REST wurde von Roy Fielding in seiner Dissertation im Jahr 2000 als Architekturstil für verteilte Hypermediasysteme definiert. Dabei ist ein Architekturstil eine Sammlung an Entwurfsrichtlinien, durch die eine Architektur bestimmte Eigenschaften erhält, wie Skalierbarkeit oder lose Kopplung. Doch warum sollten solch akademische Details in der Praxis relevant sein?
In der Regel wählen wir Architekturen, weil wir damit gewisse Anforderungen erfüllen wollen. Das heißt, wir sollten sie nicht wählen, weil diese Lösung gerade in aller Munde ist – wie gerade bei Microservices, Single-Page-Anwendungen oder auch REST der Fall –, sondern weil sie unser Problem, so gut es eben geht, lösen. Wenn wir nicht wissen, welche Eigenschaften – sowohl positive als auch negative – ein Architekturstil mit sich bringt, ist es auch wenig sinnvoll, ihn einzusetzen.
Als hätte Roy Fielding in die Zukunft blicken können, schreibt er in seiner Dissertation: „Some architectural styles are often portrayed as ‚silver bullet‘ solutions for all forms of software. However, a good designer should select a style that matches the needs of the particular problem being solved.“
Wenn man nun also versteht, welche Richtlinien welche Eigenschaften mit sich bringen, hat man die Möglichkeit, den Architekturstil den eigenen Bedürfnisse anzupassen und kann Vor- und Nachteile bewusst gegeneinander abwägen. Denn es ist in Ordnung, bewusst gegen REST-Prinzipien zu verstoßen, solange dann nicht von einer REST-konformen Architektur gesprochen wird. Beim Entwurf einer webbasierten Architektur sollte berücksichtigt werden, welche Eigenschaften REST durch welche Entwurfsrichtlinien bietet und wie diese ineinander greifen.
Client-Server-Architekturen haben nicht nur Vorteile
Bei der Entwicklung einer Webanwendung bleibt einem gar nichts anderes übrig, als eine Client-Server-Architektur zu wählen. Jedoch werden beim Zusammenfassen der Anforderungen oft die Konsequenzen einer solchen Architektur nicht berücksichtigt.
Der große Vorteil von Webanwendung, dass sie sich auf einer Vielzahl von Plattformen und Geräten ohne weitere Installation benutzen lassen, bringt leider auch einige Nachteile mit sich. Der Server kann die Ausführungsumgebung des Clients nicht kontrollieren. Man nimmt entweder in Kauf, viel Aufwand in die Unterstützung von vielen verschiedenen Clients zu investieren, oder dass die Menge der Benutzer reduziert wird. Ein nützlicher, jedoch häufig nicht genutzter Kompromiss ist, zu akzeptieren, dass die Anwendung nicht auf allen Clients identisch aussieht – im Sinne pixelgenauer Positionen – und sich nicht in allen Details identisch verhält. Natürlich sollte sich die Anwendung ähnlich benutzen lassen und wiederzuerkennen sein. Wenn zum Beispiel ein älterer Client kein SVG unterstützt und dies für interaktive Diagramme nötig ist, so bekommt dieser Client nur eine nicht interaktive Variante angezeigt. Es sollte jedoch das Ziel sein, für jeden Client ein möglichst optimales Erlebnis zu bieten, je nachdem, wie weit verbreitet oder wichtig der jeweilige Client ist.
Bei der Entwicklung klassischer Webanwendungen erhalten der Browser und seine Eigenheiten in der Regel viel Aufmerksamkeit. Im Gegensatz dazu werden programmatische Clients in Architekturdiskussionen leider oft außer Acht gelassen. Allerdings beziehen sich viele der Entwurfsrichtlinien von REST auf die Kommunikation von Client und Server und nicht nur auf den Server alleine. Ein Client beziehungsweise seine Implementierung hat deshalb großen Einfluss auf den Erfolg der Gesamtarchitektur.
