
Im Bereich Datenanalyse und Visualisierung wird häufig mit Vektoren, Matrizen und Tensoren – also ein, zwei und mehrdimensionalen Daten –, deren Teilmengen und Kombinationen gearbeitet sowie Aggregatsfunktionen darauf ausgeführt. Da die Datenmengen oft sehr groß sind ist es zum einen wichtig Datenstrukturen zu verwenden, die hinsichtlich Performance und Speicherverbrauch optimiert sind. Zum anderen sollten sie einen einheitlichen Datentyp aller Elemente gewährleisten können, komfortable Funktionen zum Teilen und Kombinieren bereitstellen und eine Reihe von Aggregatsfunktionen wie Maximum, Minimum, Mittelwert, Standardabweichung anbieten.
Extrem werden die Anforderungen im Bereich Deep Learning. Beispielsweise beim Einsatz von Convolutional Neural Networks (CNN) im Bereich Bildverarbeitung. Dabei werden die einzelnen Pixel eines Bildes üblicherweise in Farbkanäle gesplittet und auf mehrdimensionale Arrays abgebildet. Bei einem 32x32 Pixel großen Bild im RGB-Farbraum ergibt das beispielsweise 3 32x32 große Arrays – eines für jede Farbe. Diese Arrays durchlaufen die Verarbeitungslayer der jeweiligen CNN Architektur – bei der VGG16 Architektur sind es beispielsweise 18 Convolutional und Pooling Layer – und werden dabei in jedem Layer transformiert bis sie in der letzten Stufe schließlich auf einen Ausgabevektor abgebildet werden. Beim Training eines neuronalen Netzes werden die Layer u.U. von mehreren 10.000 Bildern mehrere Dutzend Male durchlaufen. Abbildung 1 zeigt die Größe der Arrays in den einzelnen Arbeitsschritten eines VGG16 – einer CNN Standardarchitektur. Da Deep Learning Verfahren üblicherweise auf GPUs oder TPUs (Tensor Processing Units von Google) ausgeführt werden, sollten diese entsprechend unterstützt werden.

Auch für Verfahren im Bereich NLP, wie Word Embedding Verfahren werden Arrays benötigt. In diesen Verfahren werden die Wörter auf numerische Werte abgebildet und weiterverarbeitet.
Numpys ndarray
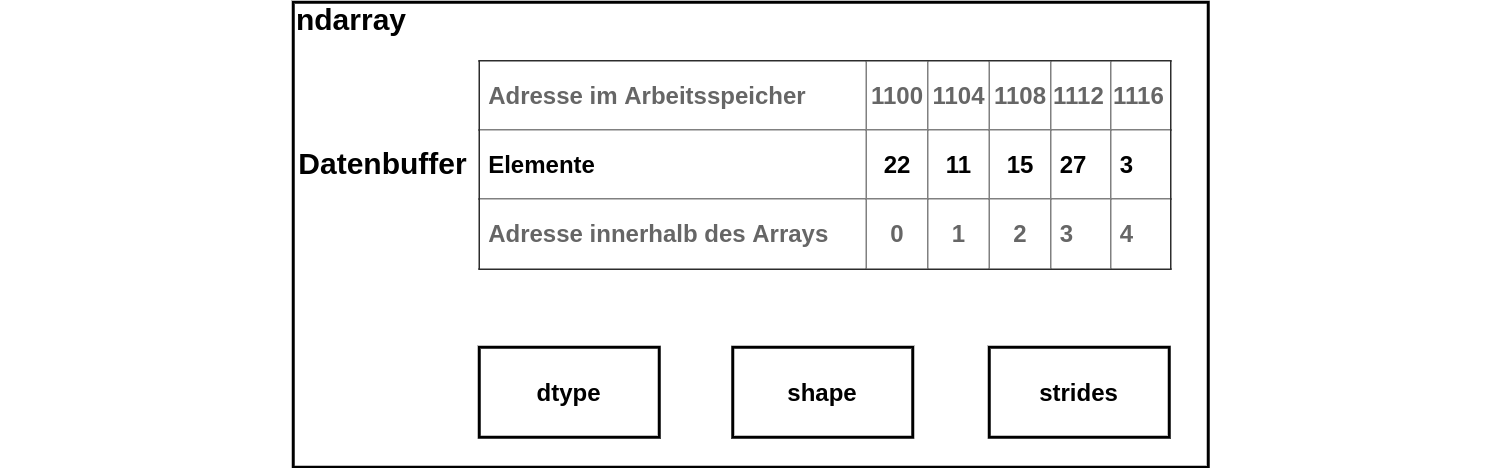
Numpy ist ein Bibliothek, die mit dem Ziel entwickelt wurde, mit großen, mehrdimensionalen Arrays einfach und performant arbeiten zu können. Verglichen mit Python Listen benötigen sie außerdem weniger Arbeitsspeicher. Die zentrale Klasse numpy.ndarray – für n-dimensional array – repräsentiert ein mehrdimensionales Array fester Größe. Beim Anlegen wird dem Array ein zusammenhängender