Javascript + ActiveRecord + ActiveResource
Dieses Wochenende stand wieder einmal ganz im Zeichen des freien Programmierens und ich muss sagen, dass ich mit den Ergebnissen doch ganz zufrieden bin.
Der Hintergrund: Ich hatte schon länger ein angefangenes Projekt mit unter anderem einem vollständig in JavaScript implementierten Verfügbarkeitsplaner für vermietete Gegenstände (siehe Bild).
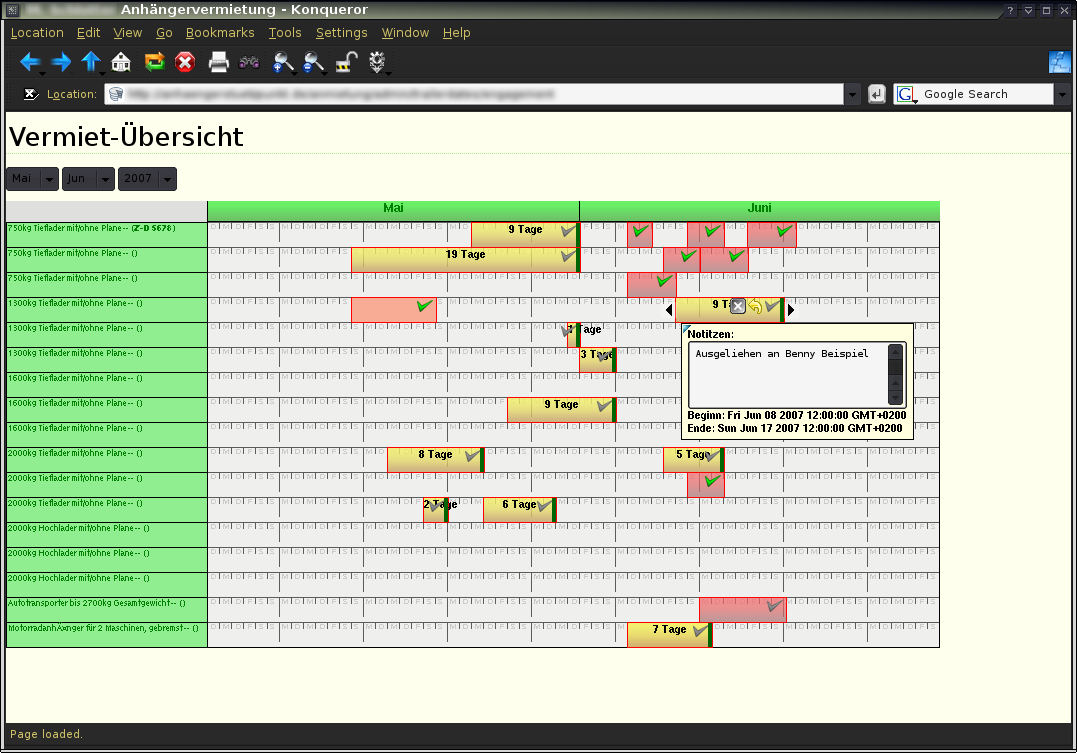
Die Implementierung dieses Planers umfasste rund 800 Zeilen Code, im wesentlichen war das eine gigantische Planer-Klasse und zwei kleinere, jeweils für die Repräsentation eines vermieteten Gegenstandes sowie dessen (Nicht-)Verfügbarkeitszeiträumen. Das alles war nicht sonderlich aufgeräumt und insbesondere was die Verwendung von Event-Handlern betraf alles andere als einfach erweiterbar. Deswegen sollte das neu geschrieben werden.
Die Vorarbeit: Am Samstagmorgen hatte ich "eben schnell" das in PHP geschriebene serverseitige Backend neu in Rails implementiert und dadurch auch eine schöne REST-Schnittstelle erhalten. Anschließend ging es darum, die serverseitigen Ressourcen 1:1 auf Clientseite abzubilden. Rails bietet hervorragende Voraussetzungen dazu: im Controllercode erweitert man seine respond_to-Blöcke einfach um ein format.json { render :text => @obj.to_json }.Statement. Dann kriegt der Client beim Aufruf von beispielsweise /clients/2.json die Repräsentation eines Client"-Objektes als JSON (JavaScript Object Notation) geliefert, was sofort evaluiert werden kann und dann als Javascript-Object zur Verfügung steht. Aber: was ist mit Assoziationen? Was mit dynamischem Nachladen von Objekten? Objekt-Caching etc.?
