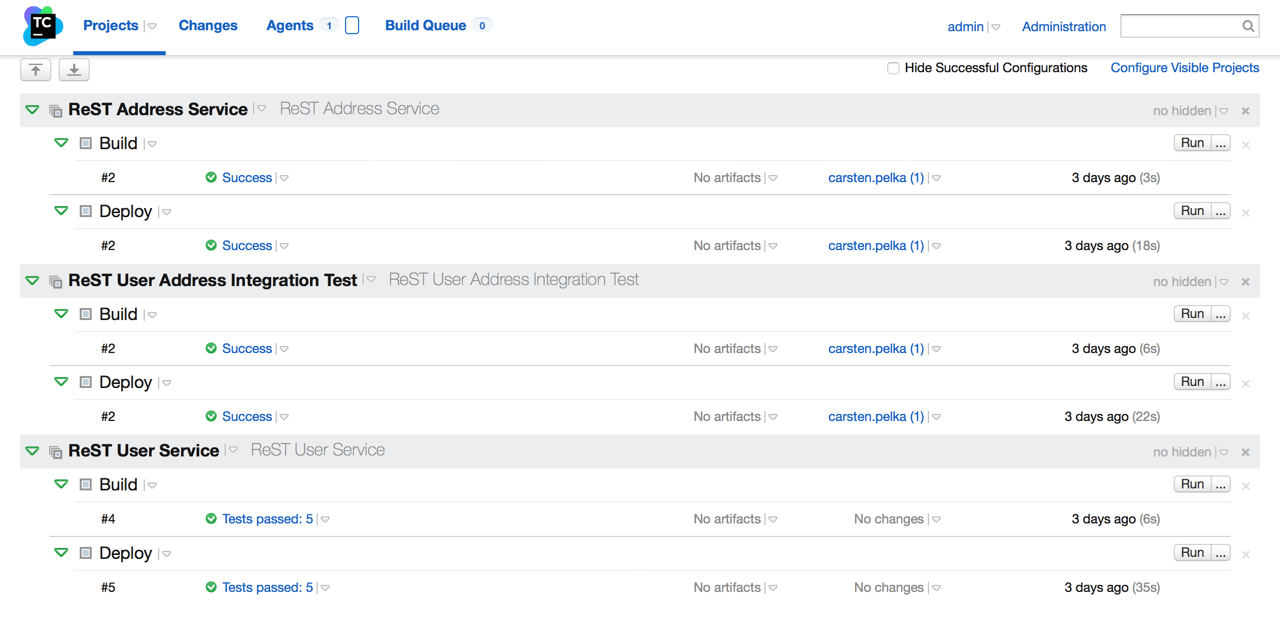
In unserem Beispiel (Abb. 3) wurden jeweils zwei Build Configurations pro Projekt angelegt:
Bei Build löst ein Code-Check-in in das konfigurierte Versionskontrollsystem folgende Schritte aus: der neueste Code wird aus dem GitHub Repository ausgecheckt, über den Maven Runner werden lokale Tests durchgeführt und das Artefakt wird gebaut sowie ggf. in ein Repository deployt.
Bei Deploy werden nach einem erfolgreichen Build die Build Configurations getriggert. Die sichere Interaktion mit dem Zielserver wird durch die auf dem System hinterlegten SSH-Keys ermöglicht, sodass in den Konfigurationen kein Passwort hinterlegt werden muss. Die notwendigen Schritte übernimmt der Command Line Runner. Er kopiert das Artefakt auf den Zielserver und startet einen Java-Prozess mit dem Artefakt. Mit dem Command Line Runner lassen sich beliebige Operationen ausführen. Dies ermöglicht einerseits Deployments – zu denen es in TeamCity keine Templates gibt – und andererseits lässt sich so der gesamte Prozess auch mit Docker implementieren. Auf dem ausführenden Build-Agent und bei Deployment natürlich auch auf dem Zielserver muss lediglich Docker zur Verfügung stehen.
TeamCity unterstützt alle gängigen Versionskontrollsysteme. Als Trigger für alle Build Configurations können neben dem Code-Check-in auch andere Quellen genutzt werden, z.B. der Scheduler, fehlgeschlagene Builds oder auch externe Events wie das Release von Maven (Snapshot) Dependencies.
