

Für die komplexe Infrastruktur großer Microservice-Umgebungen versprechen Service Meshes eine einfache Lösung. Aber nur mit dem Blick für die richtigen Eigenschaften lässt sich der beste Ansatz für die eigene Architektur finden.
In den letzten Jahren rückt die Infrastruktur stärker in den Fokus der Softwareentwicklung. Auslöser ist der Trend hin zu Microservices: die Unterteilung von Anwendungen in kleine, voneinander unabhängig ausrollbare Einheiten. Dieses Vorgehen bringt eine Menge Vorteile: Einzelne Services sind übersichtlicher und lassen sich daher schneller entwickeln. Die Aufteilung auf mehrere Teams gelingt besser. Die Stabilität des Systems steigt, weil der Ausfall eines einzelnen Service nicht den Ausfall des gesamten Systems bedeutet.
Damit entstehen aber verteilte Anwendungen, die mit neuen Herausforderungen kämpfen müssen: Netzwerke sind instabil, Server fallen aus oder einzelne Teile einer Anwendung sind zeitweilig nicht erreichbar. Daher werden Rollouts erheblich komplexer. Diese Aspekte direkt in den Services zu lösen, führt zu einem überraschend hohen Aufwand. Zudem machen gemeinsame Abhängigkeiten von Bibliotheken viele Vorteile unabhängiger Microservices wieder zunichte.
Service Meshes versuchen, die Infrastrukturprobleme von Microservices zu beheben, indem sie den Diensten Komponenten zur Seite stellen, die sich um die angesprochenen Herausforderungen kümmern – ohne dass der Service selbst etwas davon wissen muss. Das geschieht normalerweise über Proxys, die den Netzwerkverkehr zwischen den Services steuern. Diesen Teil eines Service Mesh nennt man die Data Plane. Da dadurch sehr viele Proxys installiert werden, wird es notwendig, diese zentral zu konfigurieren. Das übernimmt die Control Plane. Sie ist außerdem dazu in der Lage, Metriken von den einzelnen Services zu sammeln und zentral bereitzustellen. Die Control Plane fragt den aktuellen Zustand der Microservice-Anwendung regelmäßig über die APIs der zugrunde liegenden Infrastruktur wie Kubernetes, Consul oder Cloud-Provider wie AWS ab. Außerdem kann sie für alle Microservice-Instanzen automatisch Proxys hinzufügen, was die komplexe Architektur handhabbar macht.
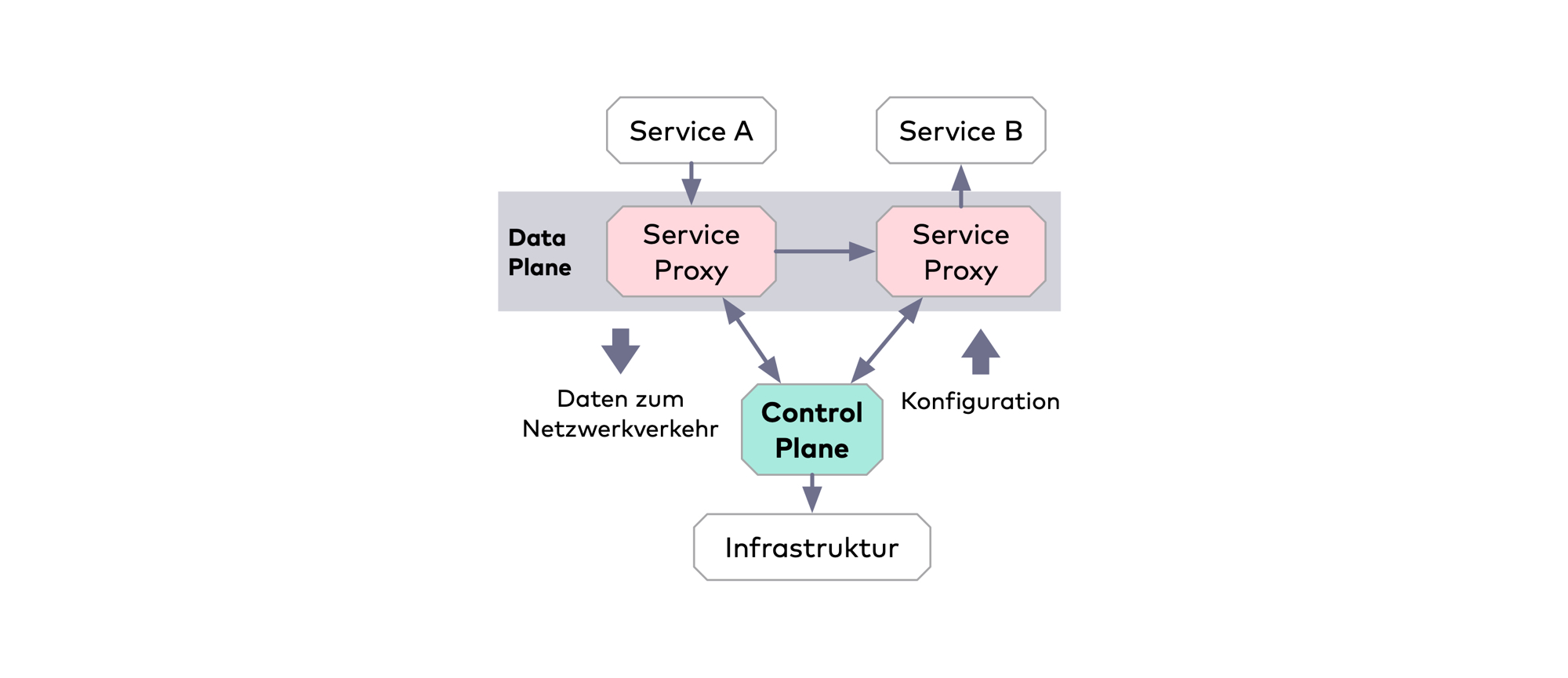
Die Idee von Service Meshes ist deswegen so verlockend, weil sie diese Herausforderungen von Microservices auf der Ebene der Infrastruktur lösen, die weitgehend unabhängig von der Anwendungslogik ist. Entsprechend viele Implementierungen sind in den vergangenen Jahren entstanden. In den vergangenen zwei Jahren erschienen neue Projekte teilweise im Monatsrhythmus.
Aktuelle Service Mesh Implementierungen
Nicht alle gestarteten Kandidaten existieren noch, dennoch ist die Liste ziemlich lang. Zu den aktuell aktiven Projekten zählen:
