
Dieser Artikel ist auch auf Deutsch verfügbar
Domain-driven Design divides large systems into bounded contexts, each of which has its own domain model. That way, they can provide a part of the domain logic largely independently. In a system for a library there could be a bounded context “borrowing” for borrowing books and another called “search” for searching. One domain model would have all the information for borrowing, such as the number of copies of a book. In the domain model for searching, the number of copies is not important, but the author or title is.
Relation between Bounded Contexts
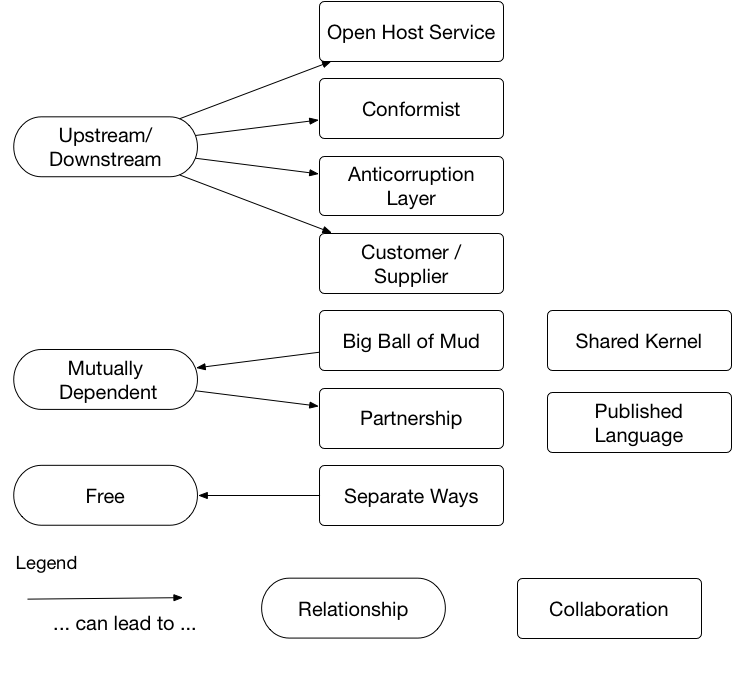
Domain-driven Design offers approaches to integrate bounded contexts (see Fig. 1). The first step is to analyze the relationship between bounded contexts. Different types of relationships are possible:
Free means that working on one bounded context has little or no effect on other bounded contexts.
With upstream-downstream, the success of the team working on the downstream bounded context depends on the team working on the upstream one. However, the upstream teams' success does not depend on the downstream team.
Mutually dependent means that teams can only successfully deploy both bounded contexts together.
Which relationship describes the situation best can be determined by analyzing the bounded contexts. This means that relationships are usually not a design decision, but the result of the split into bounded contexts.
Back to the library example: Its visitors first search for books and then borrow them. Free is out of the question when it comes to “borrowing” and “search”, because there must be a way of borrowing the found books. Therefore, the two bounded contexts must have a relationship.
The success of “borrowing” is probably given if books can be borrowed. The success of “search” probably means that readers find the books they are looking for. Visitors can only borrow a book if they have found it before. So “borrowing” depends on “search”. On the other hand, “borrowing” cannot make the team for “search” fail. Therefore “borrowing” is downstream to “search”.
The two bounded contexts are not mutually dependent: The dependency is in one direction and therefore not mutual. Even if it was: There are enough features in “search” and “borrowing” that can be developed independently of each other. For example, adding new criteria to “search” certainly has no effect on the “borrowing”. So the dependency is certainly not strong enough to call it mutually dependent.
Even though we are talking about software architecture, surprisingly the relationships are reflected primarily in the organization and coordination between the teams and not in code. Nevertheless, the relations have an impact on the software: two bounded contexts with an interface can hardly be free.
On the organizational level, the relations are a direct result of the software artifacts. When a team takes responsibility for a downstream bounded context, it gets the appropriate downstream role. Strictly speaking, it is not the team itself that has the relationship, but the bounded context passes the relationship on to the team.
Collaborations: Designing Organizations
The above relationships result from the division into Bounded Contexts: “Borrowing” is indispensable downstream of “search”. However, this has disadvantages, since lending books is the core task of a library. If other bounded contexts can have a negative impact on this central task, countermeasures are advisable to set the right priorities in the project.