Im Standardumfang sind bereits Integrationen mit einigen Issue Trackern wie JIRA, Bugzilla sowie YouTrack enthalten und müssen nur auf der Projektebene konfiguriert werden. Anschließend erkennt das System Ticketreferenzen in Commit-Messages automatisch, und es werden direkte Links zum Ticket erstellt. Bei den Statusmitteilungen setzt man bei JetBrains auf Altbewährtes: TeamCity unterstützt E-Mail und Jabber standardmäßig. Das offene Plug-in-System erlaubt es, TeamCity um benötigte Funktionen zu erweitern, z.B. Kommunikationskanäle wie Slack oder HipChat. Eine nach Themen sortierte Übersicht bereits vorhandener Plug-ins listet das TeamCity-Wiki [6].
TeamCity hat zu Recht viele Fans (nicht nur) unter Entwicklern. Die Software skaliert gut mit der Projektgröße und dank der Erweiterbarkeit sind nahezu alle Anforderungen erfüllbar. Allerdings wäre zukünftig eine Generalüberholung des User Interface wünschenswert.
Jenkins: Pipeline as Code
Jenkins [7], ursprünglich unter dem Namen Hudson gestartet und nach rechtlichen Problemen [8] unter Jenkins weitergeführt, dürfte das am häufigsten eingesetzte Continuous-Delivery-System sein [9]. Die Installation von Jenkins gestaltet sich einfach: Nachdem man das Paket von [7] heruntergeladen und gestartet hat, ist Jenkins einsatzbereit. Die Benutzeroberfläche kann man im Browser unter http://localhost:8080 erreichen.
Bezüglich der Nutzerverwaltung lässt Jenkins kaum Wünsche offen: von einer integrierten, eigenen Nutzerverwaltung über Unix-Log-ins bis hin zu Plug-ins für LDAP, Active Directory, Google- sowie GitHub-Logins und mehr ist alles vertreten. Deployments lassen sich entweder über eigene Skripte realisieren oder via Plug-ins in allen größeren Anbietern wie AWS oder Heroku ausführen. Auch Notifications via E-Mail, Slack, IRC, HipChat und Anbindungen zu JIRA oder Bugzilla bringen Plug-ins ein. Eine beeindruckend lange Liste weiterer Plug-ins kann unter [10] abgerufen werden.
Jenkins unterscheidet, im Gegensatz zu anderen Lösungen, nicht zwischen Build und Deployment: In Jenkins ist alles ein Job – in der Oberfläche oft als Item beschrieben. Jobs bestehen aus einer Abfolge von Befehlen. Diesen Befehlen können Aktionen vorangehen (z.B. den Code aktualisieren) oder nachfolgen (z.B. Notifications verschicken). Jobs können so genannte Upstream- und Downstream-Abhängigkeiten zueinander besitzen. Durch eine solche Beziehung kann ein Job einen anderen Job aufrufen oder aufgerufen werden, sobald seine Upstream-Abhängigkeit die eigenen Aufgaben abgearbeitet hat. Mithilfe des Delivery-Pipeline-Plug-ins [11] kann eine Pipeline durch diese Abhängigkeiten modelliert und visualisiert werden. Diese Lösung hat allerdings zwei Nachteile: Zum einen ist der Konfigurationsaufwand groß und zum anderen kann keine Abhängigkeit zwischen zwei Pipelines ausgedrückt werden, ohne dass diese Pipelines in der Visualisierung zu einer Pipeline verschmelzen.
Abhilfe schafft ein neues Plug-in namens Pipeline (vormals Workflow [12]), das für die Realisierung einer Continuous-Delivery-Pipeline verwendet werden kann. Bei diesem Plug-in wird die komplette Pipeline mit einer speziellen DSL in einem Job beschrieben. Die Definition der Pipeline lässt sich entweder über die Jenkins-Oberfläche erstellen oder als Datei in einem Code-Repository ablegen. Letzteres hat den Vorteil, dass die Pipeline-Definition versioniert und zusammen mit dem Quellcode gespeichert werden kann, statt einmalig zusammengeklickt zu werden. Jenkins nennt dieses Konzept „Pipeline as Code” und bewirbt es zu Recht als das Highlight der Version 2.0.