Linkerd 2 und sein Vorgänger Linkerd werden von Buoyant entwickelt, einer Firma von ehemaligen Twitter-Entwicklern. Motivation für die Entwicklung waren vor allem die Erfahrungen mit Microservices und dem bei Twitter entwickelten RPC-Framework Finagle. Während die erste Version von Linkerd noch völlig unabhängig von der Containerinfrastruktur entstand, setzt die zweite Version konsequent auf Kubernetes als Unterbau.
Istio ist die Fusion zweier Projekte bei Google und IBM. Ähnlich wie bei Kubernetes sollten die internen Erfahrungen in ein Open-Source-Projekt übergehen. Beim Service-Proxy fiel die Wahl auf Envoy von der Firma Lyft. Erst der Hype um Istio hat wohl zu der Entwicklung vieler anderer Service Meshes geführt. Das Projekt hat in der kürzlich veröffentlichten Version 1.5 einen technologischen Umbruch erfahren: statt einer verteilten Control Plane konfiguriert und überwacht jetzt eine monolithische Anwendung die Proxys. Ziel war eine, von der Nutzer-Community geforderte, deutliche Vereinfachung sowohl der Architektur als auch der Konfiguration.
AWS App Mesh ist Amazons Antwort auf Istio. Es setzt ebenfalls auf Envoy in der Data Plane und integriert sich AWS-typisch in die Landschaft der Cloud-Dienste von Amazon. Dabei setzt es Kubernetes nicht voraus, lässt sich aber auch innerhalb eines solchen Clusters nutzen.
Beim Thema Service Discovery ist HashiCorp Consul seit Jahren ein etabliertes Produkt. Insofern war es ein logischer Schritt, diese Infrastruktur um Funktionen eines Service Mesh zu erweitern. HashiCorp nennt das entstandene Produkt Consul Connect. Auch hier kommt typischerweise Envoy zum Einsatz, jedoch lassen sich bei Bedarf andere Proxys integrieren. Auch Consul muss nicht zwangsläufig innerhalb von Kubernetes laufen.
Die Service Meshes Kuma und Traefik mesh stammen von Firmen, die API-Gateways beziehungsweise Reverse-Proxys entwickeln. Da diese ähnliche Probleme lösen, ist die Erfahrung leicht auf Service Meshes übertragbar. Dass Istio wiederum auch einige Funktionen eines API-Gateways übernimmt, kann ebenfalls eine Motivation für die Entwickler*innen von API-Gateways sein, selbst in diesem Markt aktiv zu werden. Beide Produkte sind noch recht neu auf dem Markt. Ob sie ihren Platz neben den etablierten Playern finden, bleibt abzuwarten.
Je nach Blickwinkel unterscheiden sich Service Meshes in Bezug auf Architektur und Umsetzung, beispielsweise bei der Wahl des Proxys. Die meisten Service Meshes setzen Envoy ein. Darin sind bereits viele typische Funktionen eines Service- Mesh Proxys implementiert und durch eine umfangreiche API konfigurierbar. Andere Proxys werden aus verschiedenen Motivationen genutzt. So setzt Linkerd 2 auf eine Rust-basierte Eigenentwicklung. Hier stehen Performance und Sicherheit im Vordergrund. Traefik mesh setzt selbstverständlich auf Traefik, weil es ein wichtiges Produkt des Anbieters ist.