Natürlich können sich Server und Client unabhängig voneinander weiterentwickeln, jedoch sollte klar sein, dass die Schnittstelle das zentrale Architekturelement ist und dementsprechend behandelt, dokumentiert und getestet werden sollte. Das heißt auch, dass Änderungen an einer Schnittstelle nicht ohne triftigen Grund und unbemerkt passieren sollten. Und wenn dann nur so, dass ein existierender Client weiterhin damit klar kommen kann. Dies stellt aber auch Anforderungen an den Client: Zum Beispiel sollte er ihm unbekannte Daten ignorieren. Genau diese Unabhängigkeit von Client und Server ist eines der Ziele von REST, die allerdings nicht immer gebraucht wird.
Statelessness: einfacher, als man denkt
Eine weitere, oft auf den ersten Blick schwierig umzusetzen erscheinende Entwurfsrichtlinie ist die zustandslose Kommunikation: Dies bedeutet weder, dass es im Server keinen Zustand geben darf, zum Beispiel im Sinne einer Datenbank, noch, dass der Client keinen Zustand haben darf. Stattdessen heißt dies, dass jeder Request alle Informationen enthalten muss, die zur Verarbeitung notwendig sind. Eine Serverinstanz muss somit vorher noch nie mit diesem Client gesprochen haben, um seinen Request beantworten zu können. Auch wenn es zunächst schwer vorstellbar erscheinen mag, lassen sich auch komplexe Prozessflüsse oder Dialoge mit zustandsloser Kommunikation umsetzen. Dabei wird der Zustand entweder über den URI identifiziert, im Client gehalten oder auf dem Server persistiert.
Diese Zustandslosigkeit führt nicht nur zu sehr guter Skalierbarkeit, sondern verbessert auch die Ausfallsicherheit. Denn ohne großen Aufwand können mehrere Serverinstanzen betrieben werden. Die Komplexität beim Entwickeln ist geringer, da bei der Implementierung der Geschäftslogik für die Verarbeitung eines Requests kein großer Zustandsraum berücksichtigt werden muss. Dies führt auch dazu, dass sich jeder Request unabhängig und einfach testen lässt. Außerdem erleichtert es Monitoring und Debugging, da in jedem Request alle Informationen enthalten sind und nicht erst der gesamte Sessionzustand rekonstruiert werden muss. Ein weiterer Vorteil ist, dass ein fehlgeschlagener Request weniger Auswirkungen hat, da er keinen Zustand (einer Session) zerstört und somit zum Beispiel ohne Weiteres wiederholt werden kann.
Caching sinnvoll einsetzen
Eine sehr einfache, aber oft vernachlässigte Entwurfsrichtlinie ist die sinnvolle Verwendung von Caches. Bei jedem Request kann der Server den Client oder andere dazwischen liegende Komponenten darüber informieren, dass die Antwort auf einen Request für eine gewisse Zeit vorgehalten werden kann. Ohne diese Möglichkeit würde das Web deutliche Performanzprobleme haben. Da praktisch jeder Browser Caching unterstützt, bekommt man damit viel Unterstützung geschenkt, muss sich jedoch auf dem Server um entsprechende Unterstützung kümmern. Dies widerspricht jedoch oft der benötigten Aktualität der Daten. Allerdings gibt es zum einen verschiedene Varianten des Cachings und zum anderen oft auch Daten, die sich selten oder gar nicht ändern, beispielsweise abgeschlossene Vorgänge.
Die verschiedenen Arten von Caching, insbesondere die von HTTP unterstützten, sollte man deshalb kennen: Bei der ersten Variante teilt der Server mit, wie lange die Antwort auf einen Request gültig ist und somit im Cache vorgehalten werden kann. Bei der zweiten liefert der Server eine Information mit, entweder einen Zeitstempel oder eine eindeutige ID, die es dem Client ermöglicht, den Server zu fragen, ob sich die aktuelle Antwort von der ihm schon bekannten unterscheidet. Die erste Variante hat den Vorteil, dass der Client für einen gewissen Zeitraum gar keine Kommunikation mehr initiieren muss, läuft aber Gefahr, Aktualisierungen zu verpassen. Bei der zweiten Variante findet zwar weiterhin Kommunikation statt, aber zumindest muss die Antwort nicht mehr übertragen werden, falls sie sich nicht geändert hat. Die Zeitstempel oder IDs der zweiten Variante können zusätzlich dafür genutzt werden, konkurrierende Schreibzugriffe zu erkennen.
