
In my last project, we decided to refactor the inner structure of one of our services. The structure we had at this point was a mess. It had evolved more or less uncontrolled over time, with no clear idea of how it should look. There were lots of unexpected dependencies between all different parts of the system. Our goal was to transform it into a Hexagonal Architecture, especially to decouple the domain from the infrastructure, identify and separate logical modules, and overall clean up the dependencies.
It was clear that this was no task that could be done within a couple of days. We expected to work on it for a long time, probably along with the regular maintenance and feature development. During this long-running refactoring, we wanted to make our progress visible. Where are we now? What did we already have achieved? What do we still have to do? Following I describe the approach we took and how it helped us with our task.
To visualize the progress, we used jQAssistant – a structural software data analysis framework written in Java. jQAssistant scans various kinds of software-related data of a software system (e. g. source code along with some other data like test reports or version control data). It also applies several pre-defined concepts (e. g. Maven artifacts, Java packages, Java types) and derives relationships between those (e. g. depends on, contains, implements). jQAssistant stores these structural data in a Neo4j graph database. Using it within a software project, further project-specific concepts and – most important – constraints can be defined. Constraints are the rules that determine what isn’t allowed in a software system. jQAssistant evaluates the constraints and reports violations that might have occurred.
jQAssistant can be integrated into a Maven build as a plugin. It uses an AsciiDoc file that, besides of some textual documentation, contains the project-specific concept and constraint definitions. Both are defined using the Cypher query language. A concept is defined by a Cypher query that matches some already existing nodes or relationships and either extends them (set attributes, add labels) or uses them to derive and insert (merge) new nodes/relationships representing the concept. A constraint is defined by a query that matches those nodes/relationships that violate a project-specific rule. If the constraint query returns no result the rule/constraint is fulfilled. Otherwise, it is violated.
I will explain the first couple of Cypher queries in this blog post to give you a brief introduction to the query language. If you don’t know Neo4j and Cypher at all it’s maybe a good idea to have a look at the Neo4j Cypher manual before you continue reading.
Constraints can have different levels of severity (default is MAJOR). Depending on the severity, an identified violation breaks the build or it is just reported as a warning. As we knew that we would have a lot of constraint violations at the beginning and it would take some time to resolve them step by step, we had to adjust the default configuration to not breaking the build. Configuring the Maven plugin (<failOnSeverity>FATAL</failOnSeverity>) did not work in our case (seems to be a bug). So we had to set the severity of every single constraint to MINOR.
At the end of the build, a report can be created by running the jqassistant:report task of the maven plugin. The report is based on the AsciiDoc file and includes the results of all concept and constraint definition queries.
Adding some (missing) basic concepts
jQAssistant already comes with a lot of pre-defined concepts. Some examples:
- The
Artifactconcept labels theMainandTestartifacts of our project as well as all referenced 3rd party dependencies (libraries). - The
PackageandTypeconcepts create (besides labeling Java packages and Java types) also their relationships (Artifact -CONTAINS-> PackageandPackage -CONTAINS-> Type).
Additionally, we added some more basic concepts that we were missing.
We wanted our analysis to focus only on the production part of our service, not on the tests. We were mainly interested in the dependencies between packages, as they should represent our modules. To simplify the definition of our project-specific concepts and constraints, we introduced the main package concept, which labels all packages that belong to the main artifact of our project. To define this concept we added the following section containing the corresponding Cypher query to the AsciiDoc document:
[[structure:MainPackageConcept]]
[source,cypher,role=concept]
----
MATCH (:Main:Artifact)-[:CONTAINS*]->(p:Package)
SET p:Main
RETURN DISTINCT p as MainPackage
ORDER BY p.fqn
----The query matches the node labeled as Main and Artifact. It then follows all its CONTAINS relationships that refer
(directly or transitive) to Package nodes (referred to by variable p). It adds the Main label to those Package
nodes and returns them, ordered by their fully qualified name.
All classes in our project are located within a root package. To be able to exclude the packages outside of the root package from all further analysis and reports, we introduced the root package concept.