Große Unterschiede beim Aufbau
Die Gruppierung nach der Abhängigkeit von Kubernetes wurde oben bereits erwähnt. Hier setzt ein Teil der Meshes konsequent auf Kubernetes als Basisplattform, was das Implementieren des Service Mesh deutlich vereinfacht. Andere versuchen sich hingegen dadurch zu positionieren, dass diese Abhängigkeit nicht besteht.
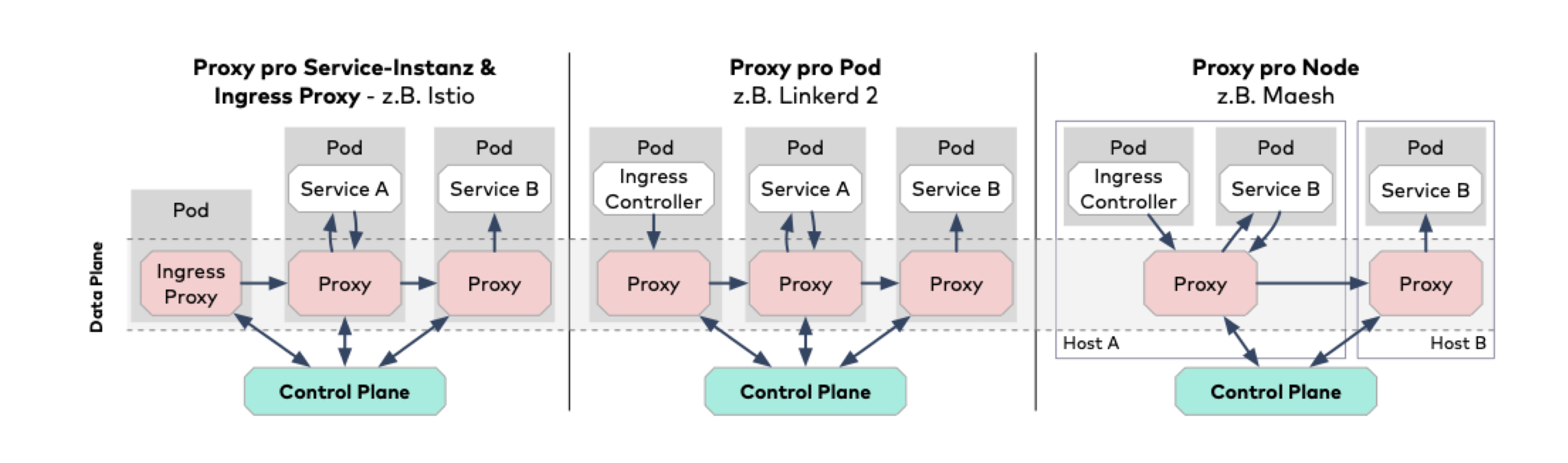
Auch das Verhältnis zwischen Microservice und dem Mesh-Proxy unterscheidet sich zwischen den Implementierungen. Viele Service Meshes ergänzen einen Proxy pro Serviceinstanz, den sie bei Kubernetes im gleichen Pod platzieren.
Bei anderen Implementierungen wie Traefik mesh existiert hingegen nur ein Proxy pro Host im Cluster. Dieser dient dann potenziell den Instanzen verschiedener Microservices. Das führt zwar zu geringerem Ressourcenverbrauch, beherrscht aber das weiter unten erläuterte Feature mTLS nicht.
Ein umgekehrtes Extrem stellt Istio dar, das sogar die Kontrolle über in den Cluster eingehende – und optional ausgehende – Verbindungen übernimmt. Dies bietet mehr Features, schränkt aber die Kompatibilität zu vorhandenen Paketen/Komponenten ein. Abbildung 2 verdeutlicht diese Unterschiede. Linkerd 2 geht hier den interessanten Weg, den Standard Ingress-Controller zu verwenden, diesem aber einen Proxy zur Seite zu stellen, wenn man die Funktionalität benötigt.
Eine Schnittstelle für alle
Angesichts der großen Vielfalt von Service Mesh Implementierungen hat sich eine Gruppe von Unternehmen, darunter Microsoft, Buoyant und HashiCorp, zusammengeschlossen, um einen gemeinsamen Standard für Service Mesh Funktionen zu schaffen: das Service Mesh Interface (SMI). Das Ziel der Spezifikation ist, dass Werkzeuge, die auf Service Mesh Funktionen basieren (beispielsweise Dashboards), mit jedem Service Mesh kompatibel sind, anstatt an eine bestimmte Implementierung gebunden zu sein. Benutzer*innen von Service Meshes sollen zukünftig davon profitieren, dass sie die Implementierung austauschen können, ohne deren Konfiguration ändern zu müssen.