The upstream-downstream relationship cannot be changed, as it is objectively present. Nevertheless, there are different ways of reacting to the upstream-downstream relationship in the organization:
- Customer-Supplier Collaboration
- Conformist Collaboration
- Anticorruption layer
- Open Host Service
In a customer-supplier collaboration, the downstream team can request features from the upstream team, which the latter implements within its capabilities. In this type of collaboration, “borrowing” could request new features from “search”. This means that “borrowing” actually has a higher priority than “search”, as it should.
Conformist collaboration is different: In this case, the downstream team adopts the upstream team’s data model and has no say in what the upstream team does. This makes integration easier, but leaves the downstream team at the mercy of the upstream team.
The decision between customer-supplier and conformist is an architecture decision. It depends on the prioritization: If the downstream team is politically powerful or is working on an important issue, it should be in a customer role. Otherwise, it may find itself in a conformist role. It might also be forced into a conformist role because the upstream bounded context is legacy code that cannot be changed any more.
Thus, an architecture decision can sometimes compensate the upstream-downstream relationship where it makes sense. Teams could force the “borrowing” into a conformist role if the prioritization is not high enough.
Another option is the anticorruption layer: Similar to conformist, the downstream team cannot really influence the upstream team, but has a layer in its system that decouples it from the upstream team’s domain model. At the collaboration level, this is the same as conformist, but there is an additional layer in the code to translate the models in the downstream bounded context.
In an open host service, there are several downstream teams that share an interface with the upstream team. The rule for interaction is that the upstream team has the final say concerning changes to the interface. Requests from downstream teams can be incorporated into the development, but the upstream team can reject requests and instead offer a separate interface to the downstream team. That way individual special requirements will not mess up the generic interface. So actually an open host service is not just a generic interface that suits the needs of some teams. Probably more important are the organizational rules that ensure that the interface stays generic and clean.
Mutually Dependent
Along the lines of the different organizational approaches to the upstream-downstream relationship, relationships that are mutually dependent can respond differently:
- Partnership
- Big Ball of Mud
In mutually dependent relationships, partnership is very often used for integration. The term initially sounds positive, but it stands for extremely close coordination, which typically leads to considerable overhead.
Another approach for the mutually dependent case is the so-called big ball of mud, which, however, is not a preferable approach for interdependent teams. The term refers to a system that encompasses several bounded contexts but is so poorly structured that practically no structure is discernible at all.
Due to the poor structure, there are many dependencies. As a result, teams that work together on a big ball of mud must coordinate closely and are therefore mutually dependent. Hardly any team consciously decides to have a big ball of mud, but it comes into being when a meaningful structuring of the system is not tackled.
The free relationship leads to complete independence and therefore to no cooperation. Therefore, it hardly seems reasonable to discuss a collaboration for free at all.
Nevertheless, there is the separate ways collaboration: If teams can integrate two bounded contexts but the effort required to do so is not reasonable compared to the benefit, they can avoid the integration completely. Interfaces that are hardly used at all may cost more money to implement than the savings they later bring in. As there is no interface, the teams working on the two bounded contexts are in a free relationship - and that is the advantage of separate ways.
Other Models for Cooperation
Furthermore, collaborations exist that do not necessarily influence relationships:
In a shared kernel, the bounded contexts share code, acceptance tests for the shared code, and a part of the database. Changes to the shared kernel require coordination. To achieve sufficient independence of the teams, the shared kernel should be small to prevent a mutually dependent relationship. Upstream-downstream is also not mandatory, since the two teams work together on the shared kernel. So not one team can hurt the other but rather both will suffer if there are problems with the shared kernel.
A published language is a common data model that is only used for communication. It can be a publicly published standard or a format explained in a Wiki. Obviously, the bounded contexts have a relationship and have to coordinate with each other, but similar to the shared kernel, the relationship is not close because it concerns only the data model for communication. Changes to this model can therefore be decoupled from changes to the internal model.
Good Relationships
Domain-driven design (DDD) is particularly useful for structuring large systems. On the one hand, DDD describes relationships that teams enter into when they have to deal with individual bounded contexts. Since the relations result from the division of the system, they cannot be influenced directly.
Therefore DDD suggests some collaborations to deal with the relations in a profitable way. By the way, the terms “relationship” and “collaboration” are not found in the DDD literature. However, they help to distinguish the two mechanisms from each other.