Speicherbereich fest zugeordnet. Wie ein Array auf diesen eindimensionalen Speicherbereich abgebildet wird, wird durch drei zusätzliche Metadaten festgelegt. Das Objekt dtype beschreibt die Struktur und die Datentypen des Arrays. Numpy unterstüzt dabei eine größere Anzahl an Datentypen als Python, beispielsweise unsigned Integer oder komplexe Zahlen. Das dtype Objekt kann bei der Initialisierung eines Arrays entweder explizit angegeben werden, oder es wird von numpy automatisch erstellt. Ob es sich um ein ein- oder mehrdimensionales Array handelt, wird durch das Tuple shape festgelegt, welches die Dimensionen des Arrays angibt. Das strides Tuple definiert die Byte-Länge der Arrayelemente in jeder Dimension.
Ndarray beinhaltet außerdem Methoden zur Ermittlung statistischer Kennzahlen, sowie Funktionen für Operationen aus dem Bereich lineare Algebra und arithmetische Berechnungen, beispielsweise die Berechnung des Skalarprodukts. Häufig wird zum Erstellen eines ndarrays die Funktion numpy.array verwendet, die eine Vielzahl komfortabler Optionen bietet.
Beispiel:
>>> import numpy as np
>>> # ndarray aus Python Liste erstellen
>>> first_array = np.array([[1,2,3],[4,5,6]])
>>> first_array
array([[1, 2, 3],
[4, 5, 6]])
>>>first_array.dtype
dtype('int64')
>>> # ndarray vom Typ unsigned int erstellen
>>> second_array = np.arange(3, dtype=np.uint8)
>>> second_array
array([0, 1, 2], dtype=uint8)
>>> # Zugriff auf das erste Element der ersten Zeile
>>> first_array[0,0]
1
>>> # Zugriff auf die erste Spalte
>>> first_array[:,0]
array([1, 4])
>>> # Skalarprodukt zweier Arrays berechnen
>>> first_array.dot(second_array)
array([ 8, 17])Bisher können ndarrays nur im Arbeitsspeicher abgelegt werden, nicht jedoch im GPU oder TPU Speicher. Damit sind die Einsatzmöglichkeiten von ndarray für das rechenintensive Training der meisten neuronalen Netze limitiert. Bibliotheken wie TensorFlow oder PyTorch, die schwerpunktmässig mit neuronalen Netzen arbeiten, setzen deshalb auf eigene Array-Implementierungen. Die Klasse Tensor von Tensorflow wird weiter unten noch vorgestellt. Daneben gibt es noch eine handvoll Standalone-Bibliotheken welche in einigen Fällen beim Einsatz von GPUs anstelle von ndarray verwendet werden können. Ein Beispiel dafür ist gnumpy, dessen garray Klasse Teilfunktionen von ndarray implementiert, allerdings nur den Datentyp float32 unterstützt.