Die Community hat Adapter für Istio implementiert, die vollständige Kompatibilität zum SMI herstellen. Linkerd 2, Consul und Traefik mesh setzen jeweils einen Teil der Interfaces um.
Von Äpfeln, Birnen und Features
Die Features der verschiedenen Service Meshes sind unübersichtlich. Viele Dokumentationen lesen sich wie Werbetexte und unter den Feature-Bezeichnungen verstecken sich oft ganz unterschiedliche Implementierungen. Wie entscheidet man also, welches Service Mesh für die eigenen Probleme geeignet ist?
Eine detaillierte, aktuelle Übersicht über die Features verschiedener Service Meshes liefert die Seite servicemesh.es.
](https://res.cloudinary.com/innoq/image/upload/uploads-production/bild6_2b6b4f80-a494-4c99-9f81-7a5c9dd816c7.png)
Zuerst sollte man sich im Klaren sein, welche Probleme man mit einem Service Mesh lösen möchte. Diese lassen sich in vier Klassen unterteilen: Observability, Routing, Resilience und Security. Jedes Service Mesh kann mit bestimmten Eigenschaften in diesen Klassen umgehen.
Observability
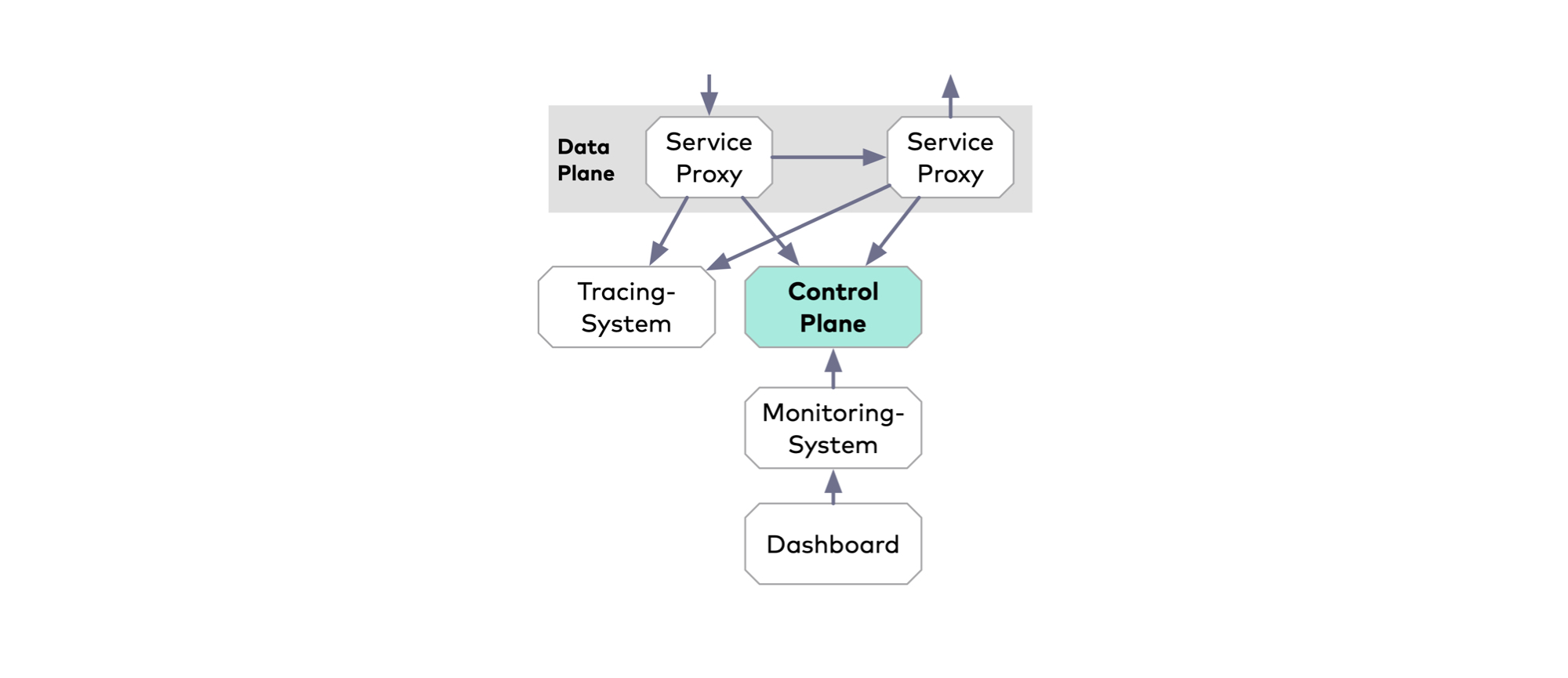
Service Meshes schaffen eine bessere Übersicht über eine Microservice-Landschaft, indem sie Informationen darüber liefern, welche Services es gibt, wie diese miteinander kommunizieren und in welchen sie sich befinden.