Um Pipeline zu nutzen, legt man zunächst unter Configure System eine Maven-Installation namens mvn an. Anschließend installiert man die Plug-ins Pipeline: Stage View Plug-in und Git Plug-in und startet Jenkins neu. Wenn man nun auf New Item klickt, hat man die Möglichkeit, eine Konfiguration des Typs Pipeline anzulegen. Um eine Beispieldefinition von einem Git Repository zu lesen, wählt man in der Konfiguration unter Pipeline Definition die Option Pipeline script from SCM aus und konfiguriert dort als URL das Git Repository von [13]. Nachdem man die Konfiguration gespeichert und auf Build Now geklickt hat, sollte sich während des Testlaufs die Pipeline aus Abbildung 4 aufbauen. Die Definition dieser Pipeline kann man in der Datei Jenkinsfile unter [13] einsehen und als Basis für eigene Projekte nutzen. Die letzte Stage der Pipeline ist ein manueller Deploy, den der Nutzer mit einem Mausklick bestätigen muss.
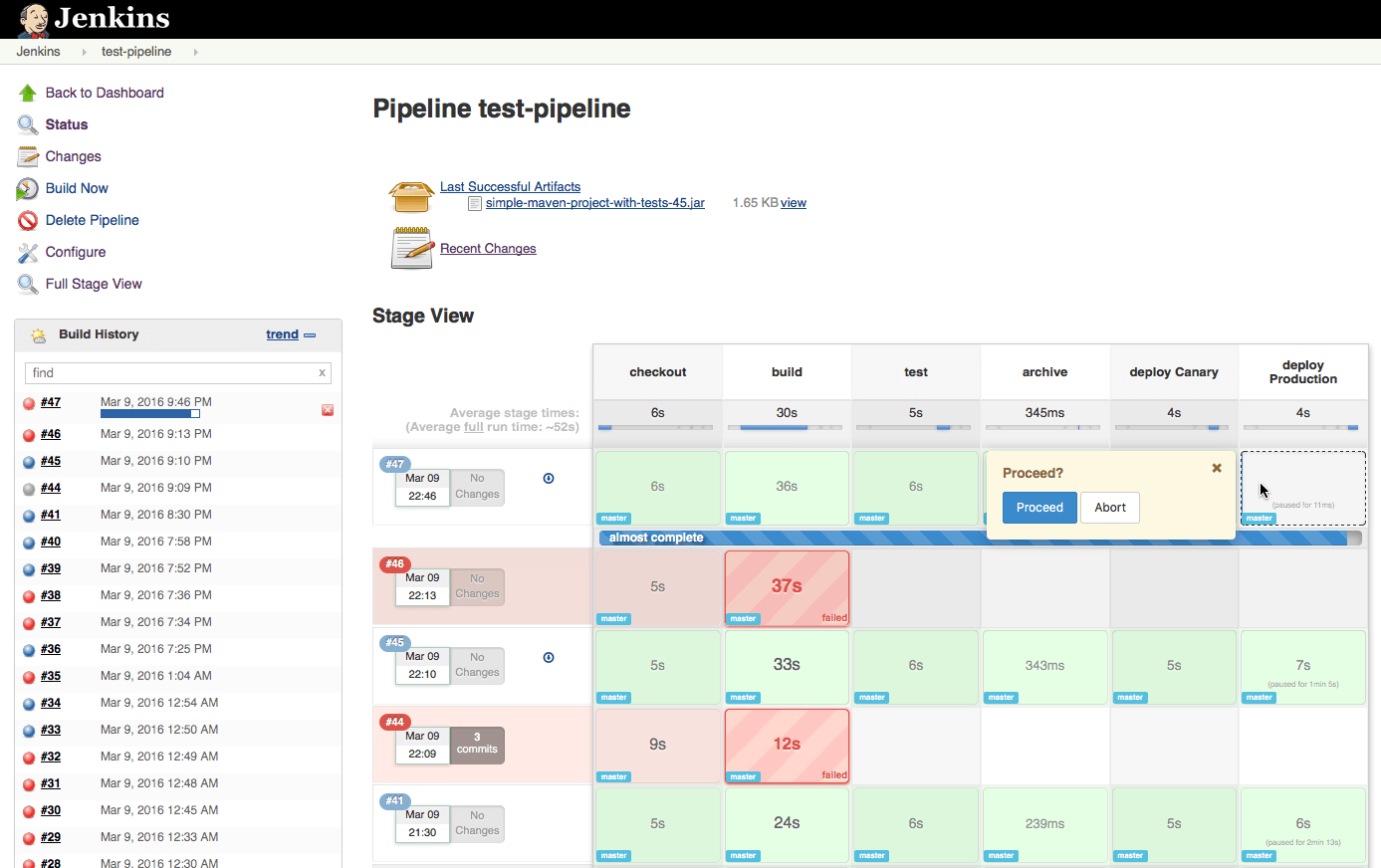
Jenkins schlägt mit dem hier vorgestellten Plug-in einen richtigen Weg zur Umsetzung von Continuous Delivery ein, da Pipelines als Jobs implementiert werden. Die „Pipeline as Code”-Strategie macht die Pipeline zu einem Teil vom Code und nicht zu einem Teil des Testsystems. Für Teams, die bereits Jenkins verwenden und aufgrund mangelnder Pipelineunterstützung andere Produkte in Erwägung ziehen, könnte das Pipeline-Plug-in eine valide Lösung sein.