Mit Uniform Interface Operationen jenseits von CRUD abbilden
Am häufigsten wird die Entwurfsrichtlinie Uniform Interface mit REST in Verbindung gebracht. Das heißt, alle relevanten Elemente der Domäne werden als Ressourcen modelliert, die sich über einen URI identifizieren lassen. Zudem gibt es eine feste Menge an Verben, mit denen der Zustand der Ressourcen abgefragt oder verändert werden kann.
Dabei können Ressourcen nicht nur die typischen Domänenobjekte wie Kunden oder Produkte abbilden, sondern auch Operationen, Prozesse oder deren konkrete Ausprägungen, z. B. Stornierungen. So ist es auch möglich, Operationen jenseits von CRUD abzubilden. Leider gibt es viele Schnittstellen, die nichts anderes machen, als umständlich ihr Datenbankmodell und dazugehörige CRUD-Operationen via HTTP zur Verfügung zu stellen. Dies verstößt nicht nur gegen das Geheimnisprinzip, sondern führt in der Regel auch zu Problemen mit der Performanz. Der Entwurf der Ressourcen sollte sich nicht nur am Datenmodell orientieren, sondern vor allem auch an den typischen Anwendungsfällen der Domäne.
Dass man nicht gegen die Semantik der HTTP-Verben verstoßen sollte, ist heute meist akzeptiert. Die Verwendung mehrerer Repräsentationen – z. B. HTML, JSON oder JPG – für eine Ressource wird deutlich seltener genutzt, ist aber oft auch gar nicht nötig. Allerdings sollte man sich darüber im Klaren sein, dass ein REST-konformes API kein reines JSON-API sein muss, sondern durchaus parallel auch HTML ausliefern und somit auch als Webanwendung fungieren kann. Es gibt also de facto keinen Unterschied zwischen Web-APIs und Webanwendungen.
Hypermedia as the engine of application state – kurz HATEOAS – ist inzwischen auch kein unbekanntes Thema mehr, wird jedoch nur selten wirklich genutzt. Das lässt sich vermutlich auf mehrere Gründe zurückführen: Hypermedia hat vor allem das Ziel, Server und Client zu entkoppeln, was aber in vielen Fällen, in denen REST-konforme APIs eingesetzt werden, gar nicht notwendig ist. Häufig wird es nur als zusätzlicher Aufwand empfunden, der noch dazu negative Auswirkungen auf die Performanz hat, insbesondere wenn auf Caching verzichtet wird. Statt in solchen Fällen von vornherein festzustellen, dass keine lose Kopplung benötigt wird und somit REST auch der falsche Stil ist, wird einfach die aktuelle Hypelösung genommen, ohne sie in Frage zu stellen.
Dabei spricht nichts dagegen, auf Basis von REST einen angepassten Stil zu entwickeln, der den eigenen Anforderungen gerecht wird. Denn REST bietet neben loser Kopplung noch andere Vorteile, die man vielleicht durchaus nutzen will. Nur sollte man dann so ehrlich sein und es nicht REST nennen.
Ein weiteres Problem ist, dass sowohl der Client als auch die Dokumentation beim Thema Hypermedia in der Regel vollkommen ignoriert werden, denn Hypermedia ist eigentlich eine Frage des Clients. Wenn der Client nur URI-Muster nutzt, um seine Requests zu konstruieren, dann ist es mit der losen Kopplung nicht weit. Allerdings bringt es wenig, wenn ein Server zwar Links in seine Repräsentationen einbaut, diese aber weder die Ansprüche des Clients erfüllen noch vom Client genutzt werden.