Die Service-Proxys zeichnen Informationen wie HTTP-Statuscode, Quell- und Zieladresse oder Antwortzeiten auf. Diese Daten werden, häufig über die Control Plane, einem Monitoringsystem wie Prometheus zur Verfügung gestellt und in Dashboards aufbereitet. Das fachspezifische Monitoring, etwa die Anzahl der Registrierungen, ist weiterhin in den Microservices zu implementieren. Außerdem können die meisten Service Meshes auch die Access Logs der Proxys für spätere Analysen bereitstellen.
Viele Service Meshes unterstützen darüber hinaus das Verfolgen individueller Anfragen durch mehrere Microservices – bezeichnet als Tracing. Das kann Fehler oder lange Antwortzeiten sichtbar machen und diese auf einen bestimmten Microservice zurückführen.
Tracing ist das einzige Service-Mesh-Feature, das Änderungen am Quellcode oder Konfiguration der Microservices erfordert. Der Bezug zwischen eingehenden und ausgehenden Aufrufen lässt sich nur innerhalb der Anwendungslogik herstellen.
Allerdings benötigt Tracing immer ein Backend. Mit welchen Backends das Service Mesh zusammenarbeitet, hängt von der jeweiligen Implementierung ab. AWS App Mesh beherrscht beispielsweise nur die Tracing-Lösung von AWS (X-Ray). Alle anderen Service Meshes unterstützen Jaeger, viele auch Zipkin oder Systeme, die mit dem OpenTracing- beziehungsweise dem OpenCensus-Format kompatibel sind. Die meisten Service Meshes können das vorkonfigurierte Jaeger Tracing-Backend sogar mit installieren.
Routing
In der Problemklasse des Routings fasst man Features zusammen, die sich mit der Verteilung von Serviceaufrufen an unterschiedliche Instanzen befassen. Dazu zählen einfaches Load Balancing, aber auch komplexe Szenarien wie A/B-Tests oder Canary Releases. Alle Service Meshes unterstützten die Protokolle TCP, HTTP/1.1, HTTP/2 und gRPC sowie Load Balancing.
Anders als die zugrunde liegende Infrastruktur, beispielsweise Kubernetes, erlauben die Service Meshes auch die prozentuale Verteilung von Anfragen auf verschiedene Varianten eines Service. Unterschiede gibt es bei Implementierungsdetails. Beispielsweise kann Istio anhand von Labels Untermengen von Services definieren. Für andere Service Meshes sind stattdessen zusätzliche Kubernetes-Services zu definieren. Canary Releasing oder A/B-Testing auf Basis von Headern oder URL-Pfaden sind aktuell nur mit Istio, AWS App Mesh und Consul möglich.
Resilienz
Kommunikation in verteilten Systemen muss damit umgehen können, dass bestimmte Services nicht wie erwartet antworten. Gängige Lösungsmuster hierfür sind etwa Timeouts, Retries oder Circuit Breaker.
Die meisten Service Meshes bieten die Konfiguration für Retry and Timeout auf Ebene eines Service. Linkerd 2, AWS App Mesh und Istio (im experimentellen Status) unterstützten feingranulare Konfiguration auf Ebene der URLs und HTTP-Methoden wie GET oder POST.
Istio, Traefik mesh und Consul kennen darüber hinaus das Circuit-Breaker-Pattern. Das schließt Serviceinstanzen, die wiederholt Fehler aufweisen, zeitweise vom Netzwerkverkehr aus. Während eine Circuit Breaking Library auf eine gecachte oder standardmäßige Antwort zurückgreifen kann, gibt ein Service Mesh Circuit Breaker nur einen Fehler zurück, auf den der Client dann individuell reagieren muss.
Ein weiterer Ansatz, ein System widerstandsfähiger zu machen, ist Chaos Engineering. Dabei werden Annahmen zur Stabilität eines Systems durch Experimente validiert. Methoden dafür sind etwa das Injizieren von Fehlern oder Verzögerungen. Service Meshes bieten sich an, dieses Verhalten zu implementieren, da sie den gesamten Netzwerkverkehr kontrollieren. Zumindest Istio, Linkerd 2 und Kuma können auch Fehler injizieren. Istio kann zusätzlich Verzögerungen im Netzwerk hinzufügen. Die anderen beherrschen das derzeit nicht.
Security
Schließlich gilt es, Sicherheitsaspekte zu berücksichtigen: Welcher Microservice darf mit welchem reden, die Verschlüsselung der Kommunikation untereinander, zum Beispiel via mTLS, das Managen entsprechender Zertifikate bis hin zur Identifikation der Endnutzer.