Semaphore: Solider Cloud-basierter Integrationsprozess
Semaphore [14] – bis Anfang 2015 noch unter Semaphore-App geführt – ist ein Cloud-basierter Dienst für Continuous Integration und Deployment, der von der Firma Rendered Text betrieben wird. Das Lizenzierungsmodell ist in zwei Stufen eingeteilt: für Open-Source-Projekte ist es generell und für private Projekte bis zu 100 Builds im Monat kostenfrei. Gegen Aufpreis entfällt die Beschränkung der Build-Anzahl für private Projekte bei maximal zwei Prozessoren. Für Unternehmen gibt es Varianten mit bis zu 16 Prozessoren ohne Einschränkung der Build-Anzahl. Ebenfalls enthalten ist hier ein Nutzer- und Rechtemanagement sowie Support durch das Semaphore-Team.
Eine Installation entfällt bei Cloud-basierten Diensten, lediglich eine Registrierung ist notwendig. Diese beschränkt sich darauf, eine E-Mail-Adresse abzufragen sowie Nutzername und Passwort festlegen zu lassen. Anschließend beginnt ein assistierter Prozess, um GitHub- oder Bitbucket- Accounts mit dem Semaphore-Account zu verbinden. Über diese Accounts werden dann Zugriffe auf einzelne Code-Repositories gewährt. Andere Hosts für Code-Repositories, etwa innerhalb eines Unternehmensnetzwerks, werden nicht unterstützt. Aus der Verbindung zu einem Repository leitet sich dann automatisch ein Projekt ab. Ohne weitere manuelle Konfiguration lauscht Semaphore ab sofort auf Commits im Code-Repository und kann anschließend den Build-Prozess triggern. Alternativ lässt sich dies auch über einen Scheduler steuern. Neben Java mit Maven werden hier weit verbreitete Programmiersprachen (u.a. Scala, JavaScript, PHP, C++, Ruby, Python, Go und Erlang) und Build-Tools unterstützt.
Sempahore trennt Build und Deployment strukturell voneinander. Nach erfolgreichem Build kann dies auf einen oder mehrere unterschiedliche Server deployt werden. Dafür gibt es Templates, die diesen Schritt für einige Anbieter vereinfachen. In der aktuellen Plattformversion werden Heroku, Capistrano, Cloud 66 und AWS unterstützt. Sollte das nicht reichen, besteht die Möglichkeit, über das generische Deployment-Template benutzerdefinierte Server zu nutzen. Für diesen wird auch ein SSH-Key angelegt, sodass auf Passwörter im Klartext verzichtet werden kann.
Die gesamte Build- und Deployment-Kette inklusive letzter Ereignisse ist auf dem projekteigenen Dashboard gut zu erkennen (Abb. 5). Erfreulicherweise skaliert dieses auch und erlaubt die Nutzung von mobilen Endgeräten wie Smartphones oder Tablets.
Für den Fall, dass für die Abbildung des Build- und Deployment-Prozesses eine Datenbank benötigt wird, bietet Semaphore verschiedene integrierte SQL- und NoSQL-Datenbanken an, die mit einfachen Umgebungsvariablen genutzt werden können. Auch Docker wird mittlerweile zumindest im Betastadium angeboten. Ein schönes Feature ist die Möglichkeit, Build-Prozesse über eine SSH-Verbindung zu debuggen.
Um den Stakeholdern Statusmitteilungen zukommen zu lassen, sind eine Reihe von Schnittstellen implementiert: Neben dem klassischen Weg über E-Mail stehen hier auch Anbindungen an Slack, HipChat, Campfire und Flowdock bereit. Leider fehlt (noch) eine Integration mit Issue Trackern, sodass hier weder Ticket-IDs erkannt noch erfolgreiche oder fehlerhafte Codeintegrationen gleich an einzelne Tickets angehängt werden können.