Selbst wenn ein Server Links in den Repräsentationen anbietet, bilden diese häufig nur Beziehungen zwischen Ressourcen ab, also z. B. zwischen einer Bestellung und dem Kunden. HATEOAS bezieht sich aber vor allem auch darauf, Links anzubieten, die dem Client zeigen, ob und wie er den Anwendungszustand ändern kann, also zum Beispiel eine Bestellung stornieren oder ändern. Dass Clients in der Regel nicht hypermediabasiert entwickelt werden, ist nicht weiter verwunderlich und liegt sicherlich daran, dass die meisten Dokumentationen URI-Muster als zentrales Element nutzen. Dabei sollten die zentralen Elemente einer Dokumentation die Ressourcen und ihre Verknüpfung und Linkrelationen sein. Zudem gibt es heute schon einige Hypermediaformate, wie HAL oder Siren, die einem bei dem Entwurf von Hypermediarepräsentationen helfen.
Beim Entwurf der Schnittstelle sollte man sich auch darüber im Klaren sein, dass REST auf die Übertragung größerer Nachrichten ausgelegt ist und weniger auf viele kleine, was leider gerade bei SPAs öfter vorkommt. Dieser Nachteil wird zwar durch HTTP/2 etwas gemindert, allerdings auch nicht ganz ausgeräumt.
Nichtsdestotrotz ist das durch diese Entwurfsrichtlinie vorgegebene Schnittstellendesign sicherlich ein wichtiges Element, das zum Erfolg von REST beiträgt. Hat man einmal verstanden, wie man mit der feststehenden Menge an Verben verschiedene Szenarien abbildet, sind der Entwurf und auch das Verstehen eines API nicht mehr schwer, und es verbessert somit auch die Entwicklung und Wartung. Ob man jedoch HATEOAS als Richtlinie für seine Server-Client-Kommunikation wählt oder nicht, hängt vom Anwendungsfall ab. Nur sollte man sich eben der Konsequenzen bewusst sein und das Kind beim richtigen Namen nennen. Damit wird auch klar, dass es sich bei REST um mehr als nur ein Schnittstellendesign handelt. Bei der Entwicklung müssen auch weitere Aspekte der Kommunikation sowie die Implementierung des Clients berücksichtigt werden, die wiederum in der Regel durch die Dokumentation beeinflusst wird.
Layered System: in Schichten bauen
Die Entwurfsrichtlinie Layered System bezieht sich nicht auf die Anwendungsarchitektur, sondern vielmehr auf die System- und Netzwerkarchitektur, in der Elemente wie Caches und Load Balancer eingesetzt werden können. Jede weitere Schicht – von Caches abgesehen – führt in der Regel zu einer schlechteren Performanz. Auch können Schichten die Sicherheit verbessern und die Umsetzung vereinfachen. So werden z. B. oft HTTPS-Verbindungen am Load Balancer terminiert, sodass die Zertifikate auch nur dort vorhanden sein müssen und im internen Netz HTTP gesprochen werden kann. Insbesondere durch die standardisierte Schnittstelle können Caches auch wesentlich effektiver arbeiten, da sie die Semantik des Requests zu einem gewissen Maß verstehen. So kann beispielsweise ein Cache, der einen erfolgreichen DELETE-Request auf eine Ressource mitbekommt, die zugehörige Repräsentation bei sich löschen.