[[structure:RootPackageConcept]]
[source,cypher,role=concept,requiresConcepts="structure:MainPackageConcept"]
----
MATCH (p:Main:Package{fqn:'com.innoq.ourproject'})
SET p:Root
RETURN p as RootPackage
----This query matches the Main Package node with the fully qualified name com.innoq.ourproject, adds the Root label
and returns it.
To be able to focus on the dependencies between our packages, we finally introduced the package dependency concept. A package ‘A’ depends on a package ‘B’ if package ‘A’ contains a type that depends on a type in package ‘B’.
[[structure:PackageDependencyConcept]]
[source,cypher,role=concept,requiresConcepts="structure:MainPackageConcept"]
----
MATCH (p1:Package:Main)-[:CONTAINS]->(t1:Type),
(p2:Package:Main)-[:CONTAINS]->(t2:Type),
(t1)-[:DEPENDS_ON]->(t2)
WHERE p1 <> p2
AND p1.fqn STARTS WITH 'com.innoq.ourproject'
AND p2.fqn STARTS WITH 'com.innoq.ourproject'
WITH p1, p2, count(*) as weight
MERGE (p1)-[d:DEPENDS_ON]->(p2)
SET d.weight = weight
RETURN p1 as Package, p2 as DependsOnPackage, d as Dependency
ORDER BY p1.fqn ASC, p2.fqn ASC
----This more complex Cypher query does the following:
- The
MATCHclause matches pairs ofMainPackagenodes (p1andp2) that directly contain (CONTAINSrelationship)Typenodes (t1andt2) wheret1depends ont2(relationship labeled withDEPENDS_ON). - The
WHEREclause excludes those records wherep1andp2refer to the same package node. Besides, it filters only those records where both package nodes represent packages of our project. - The
WITHclause aggregates the remaining records by the two package nodes along with the number of records per package tuple (weightvariable). - The
MERGEclause adds a newDEPENDS_ONrelationship between the two package nodes. - The
SETclause adds the aggregatedweightas an attribute to the new relationship. - The
RETURNclause returns the two package nodes along with the new relationship ordered by the fully qualified names of the two packages.
All remaining Cypher queries shown in this blog post use more or less the same language features. I assume they are self-explaining and I won’t continue the detailed description of each query. If you need some more details on certain features, please refer to the Neo4j Cypher manual for comprehensive documentation of the language.
Adapter concepts and constraints
In the Hexagonal Architecture, adapters form the outer layer. They represent interfaces to the outer world of our application. An interface can be an API, a UI, or something communicating with a database or an external system. The Hexagonal Architecture differentiates primary (active, driving) adapters, which are called from the outer world and trigger some processing within the application (API, UI), and secondary (passive, driven) adapters, which are called by the application to do the processing (database, external systems).
In our target package structure, we wanted all primary adapters to be located in the adapter.primary package, having one separate subpackage for each adapter. In the same way, we wanted to have all secondary adapters located in the adapter.secondary package.
To identify all packages and types that belong to an adapter, we defined the concepts adapter package and adapter type.
[[structure:AdapterPackageConcept]]
[source,cypher,role=concept,requiresConcepts="structure:RootPackageConcept"]
----
MATCH (:Root:Package)-[:CONTAINS]->(r:Package{name:'adapter'})
SET r:Adapter
RETURN r as AdapterPackage
UNION ALL
MATCH (:Root:Package)-[:CONTAINS]->(:Package{name:'adapter'})-[:CONTAINS*]->(p:Package)
SET p:Adapter
RETURN p as AdapterPackage
ORDER BY p.fqn ASC
----[[structure:AdapterTypeConcept]]
[source,cypher,role=concept,requiresConcepts="structure:AdapterPackageConcept"]
----
MATCH (:Adapter:Package)-[:CONTAINS]->(t:Type)
SET t:Adapter
RETURN t as AdapterType
ORDER BY t.fqn ASC
----The adapter module concept labels the separate adapters. As we decided to bundle two different API adapters (internal and external) into an intermediate package api we were not able to define a generic query matching all direct sub-packages of adapter.primary and adapter.secondary. However, we used the UNWIND clause to provide the module names along with the corresponding packages as a list of variables and so we were able to keep the remaining part of the query generic.