Pandas
Pandas ist eine der populärsten Datenanalysebibliotheken. Sie bietet eine Vielzahl von Funktionen für deskriptive Statistik, Zeitreihen, Visualisierungen und das Aufbereiten von Daten. Ihre Kernkomponenten, die Klassen DataFrame (zweidimensionales Array), Series(eindimensionales Array) und Index(ordered Set), bauen auf ndarray auf und ergänzen zahlreichen Funktionen. Darunter sind beispielsweise Funktionen für merge und joins zweier Dataframes, das Setzen von Defaultwerten bei fehlenden Daten oder lesen und schreiben der Daten von und in JSON, CSV und weitere Formate. Für Dataframes und Series können Zeilen- und Spaltenbeschriftungen gesetzt werden, was den Zugriff vereinfacht.
pandas unterstützt die numpy Datentypen und erweitert sie um weitere Typen unter anderem für kategorische Daten und Nullwerte.
Beispiel:
>>> import pandas as pd
>>> # Dictionary anlegen
>>> data = {'Bundesland': ['Bayern', "Nordrhein-Westfalen"],
... 'Einwohnerzahl': [13076721,17932651], 'Fläche': [70550.19,34110.26]}
>>> # Dataframe mit Spaltennamen aus Dictionary erstellen
>>> df1 = pd.DataFrame.from_dict(data)
>>> # Automatisch ermittelte Spaltentypen anzeigen
>>> df1.dtypes
Bundesland object
Einwohnerzahl int64
Fläche float64
dtype: object
>>> # Dataframe ausgeben, Zeilen werden automatisch nummeriert
>>> df1
Bundesland Einwohnerzahl Fläche
0 Bayern 13076721 70550.19
1 Nordrhein-Westfalen 17932651 34110.26
>>> # Bundesland als Zeilenbezeichnung festlegen
>>> df1.set_index('Bundesland', inplace=True)
Einwohnerzahl Fläche
Bundesland
Bayern 13076721 70550.19
Nordrhein-Westfalen 17932651 34110.26
>>> # Zeile mit Zeilenname abfragen,
>>> # Das Ergebnis wird in eine Series mit einheitlichem Datentyp konvertiert
>>> df1.loc['Bayern']
Einwohnerzahl 13076721.00
Fläche 70550.19
Name: Bayern, dtype: float64
>>> df1.loc['Bayern', 'Einwohnerzahl'] # Zelle mit Zeilen- und Spaltenname abfragen
13076721
>>> # Auf Zeilen- und Spalten kann auch über ihre Indexnummer zugegriffen werden
>>> df.iloc[:,0]
Bundesland
Bayern 13076721
Nordrhein-Westfalen 17932651
Name: Einwohnerzahl, dtype: int64scikit-learn
scikit-learn ist eine der populärsten Bibliotheken für klassisches bzw. statistisches Machine Learning und implementiert zahlreiche Verfahren aus den Bereichen Classification, Regression, Clustering. Sie arbeitet direkt mit der ndarray Klasse von numpy. Es ergänzt eine Reihe von Funktionen an um ndarrays in Test- und Trainingsdaten zu splitten, darunter sind auch Funktionen die eine mehrfache Aufteilung in unterschiedliche Teilmengen zu ermöglichen, was für Algorithem benötigt wird die mit Kreuzvalidierung arbeiten.