Code on Demand ist optional
Code on Demand, heutzutage in der Regel mit JavaScript umgesetzt, dient dazu, den Client um Funktionalität zu erweitern. Allerdings sollte diese Entwurfsrichtlinie als optional angesehen werden, da sie einige Nachteile mit sich bringt. Nicht alle Clients, beispielsweise Crawler, unterstützen dieses Feature und verhalten sich zudem unterschiedlich. Auch verringert Code on Demand häufig die Sichtbarkeit der Client-Server-Interaktion, da der Server nicht mehr nur Daten, sondern auch Code schickt, was gleichzeitig auch die Frage nach Sicherheit aufwirft, wenn der Server nicht vertrauenswürdig ist. Umgekehrt kann natürlich der Server nicht darauf vertrauen, dass der Client den Code überhaupt oder korrekt ausführt. Auf der anderen Seite kann Last vom Server auf die Clients verteilt werden, was zu einer Verbesserung der Performanz führt. Allerdings sollte man sich bewusst sein, dass man sich nicht auf clientseitiges JavaScript verlassen sollte. Im Fall von internen Anwendungen, bei denen z. B. gesicherte Annahmen über Clients getroffen werden können, sieht die Sache schon wieder anders aus als bei öffentlich zugänglichen Webanwendungen.
Modern muss es sein
Doch wie soll man heutzutage eine Webanwendung ohne JavaScript entwickeln? Ganz im Gegenteil gewinnt man heute oft den Eindruck, dass man für eine moderne Webanwendung unbedingt eine SPA nutzen muss, die ohne JavaScript in der Regel zu nicht viel mehr als einer leeren Seite führen würde. Aber selbst wenn wir akzeptieren würden, dass JavaScript auf allen Clients ohne Fehler und Übertragungsprobleme ausgeführt werden kann, bringen JavaScript-lastige Anwendungen einige Nachteile mit sich.
Häufig werden SPAs von Teams entwickelt, die bisher primär mit Java oder C# serverseitige Anwendungen oder Backends entwickelt haben und jetzt eine moderne Webanwendung entwickeln wollen. Doch leider enthält das für SPAs notwendige JavaScript, vor allem auch aufgrund seines Umfangs, viele Stolpersteine. Deswegen kommt es schnell zu schwer wartbaren und instabilen Anwendungen. Zudem kommt hinzu, dass die SPA in der Regel komplexe Zustände enthält, die von verschiedenen Bestandteilen verändert werden. Dies erschwert ebenfalls das Aufspüren und Beheben von Fehlern. Auch fehlt heutzutage den meisten Teams noch die Erfahrung mit langlebigen SPAs.
Außerdem wird dabei auch oft vernachlässigt, dass die gesamte SPA im Client ausgeführt wird und die von ihr übertragenen Daten somit auf keinen Fall vertrauenswürdig sind. Das bedeutet, dass jegliche Validierungslogik auf jeden Fall auf dem Server vorhanden sein muss. Um dem Benutzer allerdings schnell Rückmeldung geben zu können, wird die Logik in der Regel in der JavaScript-Implementierung dupliziert.
Eine typische Anforderung ist: „Es darf keine Full-Page-Reloads geben“. Zudem wird automatische Formularvalidierung beim Tippen oder automatische Vervollständigung als Selbstverständlichkeit gesehen. Doch wie soll das ohne JavaScript gehen? Gar nicht! Aber es geht ohne SPAs und vor allem so, dass die Anwendung auch bei nicht verfügbarem JavaScript noch funktioniert. Das zugrunde liegende Prinzip nennt sich Progressive Enhancement und in Bezug auf JavaScript dann Unobtrusive JavaScript. In Kombination mit einem REST-konformen Server sind diese Entwurfsrichtlinien unter dem Begriff Resouce-oriented Client Architecture (ROCA) zusammengefasst [1], [2].
ROCA: einfach bleiben
Die Idee hinter ROCA ist, die Kernfunktionalität mit den jeweils einfachsten Mitteln abzubilden: in der Regel HTML. Für die Beschreibung des Aussehens wird CSS genutzt und auch hier interpretiert der Browser nur diejenigen CSS-Elemente, die er unterstützt, und ignoriert alle anderen. Browser sind in vielerlei Hinsicht gute Clients. Zusätzliche Funktionalität, die den Komfort für den Benutzer erhöht und sich nicht nur mit HTML und CSS umsetzen lässt, wie Autovervollständigungen oder Kalender für die Datumsauswahl, wird dann mit JavaScript ergänzt. Sollte das JavaScript nicht funktionieren, präsentiert der Browser dem Benutzer das Standardeingabefeld für ein Datum oder Text.