[[structure:AdapterModuleConcept]]
[source,cypher,role=concept,requiresConcepts="structure:AdapterPackageConcept"]
----
UNWIND [
{ name: 'Internal API', package: 'com.innoq.ourproject.adapter.primary.api.internal' },
{ name: 'External API', package: 'com.innoq.ourproject.adapter.primary.api.external' },
{ name: 'UI', package: 'com.innoq.ourproject.adapter.primary.ui' },
{ name: 'Some External System', package: 'com.innoq.ourproject.adapter.secondary.someexternalsystem' },
{ name: 'Database', package: 'com.innoq.ourproject.adapter.secondary.database' }
] AS modules
MATCH (p:Adapter:Package{fqn:modules.package})
SET p:Module
SET p.moduleName = modules.name
RETURN p.moduleName as AdapterModule
----Based on those concepts, we were able to define our first constraint: an adapter must not depend on another adapter.
[[structure:AdapterMustNotDependOnOtherAdapterConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:AdapterModuleConcept,structure:AdapterTypeConcept",severity="MINOR"]
----
MATCH (a1:Adapter:Module)-[:CONTAINS*]->(t1:Adapter:Type),
(a2:Adapter:Module)-[:CONTAINS*]->(t2:Adapter:Type),
(t1)-[:DEPENDS_ON]->(t2)
WHERE a1 <> a2
RETURN t1 as AdapterType, t2 as DependsOnAdapterType
ORDER BY t1.fqn ASC, t2.fqn ASC
----Application concepts and constraints
The next layer of a Hexagonal Architecture is the application layer. It provides a unique API of the application which can be used by the different (primary) adapters. It handles some application-specific logic, e. g. authorization and orchestration of the inner domain logic.
In our target package structure, all application logic should be located in a package application and may be further structured into sub-packages.
In the same way as for the previously described adapters, we defined an Application Package and Application Type concept. I skip the definition because it’s almost the same as for the adapter concepts.
The only application constraint we defined is also very similar to the adapter one. It reports unallowed dependencies on the outer adapter layer: application must not depend on an adapter
[[structure:ApplicationMustNotDependOnAdapterConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:ApplicationTypeConcept,structure:AdapterTypeConcept",severity="MINOR"]
----
MATCH (tAppl:Application:Type)-[:DEPENDS_ON]->(tAdpt:Adapter:Type)
RETURN tAppl as ApplicationType, tAdpt as DependsOnAdapterType
ORDER BY tAppl.fqn ASC, tAdpt.fqn ASC
----Domain concepts and constraints
The center of the Hexagonal Architecture contains the domain. It defines the business model and logic and should be free from all external dependencies.
In our target package structure, all domain classes should be located in the domain package. Different logical domain modules should be represented by dedicated sub-packages.
Again, the definition of the domain package and domain type concepts are similar to the adapter ones, so I skip them.
The domain module concept labels all direct sub-packages of the domain package.
[[structure:DomainModuleConcept]]
[source,cypher,role=concept,requiresConcepts="structure:DomainPackageConcept"]
----
MATCH (:Domain:Package{name:'domain'})-[:CONTAINS]->(p:Package)
SET p:Module
RETURN p.name as DomainModule
ORDER BY p.name ASC
----For the domain we defined two constraints similar to the ones described above (so I also skip those definitions), to report dependencies on outer layers: domain must not depend on adapter and domain must not depend on application
As described above, the domain layer should be free from all external, technical dependencies. In our case, we especially didn’t want to have any JPA or JSON specific stuff in the domain classes. We defined a constraint which reports any dependencies to other than our own, the basic Java, and a few additional types that we explicitly allow in our domain: domain must not depend on 3rd party libs
[[structure:DomainMustNotDependOn3rdPartyLibsConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:DomainTypeConcept",severity="MINOR"]
----
MATCH (tDom:Domain:Type)-[:DEPENDS_ON]->(tExt:Type)
WHERE NOT tExt.fqn CONTAINS 'com.innoq.ourproject'
AND NOT tExt.fqn IN ['void', 'boolean', 'int', 'long']
AND NOT tExt.fqn STARTS WITH 'java.'