Das wahrscheinlich verlockendste Feature eines Service Mesh ist das automatische beiderseitige Authentifizieren, auch mutual TLS oder mTLS genannt. Die Service-Proxys an beiden Enden der Verbindung verschlüsseln die Datenübertragung, ohne dass der Service davon Kenntnis nehmen muss. Die Zertifikate verteilt die Control Plane automatisch an die Service-Proxys und rotiert sie regelmäßig. Bis auf Traefik mesh können alle Service Meshes automatisch mTLS-Verbindungen auf- und abbauen. In der Regel muss man diese Funktion lediglich durch eine Zeile in der Konfiguration aktivieren. Unterschiede gibt bei des Service Meshes, für welche Protokolle mTLS möglich ist und ob mTLS erzwungen werden kann. Beispielsweise kann Linkerd mTLS generell nicht erzwingen und bietet für TCP noch keinen mTLS-Support. Welche Services über welche Schnittstellen miteinander reden dürfen, lässt sich in Istio, Consul und Kuma durch Autorisierungsregeln festlegen. Istio bietet zusätzlich die Authentifizierung von Anwenderinnen und Anwendern, etwa via JWT.
Auch Service Meshes haben Soft Skills
Während die ersten Service Mesh Implementierungen den Funktionsumfang ins Zentrum gestellt haben, versuchen viele Produkte mittlerweile, durch geringe Komplexität, einfache Konfigurierbarkeit, Nicht-Invasivität oder gar „no-hype“ zu überzeugen. Die Ursache dieser Wende ist offensichtlich: Die Erwartungen an stark beworbene Produkte wie Istio waren groß und die Enttäuschung umso größer, als erste Nutzer*innen vor einer überladenen und schwer zu erlernenden API und Konfiguration standen.
Hinzu kommt, dass viele Programmierende noch dabei sind, Microservices, Container und Kubernetes kognitiv zu verdauen. Bei der Entscheidung für oder gegen eine Service Mesh Implementierung sollten nicht nur die Features, sondern auch die Benutzbarkeit eine wesentliche Rolle spielen.
Service Meshes, die in Kubernetes laufen, fügen der Kubernetes-API ihre Konfigurationsobjekte durch sogenannte Custom Resource Definitions (CRDs) hinzu. Die Anzahl der von einem Service Mesh hinzugefügten CRDs kann ein Indikator für dessen Komplexität sein. Beispielsweise spiegeln sich die vielen Features und die Flexibilität von Istio in einer komplexen API mit 23 CRDs wider. Dies kann letztendlich auch zu vielen Zeilen Konfigurationscode führen. Dabei haben die Istio-Entwickler*innen die anfänglich über 50 CRDs bereits drastisch reduziert. Das Service Mesh Kuma ergänzt hingegen nur acht und Linkerd 2 inklusive SMI sogar nur drei CRDs.
Die Usability der Konfigurations-APIs
Die Unterschiede der Feature-Implementierungen und APIs lassen sich besonders gut am Beispiel von Konfiguration in Form von CRDs verdeutlichen. Die beiden folgenden Listings stellen der Istio-Konfiguration die SMI-Spezifikation gegenüber. Sie zeigen als Beispiel eine Verteilung von Anfragen an zwei Varianten eines Service – prozentual im Verhältnis 90 : 10.
apiVersion: split.smi-spec.io/v1alpha1
kind: TrafficSplit
metadata:
name: newsservice-smi
spec:
service: newsservice
backends:
- service: newsservice-a
weight: 100m
- service: newsservice-b
weight: 900mRouting: Service Mesh Interface
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: newsservice-istio
spec:
host: newsservice
subsets:
- name: vA
labels:
version: "A"
- name: vB
labels:
version: "B"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: newsservice-istio
spec:
hosts:
- newsservice
http:
- route:
- destination:
host: newsservice
subset: vA
weight: 90
- destination:
host: newsservice
subset: vB
weight: 10Routing: Istio
Die einfache API des SMI ermöglicht es, Anfragen an einen Service (hier newsservice) intern auf andere Services anteilig umzuleiten. Im folgenden Fall werden 90Prozent der Anfragen stattdessen an newsservice-a geroutet und 10 Prozent an newsservice-b.
Die Istio-Konfiguration ist sichtlich komplexer. Allerdings benötigt Istio für die Funktion nicht mehrere Services (etwa newsservice, newsservice-a und newsservice-b), sondern kann einen Service anhand von Kubernetes-Labels in Gruppen aufteilen.