Semaphore ist ein gelungenes Beispiel eines Cloud-basierten Continuous-Integration- und Delivery-Tools. Die Einrichtung ist zeitgemäß, die Handhabung intuitiv. Auch wenn die Optionen – allein durch den Wegfall der Erweiterbarkeit – nicht so vielfältig sind wie bei den self-hosted Vertretern, dürfte dies für viele Projekte mehr als ausreichend sein, zumal neue Featurereleases noch in relativ kurzen Zyklen kommen.
CircleCI: Für die Remote-Steuerung
Unter dem Namen CircleCI [15] bietet die gleichnamige Firma eine in der Cloud gehostete Lösung für Continuous Integration. Im Gegensatz zu anderen Anbietern setzt man nicht auf Lizenzen, sondern rechnet in Containern zur Ausführung von Builds. Für Organisationen und private Nutzung ist der erste Container frei, Open-Source-Projekte erhalten vier. Das Scaling von Containern erfolgt dann schrittweise und lässt sich jederzeit dynamisch anpassen.
Wie auch bei Semaphore entfällt die Installation, auch eine Registrierung ist zunächst nicht notwendig. Der erste Nutzer – egal ob privat oder Organisation – authentifiziert sich mit einem GitHub-Account, weitere können später hinzugefügt werden. Der Feature-Request [16] für die Integration von Bitbucket ist noch in der Umsetzung und wird hoffentlich bald nachgereicht. Die Projektstruktur leitet sich über die Repository-Struktur ab, und die Zugriffsrechte werden ebenfalls analog dazu übernommen.
CircleCI trennt zwischen Build und Deployment. Die notwendigen Schritte zur Fertigstellung eines Builds werden automatisch anhand der Programmiersprache und des Build-Systems erkannt und eingerichtet. Bei den Beispielprojekten auf Basis von Java und Maven funktionierte dies problemlos. Als weitere Programmiersprachen werden Ruby/Rails, Python, Node.js, PHP, Java, Scala und Haskell sowie die zugehörigen Build-Technologien unterstützt. Die Plattform bietet darüber hinaus die Möglichkeit, Docker-Images zu bauen. Ähnlich wie auch Semaphore ist es möglich, Builds über eine SSH-Verbindung zu debuggen. Beim Thema Deployment bietet CircleCI derzeit nur Templates für Heroku und AWS.
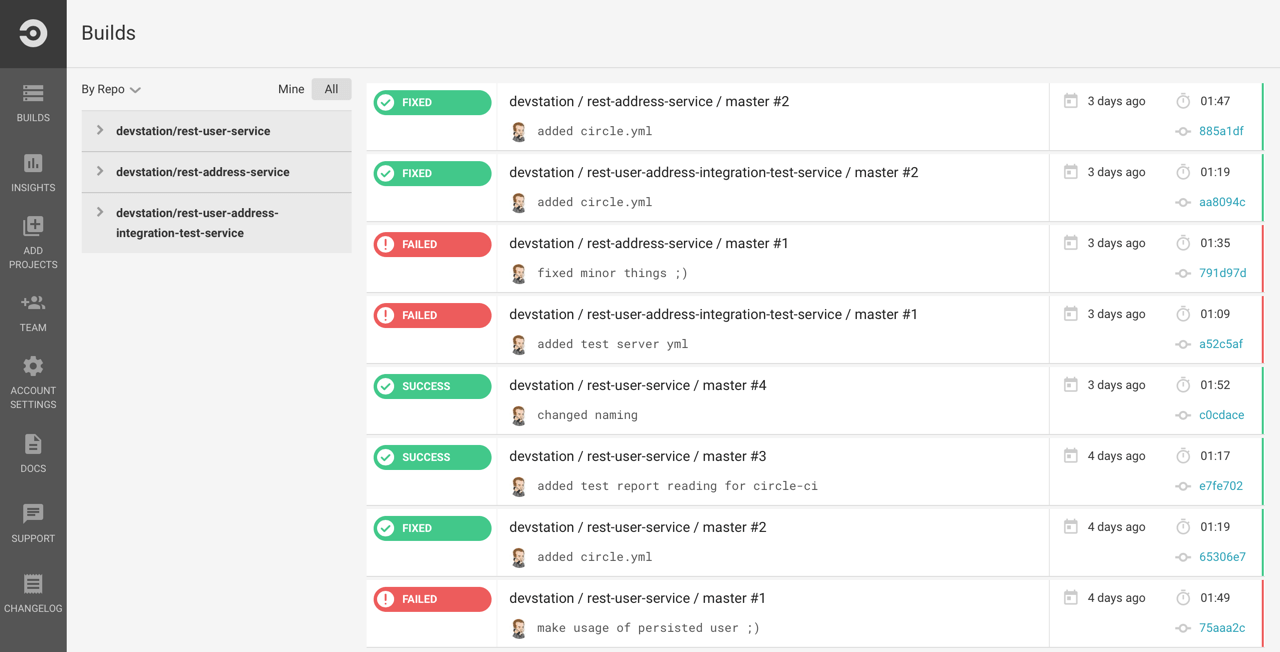
Das moderne User Interface ist klar strukturiert, und die Detailansichten sind informativ. Auf dem Dashboard (Abb. 6) wird eine gute projektübergreifende Übersicht geboten. Allerdings ist leider nur ein kleiner Teil aller möglichen Einstellungen über das UI zu erreichen. Wer Einfluss auf die Einstellungen von Builds nehmen oder benutzerspezifische Builds und Deployments einrichten