AND NOT tExt.fqn STARTS WITH 'javax.annotation.'
AND NOT tExt.fqn STARTS WITH 'org.springframework.stereotype.'
RETURN tDom as DomainType, tExt as ThirdPartyType
ORDER BY tDom.fqn ASC, tExt.fqn ASC
----Finally, we wanted to define and verify the dependencies between the different domain modules. Other than the adapter modules that must not depend on each other in general, the domain modules have to depend on each other. We introduced an allowed domain module dependency concept to define the allowed dependencies explicitly.
[[structure:AllowedDomainModuleDependencyConcept]]
[source,cypher,role=concept,requiresConcepts="structure:DomainModuleConcept",reportType="plantuml-component-diagram"]
----
MATCH (core:Domain:Module{name:"core"}),
(changelog:Domain:Module{name:"changelog"}),
(history:Domain:Module{name:"history"}),
(addressnormalization:Domain:Module{name:"addressnormalization"}),
(duplicatecheck:Domain:Module{name:"duplicatecheck"})
MERGE (changelog)-[d1:ALLOWED_DEPENDENCY]->(core)
MERGE (history)-[d2:ALLOWED_DEPENDENCY]->(core)
MERGE (history)-[d3:ALLOWED_DEPENDENCY]->(changelog)
MERGE (addressnormalization)-[d4:ALLOWED_DEPENDENCY]->(core)
MERGE (duplicatecheck)-[d5:ALLOWED_DEPENDENCY]->(core)
RETURN *
----The query returns all modules along with their allowed dependencies. We used the reportType="plantuml-component-diagram" to render a dependency diagram in the jQAssistant report instead of a plain list.
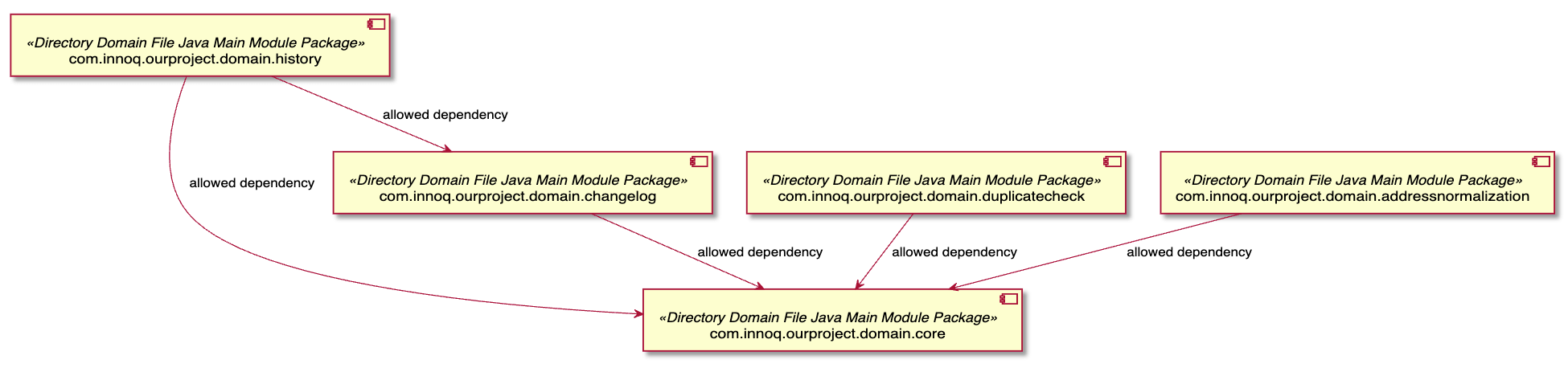
After defining the allowed dependencies we were able to introduce an allowed domain module dependency constraint that reports all other than the allowed dependencies between domain modules.
[[structure:AllowedDomainModuleDependencyConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:AllowedDomainModuleDependencyConcept",severity="MINOR"]
----
MATCH (m1:Domain:Module)-[:DEPENDS_ON]->(m2:Domain:Module)
WHERE NOT (m1:Domain:Module)-[:ALLOWED_DEPENDENCY]->(m2:Domain:Module)
WITH m1, m2
MATCH (m1)-[:CONTAINS*]->(t1:Domain:Type),
(m2)-[:CONTAINS*]->(t2:Domain:Type),
(t1)-[:DEPENDS_ON]->(t2)
RETURN t1 as DomainType, t2 as DependendsOnDomainType
----Types/packages outside the hexagonal structure
Running the so far described jQAssistant analysis before the beginning of our refactoring showed no constraint violations. All the constraints described above are based on the target package structure, which did not yet exist. So, there were no types that could violate any of the defined constraints. Everything looked perfectly fine, but we knew that this wasn’t the case. So, there was at least one constraint missing that showed us that we indeed had something to do.
We introduced a non-hexagonal types and packages constraint that reported all types that were located outside of our target domain, application, or adapter packages.
[[structure:NonHexagonalTypesAndPackagesConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:RootPackageConcept,structure:DomainTypeConcept,structure:ApplicationTypeConcept,structure:AdapterTypeConcept",severity="MINOR"]
----
MATCH (:Root:Package)-[:CONTAINS*]->(t:Type)
WHERE NOT t:Domain
AND NOT t:Application
AND NOT t:Adapter
AND NOT t.fqn = 'com.innoq.ourproject.OurProjectApplication'
RETURN t AS NonHexagonalType
ORDER BY t.fqn ASC
----Visible progress
The main jQAssistant report (located at target/jqassistant/report/asciidoc/index.html) shows all the concept and constraint definitions including the results of the corresponding Cypher queries (especially the constraint violations). There is a Summary directive available, but it only renders a short list of all the constraints showing which are fulfilled and which are violated. It does no show the number of violations.
However, the Maven Plugin generates another, more or less undocumented report for the Maven Site (located at target/site/jqassistant.html). This one contains precisely the information we wanted to see. For every constraint, it shows the number of violations. For each violated constraint even a list of the concrete violations can be opened.
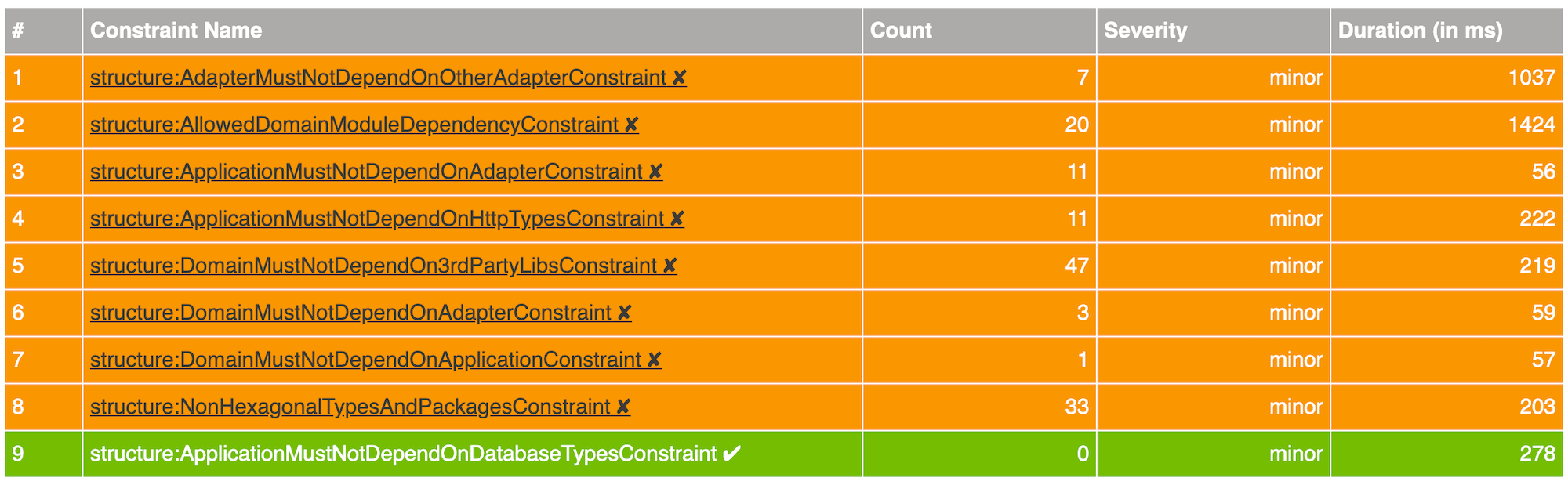
To see the progress, we created an Excel sheet. For each day, we manually added the numbers of the jQAssisant report of the last build pipeline of the day. Based on these numbers, we rendered a diagram to show our progress.