Ein weiteres Beispiel stammt aus dem Bereich der Resilienz. Die in den folgenden Listings dargestellten Konfigurationen bewirken, dass das Mesh Anfragen an den Service newsservice automatisch nach einer definierten Zeit beendet und anschließend oder im Fehlerfall wiederholt.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: newsservice-istio
spec:
hosts:
- newsservice
http:
- route:
- destination:
host: newsservice
retries:
attempts: 3
perTryTimeout: 400ms
retryOn: 5xx
timeout: 900msRetry und Timeout: Istio
apiVersion: linkerd.io/v1alpha2
kind: ServiceProfile
metadata:
name: newsservice
spec:
routes:
- name: GET /news
isRetryable: true
timeout: 200ms
condition:
method: GET
pathRegex: /news
- name: POST /news
isRetryable: false
timeout: 400ms
condition:
method: POST
pathRegex: /news
retryBudget:
ttl: 15s
retryRatio: 0.1
minRetriesPerSecond: 5Retry und Timeout: Linkerd 2
Auf den ersten Blick sieht die Istio-Konfiguration simpler aus. Allerdings ist Linkerd 2 hinsichtlich der Features weit überlegen. Die API von Istio ermöglicht die Konfiguration von Timeout- und Retry-Verhalten nur auf Ebene von Services. Anders als bei Linkerd 2 lassen sich bei Istio keine Unterschiede zwischen URL-Pfaden oder HTTP-Methoden formulieren.
Die Konfigurations-API von Linkerd 2 gestattet es, Endpunkte zu definieren und unterschiedlich zu konfigurieren. Im Beispiel werden zwei Endpunkte aufgeführt:
GET /newsund
PUT /news/*Pro Endpunkt können Entwickler*innen nun entscheiden, ob Neuversuche zulässig sind. Wie das Beispiel zeigt, erlaubt Linkerd 2 reguläre Ausdrücke. Im Beispiel soll nur eine gescheiterte Anfrage auf
GET /newswiederholt werden. Für jeden Endpunkt kann man außerdem unterschiedliche Antwortzeiten setzen. Die Konfiguration der Neuversuche erfolgt für alle Anfragen gemeinsam. Das Modell unterscheidet sich deutlich von Istio, denn es konfiguriert nicht die absolute Anzahl der Neuversuche, sondern das Verhältnis von Retry- und Erstanfragen. Mit der Linkerd-2-Beispielkonfiguration würde das System eine Anfrage gar nicht versuchen, wenn der Anteil von Retries in den letzten 15 Sekunden mehr als 10Prozent aller Anfragen betrug. Das kann diejenigen verhindern, die ohnehin wenig erfolgversprechend sind, und den aufgerufenen Service vor Überlast schützen.
Der Mensch und die Arbeit mit dem Mesh
Entwicklungsteams müssen Service Meshes installieren, konfigurieren und im Fehlerfall untersuchen können. Leider stellt sich die von dem Service Mesh mit Mühe versteckte Komplexität im Fehlerfall als Hindernis heraus. Die Suche nach der Ursache von Fehlern verlangt Entwicklerinnen und Entwicklern tiefgehende Kenntnisse der Service Mesh Komponenten, ihrer Konfiguration und Interaktion ab. Beispielsweise kann es für das Debugging hilfreich sein, die Logs oder die aktuelle Konfiguration der Proxys auszulesen und zu interpretieren. Unterstützung bieten Dashboards, die Validierung von Konfigurationen und Analysetools. Dass Istio und Linkerd 2 in diesen Kategorien weit vorn liegen, hängt sicher mit der Anzahl der produktiven Installationen zusammen, mit denen auch der Bedarf an zusätzlichen Tools steigt.
Istio bietet mit Kiali ein sehr gelungenes Dashboard. Zusammen mit den vorkonfigurierten Prometheus-, Grafana und Jaeger-Instanzen sind Observability-Features direkt sicht- und nutzbar. Das Dashboard zeigt außerdem die Konfiguration von Service Mesh Funktionen. Teilweise können Entwickler*innen diese nicht nur im YAML-Format, sondern auch im Anwendungsgraphen sehen.