Der Plan: Also ward die Idee geboren, eine Art Mischung aus ActiveRecord und ActiveResource in Javascript zu implementieren. das prototype.js-Framework bietet eine hervorragende Grundlage für solche Unterfangen, und ist mit seiner (nicht ganz zufälligerweise) an die RoR-Idiome angelehnte Namensgebung auch sehr angenehm zu verwenden. Das Ziel sollte nun sein, mit Hilfe von prototype.js ein kleines Framework zu schreiben, eine ähnlich minimalistische Klassendefinition erlauben würde wie ActiveRecord bzw, ActiveResource, inklusive der Generierung von Methoden zur Handhabung der Assoziationen.
Um eine lange Geschichte etwas zu kürzen, werde ich an dieser Stelle nicht konkret auf die Implementierung der ganzen Geschichte eingehen, sondern das in einem späteren Post tun. Hier erstmal ein Beispiel:
// ActiveResource.inherit ist die "magische" Methode, die jede Menge Code generiert...
var Trailer = ActiveResource.inherit({
// ein paar Assoziationen:
has_many: {
'rental_periods': {},
'occupations': {
resource: 'occupation_dates',
}
},
has_one: {
'owner': {
'class_name': 'TrailerOwner',
'resource': 'people'
}
},
// der Name der Ressource auf dem Server
resource: 'trailers'
});
Folgende Methoden stehen nun zur Verfügung:
// holt sich das Trailer-Objekt (synchron) mit der ID 'id' und schreibt es nach {tr}
var tr = Trailer.findOne(id);
// holt sich alle Trailer-Objekte (synchron) vom Server und schreibt sie nach {trs}
var trs = Trailer.findAll();
// holt Trailer {id} asynchron vom Server und übergibt das Resultat der Callback-Methode
Trailer.findOne(id, callback);
// dito für alle Trailer-Objekte
Trailer.findAlll(callback);
// liefert nach obiger Definition "/trailers"
var url = Trailer.resource_url();
// liefert nach obiger Definition "/trailers/{id}"
var url = Trailer.element_url(id);
// liefert nach obiger Definition "/trailers/{trailer_id}/rental_periods"
var url = tr.rental_periods_url();
// liefert nach obiger Definition "/trailers/{trailer_id}/rental_periods/{id}"
var url = tr.rental_period_url(id);
// liefert nach obiger Definition "/trailers/{trailer_id}/occupation_dates/{id}"
var url = tr.occupation_url(id);
...
// holt das OccupationDate-Objekt mit der ID {id}
var oc = tr.occupation(id);
// holt das Owner-Objekt
var ow = tr.owner();
...
Alle Objekte, die (synchron oder asynchron) vom Server geholt werden, werden in einem internen Cache zwischengespeichert. Momentan greift der Cache nur beim lesen von Einzelobjekten, sprich ein Aufruf von Trailer.rental_periods() würde immer einen HTTP-Request an den Server schicken. Aber daran wird noch gearbeitet :)
Auch ist das Speichern von Objekten noch nicht möglich, aber die Implementierung der Funktionalität dürfte nur unwesentlich mehr als 30 Minuten in Anspruch nehmen...
Die mittels ActiveResource.inherit() generierte "Klasse" (Javascript kennt ja keine wirklichen Klassen, sondern arbeiten Prototyp-basiert) kann ohne weiteres mit der von prototype.js bereitgestellten Methode Object.extend() um weitere Methoden erweitert werden. Auch kann die "Vererbungs"-Methode Class.create(Elternklasse, Kindsklasse) angewendet werden. (Genau genommen tut ActiveRecord.inherit() genau dies: Es erstellt eine neue Kindsklasse mit Class.create(ActiveRecord, MeineKlasse) und erweitert MeineKlasse mit den diversen assoziationsbezogenen Methoden). Es ist auch möglich, Kindsklassen von einer von ActiveResource erbenden Klasse zu erstellen und diese wiederum mit Assoziazionsdefinitionen zu versehen. Allerdings nicht mit Class.create(), sondern wiederum mit ActiveResource.inherit():
var Trailer = ActiveResource.inherit({
resource: 'trailers'
has_many: {...},
has_one: {...},
});
var TruckTrailer = ActiveResource.inherit(Trailer, {
resource: 'truck_trailers',
has_many: {...}
});
Es ist theoretisch sogar möglich, beliebige "Klassen" mit der ActiveResource-Funktionalität "nachzurüsten":
var Person = Class.create({...});
var Person = ActiveResource.inherit(Person, {...definitionen der Ressourcen...});
Aber das ist eher eine akademische Überlegung, getestet hab ich das nicht ;-)
Den Quelltext findet ihr, meine werten Leser, hier: active_resource.js. In einem nächsten Post erzähle ich dann mehr zur internen Funktionsweise des Codes. Stay tuned!