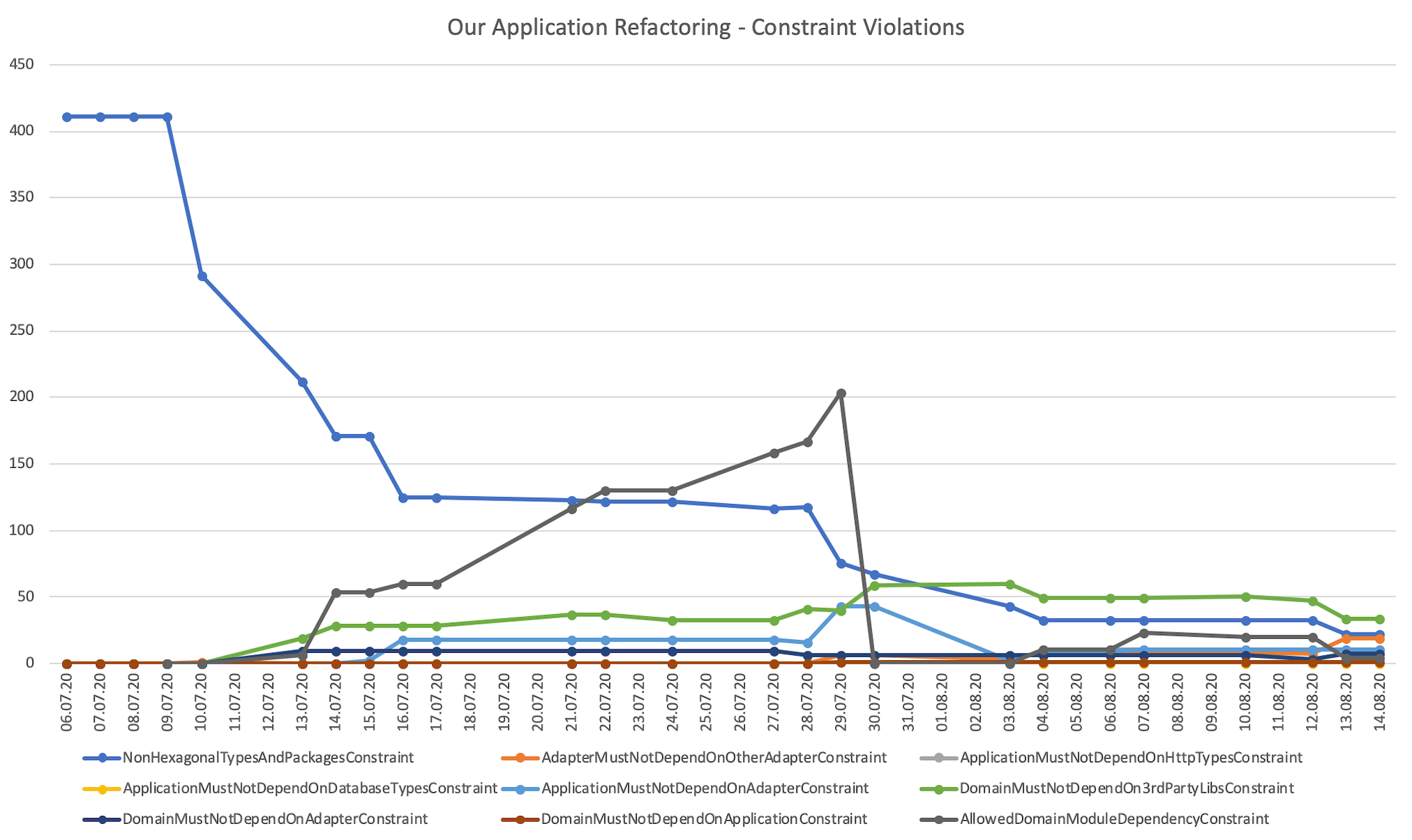
At the beginning of the refactoring, only the NonHexagonalTypesAndPackagesConstraint was violated. All other constraints are based on the dedicated hexagonal package structure that did not yet exist. So, as a first step, we moved some classes to the appropriate target packages.
As expected, the number of violations of the NonHexagonalTypesAndPackagesConstraint decreased. Instead, other, more concrete violations became visible, for example, domain types that depend on some unwanted libraries (Jackson, JPA) or dependencies to outer layers. We were now able to prioritize these violations (e. g. which module contains the most violations or which violation is the most critical one) and start resolving them.
After some time, we noticed a remarkable increase in the AllowedDomainModuleDependencyConstraint violations. Looking at the concrete violations we were able to identify two causes:
- The idea of the domain modules as direct sub-packages of the domain package was not respected so far. Instead, another package structure had evolved which was not expected by the constraint.
- The actual modules and dependencies slightly differed from the ones we had expected when we defined the constraint
After we cleaned up the package structure and adjusted the constraint, all its violations disappeared.
Adding some missing constraints
During our ongoing refactoring, we noticed that we had some application layer types with dependencies on some technical persistence or HTTP types. In a Hexagonal Architecture, this should only be the case for the corresponding adapters. So we added another two constraints to make these violations visible, too, and to be able to prioritize and address them, too: application must not depend on http types and application must not depend on database types