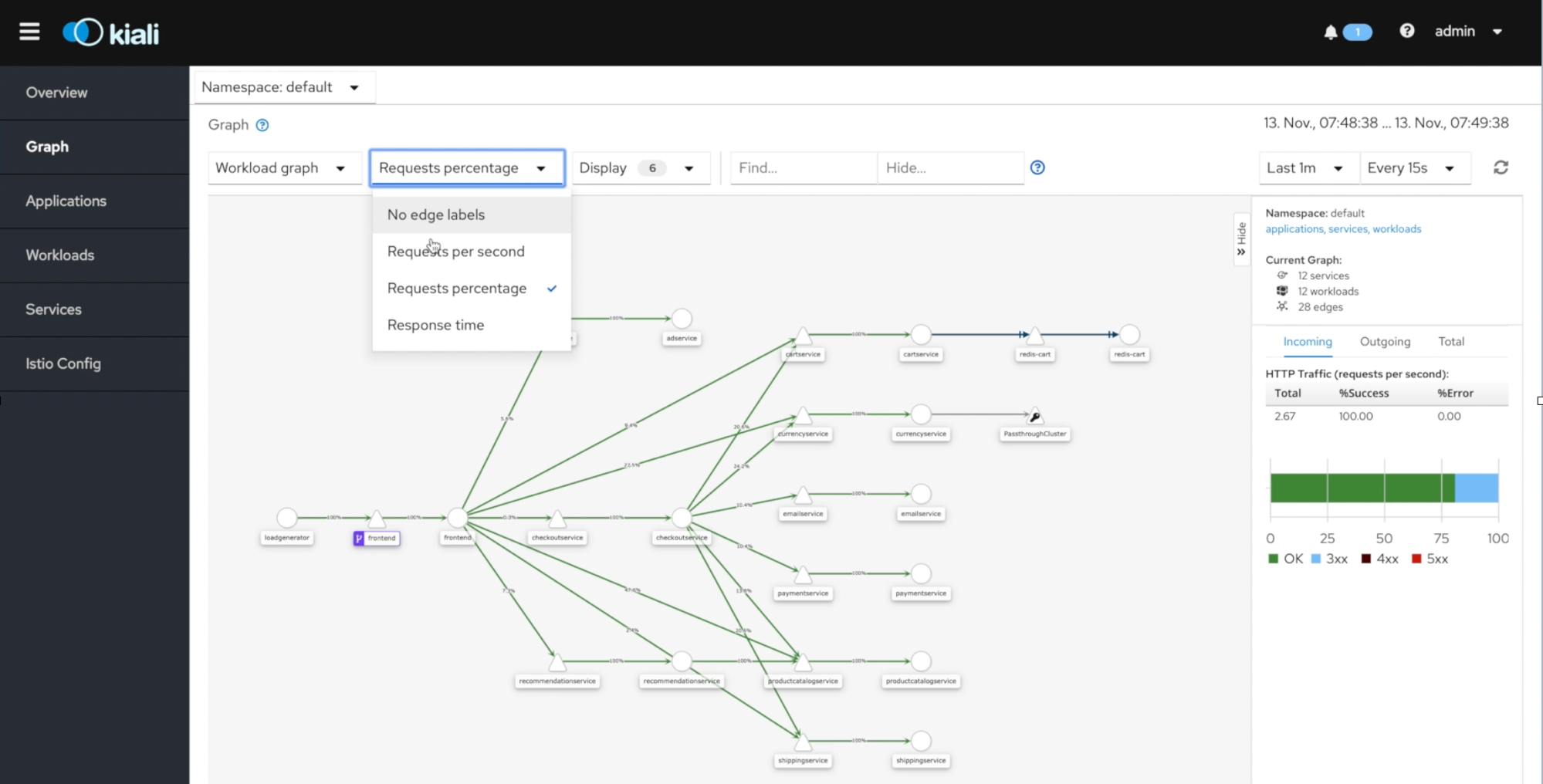
Das Dashboard von Linkerd 2 ist nicht weniger ästhetisch, aber auf eine technisch versierte Zielgruppe ausgelegt und mit zusätzlichen Analysetools ausgestattet. Beispielsweise kann es den aktuellen Netzwerkverkehr als Log anzeigen („tap“). Es stellt die zugehörigen Befehle für das Kommandozeilen-Interface von Linkerd 2 dar, sodass sich Abfragen reproduzieren lassen. Das Dashboard von Linkerd 2 bietet über Links außerdem eine gelungenere Grafana- und Jaeger-Integration als Istio.
Bis auf Traefik mesh bieten alle Service Meshes die Konfiguration und Inspektion über die Kommandozeile. Die Kommandozeilenwerkzeuge von Istio und Linkerd 2 können darüber hinaus Vorbedingungen für eine Service Mesh Installation prüfen, die Dashboards anzeigen oder die Installation durchführen.
Performance und Ressourcen
Wenn über Service Meshes geredet wird, wird schnell auch der Aspekt der Performance und des Ressourcenverbrauchs diskutiert. Service Meshes kontrollieren den gesamten Netzwerkverkehr zwischen den einzelnen Services. Das führt natürlich zu einer erhöhten Latenz. Die Messungen dazu schwanken. Beispielsweise kann man bei Istio üblicherweise weniger als 3,12 ms (90. Perzentil) erwarten. Auch der Ressourcenverbrauch steigt. Stellt man jedem Service einen Proxy zur Seite, steigt logischerweise auch der Ressourcenverbrauch mit jeder zusätzlichen Instanz des Service. Einige Service Meshes, etwa Linkerd 2, legen großen Wert auf einen effizienten Umgang mit Ressourcen und eine möglichst niedrige Latenz.
Leider lässt sich trotzdem keine einheitliche Aussage treffen, welches Mesh sparsamer ist. Entscheidend ist auch, wie lang die Aufrufketten sind. Das ist im konkreten Fall zu betrachten und zu testen. Nicht zuletzt sollte man den Einfluss auf Performance und Ressourcenverbrauch eines Service Mesh immer auch mit dem der ansonsten notwendigen Bibliotheken vergleichen.