Beispiel für ein einfaches Splitten in Trainings- und Testdaten im Verhältnis 2/3 zu 1/3:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33)Jedes von scikit-learn unterstützte Verfahren verwendet dann den folgenden schematisierten Ablauf um Modelle mit den Trainingdaten-Arrays zu trainieren, mit den Tesdaten-Arrays zu überprüfen und Vorhersagen zu treffen:
model = ... # Angabe des zu verwendenden Verfahren
model.fit(x_train, y_train) # Trainieren des Modells
model.predict(x_test) # Das trainierte Modell nutzen um Vorhersagen zu treffen
model.predict_proba(x_test) # Zeige die Wahrscheinlichkeit des vorhergesagten Wertes an
model.score(x_test, y_test) # Metrikangabe zur Güte des ModellsKeras API
Keras ist sowohl eine Bibliothek, wie auch eine allgemeine API-Spezifikation für neuronale Netze und Deep Learning. Diese API wird unter anderem auch von TensorFlow 2.0. unterstützt, da sie eine leicht verständliche Möglichkeit zum Konstruieren, Trainieren, Beurteilen und Abfragen von neuronalen Netzen bietet. Dabei unterstützt die Keras API verschiedene Möglichkeiten der Datenhaltung je nachdem in welchem Framework sie implementiert ist: Numpys ndarrays, Python dicts, sowie – wenn vorhanden – frameworkspezifische Implementierungen wie Tensor von TensorFlow.
Das Schema zum Trainieren, Evaluieren und Verwenden eines neuronalen Netzes ähnelt dabei dem der von scikit-learn implementierten Verfahren. Anders als scikit-learn verfügt die Keras API aber nicht über explizite Funktionen um einen Datensatz in Trainings- und Testdaten zu splitten. Hier kann man entweder die Methoden der verwendeten Datenstruktur nutzen oder die Aufteilung implizit innerhalb der Methode fit erledigen lassen, in welcher das Modell trainiert wird. Bei letzterer Option mittels des optionalen Parameters validation_split festgelegt werden, welcher Prozentsatz der Daten nicht zum Trainieren, sondern nur zum evaluieren des trainierten Modells herangezogen werden soll, weitergehende Konfigurationsmöglichkeiten des Aufteilungsverfahrens bietet die Methode allerdings nicht.
>>> from keras.models import Sequential
>>> model = Sequential()
>>> # ersten Layer des neuronalen Netzes hinzufügen
>>> model.add(...)
>>> ... # weitere Layer hinzufügen
>>> # Modell konfigurieren (Art der Loss Funktion, Qualitätsmetriken etc.)
>>> model.compile (...)
>>> # Modell trainieren
>>> metrics = model.fit (x, y, validation_split =..., ...)
>>> # Das trainierte Modell nutzen um Vorhersagen zu treffen
>>> model.predict (x_test)
>>> # Qualitätsmetriken für einen Testdatensatz ermitteln
>>> model.evaluate (x_test, y_test)Tensor von TensorFlow
Tensorflow ist eine Bibliothek für neuronale Netze und Deep Learning. Es bringt eine eigene Implementierung eines mehrdimensionalen Arrays mit: Tensor. Tensor Objekte haben einen Datentyp und eine Dimension. An Datentypen werden bool, float32, int32, complex64 und String unterstützt. Tensoren können anders als ndarrays nicht nur im Arbeitsspeicher, sondern auch in den Speicherbereichen von GPUs und TPUs abgelegt werden auf die schneller und mit einer höheren Bandbreite zugegriffen werden kann. GPUs und TPUs werden benötigt um die große Menge von Matrixoperationen, die beispielsweise beim Einsatz von CNNs anfallen, parallel und damit schneller ausführen zu können. Die meisten TensorFlow Operationen akzeptieren an Stelle von Tensoren auch numpy ndarrays und konvertieren diese automatisch.
Beispiel:
>>> import tensorflow as tf
>>> import numpy as np
>>> tensor1 = tf.constant([[1.0, 2.0], [3.0, 4.0]])
>>> ndarray = np.ones([3, 3])
>>> # Funktion akzeptiert ndarray als Parameter und liefert Tensor zurück
>>> tensor2 = tf.multiply(ndarray, 10)
>>> # Tensor in ndarray konvertieren
>>> tensor.numpy()
array([[1., 2.],
[3., 4.]], dtype=float32)
>>> # Zugriff auf Elemente eines Tensors erfolgt analog zu ndarray
>>> tensor1[0,0].numpy(), tensor1[:,0].numpy(), tensor1[0,:].numpy()
(1.0, array([1., 3.], dtype=float32), array([1., 2.], dtype=float32))