Die Implementierung einer einzelnen Funktionalität wird dabei als Komponente bezeichnet. Die Schnittstelle einer Komponente ist in der Regel das zugehörige HTML-Mark-up. Der Vorteil solcher Komponenten ist, dass diese voneinander unabhängig entwickelt und getestet werden können. Aber nicht nur solche kleineren Komponenten lassen sich nach dem Prinzip von Progressive Enhancement umsetzen, auch das Verhindern von Full-Page-Reloads ist damit möglich (z.B. pjax oder smoothState.js). Eine Auswahl an solchen Komponenten findet sich auf der ROCA-Webseite.
Neben den Verbesserungen für den Benutzer hat dies auch Vorteile aus Entwicklersicht und in Bezug auf Sicherheit. Die eigentliche Basisfunktionalität und Logik wird weiterhin auf dem Server, wenn möglich auch REST-konform, entwickelt und ist somit durch die Zustandslosigkeit und die klaren Vorgaben für das Schnittstellendesign auch leicht verständlich. Einzelne Komponenten können dabei wiederverwendet und beliebig kombiniert werden. Zudem sind sie in der Regel relativ klein und damit leicht zu warten und zu testen.
Sicherlich gibt es Anwendungen, die einen komplexen Zustand auf dem Client benötigen, zum Beispiel Bildeditoren oder Ähnliches, und man kann auch mit SPAs wartbare Anwendungen entwickeln, die eigentlich keinen Zustand benötigen, aber es gibt mit ROCA eben auch eine Alternative, die man in Betracht ziehen sollte.
Fazit
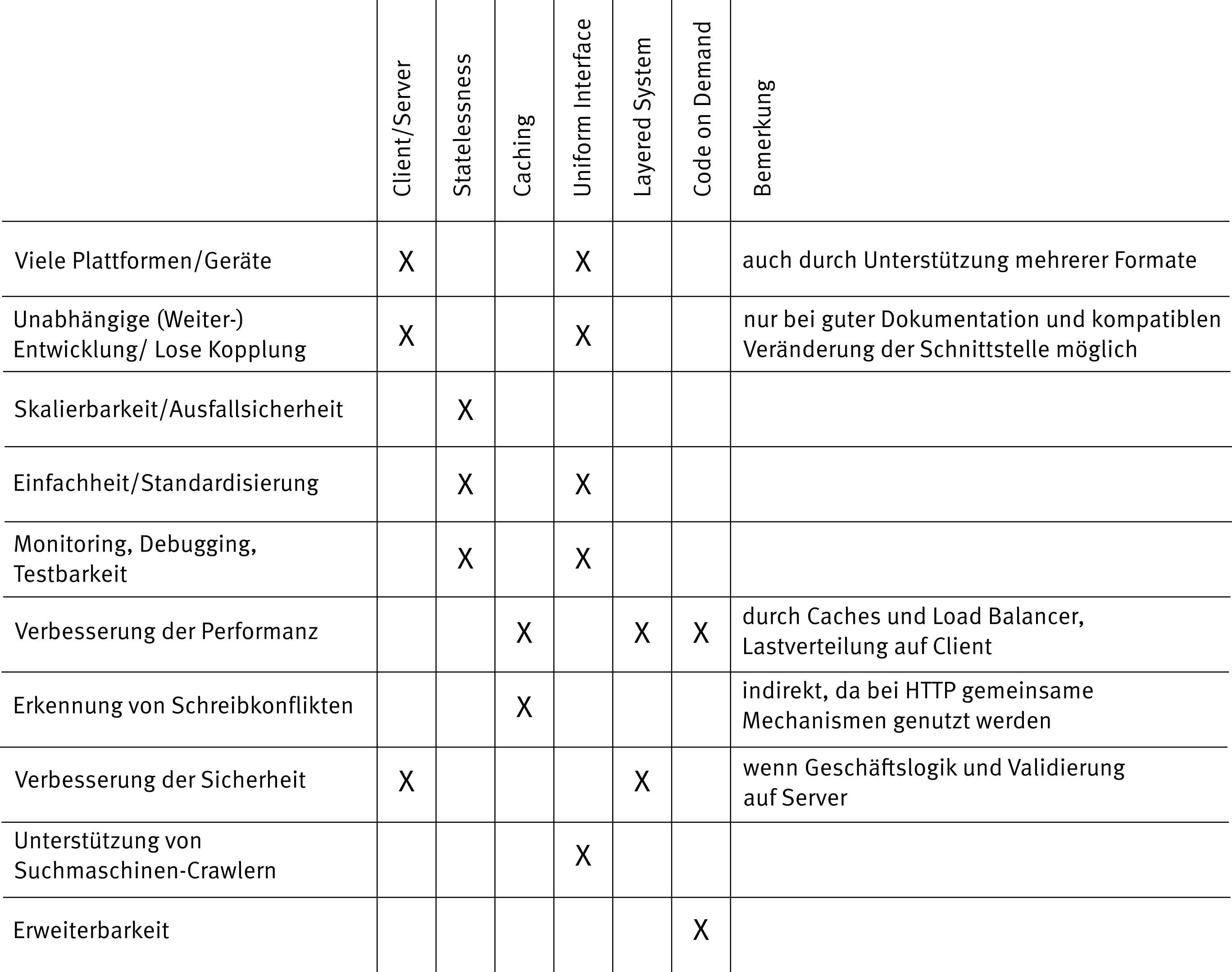
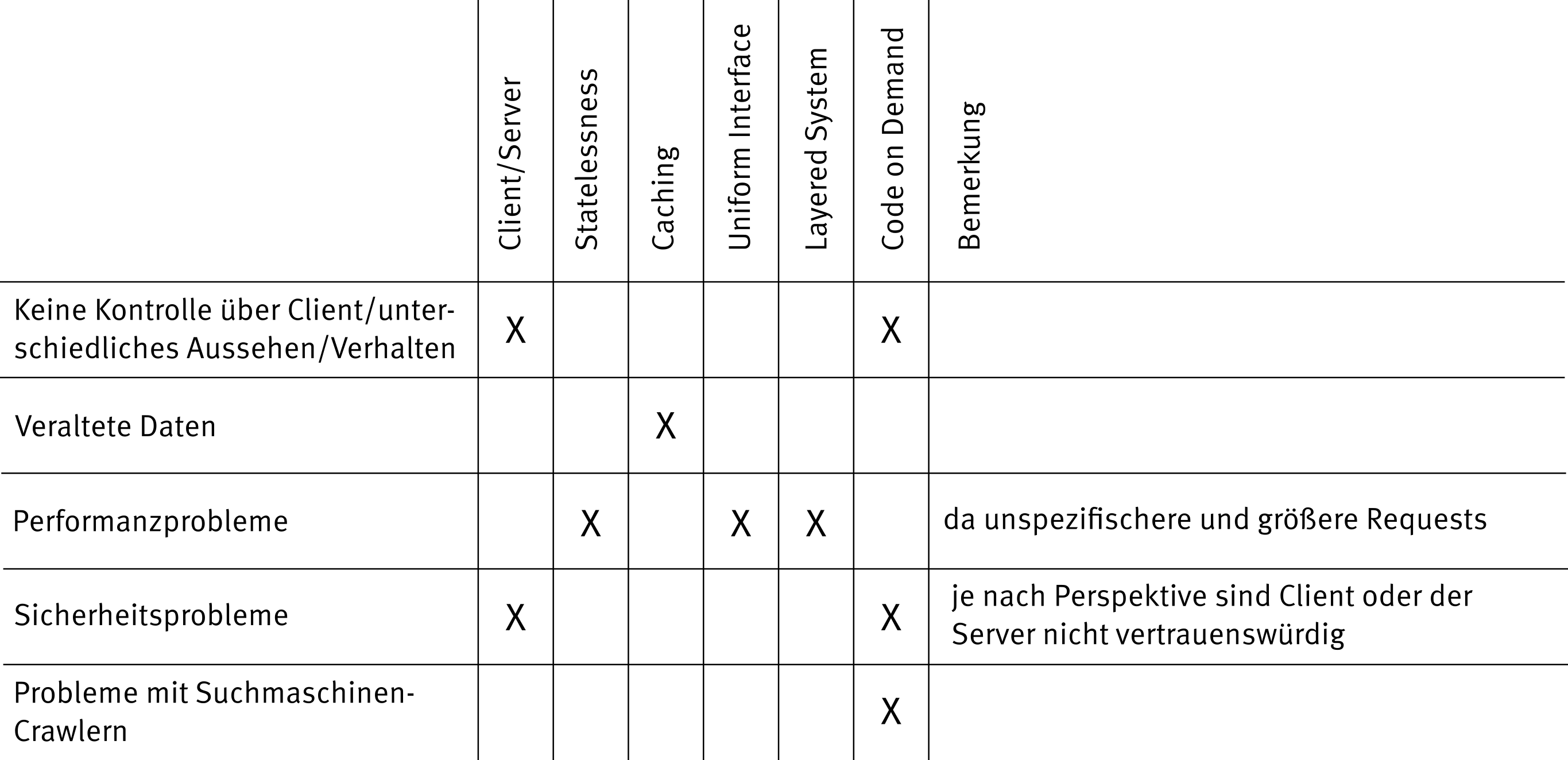
Bei jeder Architekturentscheidung müssen wir Kompromisse eingehen. So bringt REST neben vielen Vorteilen auch Nachteile mit sich, z. B. in Bezug auf die Effizienz. Da wir durch die Zustandslosigkeit in der Regel mehr Daten mitsenden müssen. Durch Caching wiederum gehen wir ein Risiko in Bezug auf die Aktualität der Daten ein. Einen Überblick über die verschiedenen Eigenschaften einer REST-konformen Architektur und die beteiligten Entwurfsrichtlinien geben dabei Tabelle 1 und 2.
Durch den Vorteil, dass bei dieser Architektur keine Clientimplementierung vorgegeben und die Anwendung somit in der Regel auf vielen Clients verfügbar ist, verliert ein Server aber auch die Kontrolle über das genaue Geschehen im Client. Wir wissen nicht, welche Features jeder Client genau unterstützt und wie die Darstellung jeweils aussehen wird. Genau dieser Einschränkung sollte man sich bewusst machen und stattdessen darauf abzielen, bei allen Clients das bestmögliche Ergebnis