möchte, muss dies manuell über die Steuerungsdatei circle.yml machen. Zu den Konfigurationsmöglichkeiten dieser Datei existiert eine ausführliche Dokumentation [17], vorgenommene Einstellungen werden allerdings nicht im UI angezeigt. Das liegt auch daran, dass CircleCI die Einrichtung über das UI zwar anbietet, der Schwerpunkt aber auf der externen Steuerung des Diensts basiert. So existiert neben der angesprochenen Steuerungsdatei auch ein API [18], um das System per Remote zu bedienen, etwa um manuelle Builds zu triggern, was aus der Oberfläche heraus nicht möglich ist, oder Details abzufragen. Auch komplexere Operationen zu Berechtigungen werden angeboten.
CircleCI verzichtet auf Statusupdates via E-Mail, bietet dafür aber Anbindungen an Slack, HipChat, Flowdock, Campfire und IRC. Es fehlen ebenfalls Integrationen für Issue Tracker, die auch aufgrund der fehlenden Plug-in- Struktur nicht nachgerüstet werden können.
Die Plattform ist von zwei Seiten aus zu betrachten. Über das Web-UI gesehen beschränkt sie sich insgesamt auf das Wesentliche und erlaubt mittels einfacher Einrichtung Build und Deployment. Die Stärke spielt CircleCI aus, wenn die Konfiguration separat gepflegt und für die Steuerung der Builds und Deployments die angebotene REST-Schnittstelle genutzt wird.
-
Bamboo–Preisstaffelung: https://de.atlassian.com/software/bamboo/pricing ↩
-
Atlassian Documentation „Using plan branches”: https://confluence.atlassian.com/bamboo/using-plan-branches-289276872.html ↩
-
TeamCity: https://www.jetbrains.com/teamcity ↩
-
TeamCity Configuring Authentication Settings: https://confluence.jetbrains.com/display/TCD9/Configuring+Authentication+Settings ↩
-
TeamCity–Plug–ins: https://confluence.jetbrains.com/display/TW/TeamCity+Plugins ↩
-
Jenkins: http://jenkins-ci.org ↩
-
Bayer, Andrew: „Hudson’s future”: https://jenkins-ci.org/ ↩
-
Humble, Charles: „What CI Server do you use?”: http://www.infoq.com/ ↩
-
Jenkins–Plug–ins: https://wiki.jenkins-ci.org/display/JENKINS/Plugins ↩
-
Delivery–Pipeline–Plug–in: https://wiki.jenkins-ci.org/display/JENKINS/ ↩
-
Jenkins Pipeline: http://jenkins-ci.org/solutions/pipeline ↩
-
Jenkinsfile auf GitHub: https://github.com/kesselborn/jenkinsfile ↩
-
Semaphore: https://semaphoreci.com ↩
-
CircleCI: http://circleci.com ↩
-
Feature Request für CircleCI: https://discuss.circleci.com/t/add-support-for-bitbucket/16 ↩
-
Configuring CircleCI: https://circleci.com/docs/configuration ↩
-
CircleCI–REST–API: https://circleci.com/docs/api ↩