[[structure:ApplicationMustNotDependOnHttpTypesConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:ApplicationTypeConcept",severity="MINOR"]
----
MATCH (tAppl:Application:Type)-[:DEPENDS_ON]->(tHttp:Type)
WHERE tHttp.fqn STARTS WITH 'javax.servlet.http'
OR tHttp.fqn STARTS WITH 'org.springframework.http'
OR tHttp.fqn STARTS WITH 'org.springframework.web'
RETURN tAppl as ApplicationType, tHttp as HttpSpecificType
ORDER BY tAppl.fqn ASC, tHttp.fqn ASC
----[[structure:ApplicationMustNotDependOnDatabaseTypesConstraint]]
[source,cypher,role=constraint,requiresConcepts="structure:ApplicationTypeConcept",severity="MINOR"]
----
MATCH (tAppl:Application:Type)-[:DEPENDS_ON]->(tDb:Type)
WHERE tDb.fqn STARTS WITH 'javax.persistence'
OR tDb.fqn STARTS WITH 'org.springframework.data'
RETURN tAppl as ApplicationType, tDb as DatabaseSpecificType
ORDER BY tAppl.fqn ASC, tDb.fqn ASC
----Conclusion
jQAssistant is a good choice for making structural constraint violations visible. This is especially useful when doing a bigger and therefore longer running structural refactoring of an application. It provides an overview of the number of constraint violations and how they change over time. Having this overview, it’s possible to prioritize the different violations and focus on the most critical ones first. Starting with rather rough constraints and refine or extend them whenever more detailed structural problems are noticed allows learning on the way.
Many thanks to Markus Harrer and Robert Glaser for their feedback to this post.