zu erreichen. Dieser Kompromiss gilt sowohl für das Aussehen als auch für in JavaScript implementierte Funktionalität. Das heißt nicht, dass das Aussehen und die User Experience vernachlässigt werden sollten. Aber man sollte sich der Einschränkungen bei der Nutzung einer so großen Bandbreite an unterschiedlichen Clients bewusst sein. Auch die unterschiedliche Qualität der Anbindung verschiedener Clients sollte dabei nicht außer Acht gelassen werden. Genau diese Ideen stecken hinter ROCA und ermöglichen es, moderne Webanwendungen ohne SPAs zu entwickeln.
Ich behaupte nicht, dass REST und SPAs keine Daseinsberechtigung haben, aber trotzdem sollte man sich die Frage nach den Gründen für diese Architekturvarianten stellen, um somit auch früh Hinweise für mögliche Probleme oder Schwachstellen zu erhalten. Dabei ist es natürlich auch hilfreich, Alternativen zu kennen. Ziel sollte es also nicht sein, eine Architektur auf Grund des aktuellen Hypes zu wählen, sondern weil sie zu nachhaltiger Qualität des Systems führt, unter anderem in Hinblick auf Sicherheit, Wartbarkeit, Erweiterbarkeit, Langlebigkeit und Stabilität. Dabei sollte man auch nicht die vorhandene Expertise des jeweiligen Teams vernachlässigen.