
Some time ago, I joined a new team of developers where part of my responsibility was going to be developing a quite large[1] React application serving users in multiple countries. Having always considered myself a backend developer, I was unsure if I’d even manage such a Javascript “gig”, but I accepted the challenge and I prepared to do a lot of reading and investigating.
As I first discussed the project with the other team members, they hinted at some some potential issues in the frontend code base. Having a closer look at the application itself, I quickly found many cases of accidental complexity: difficult to understand data structures, over-engineered solutions and redundant abstractions. Usually, this kind of complexity emerges as the result of developing an application too fast, without sufficient understanding of problem domain and technology.
Discussing some of these problems and misunderstandings, we concluded that many could have been avoided only through proper, idiomatic use of Javascript. As a result, the team made an effort to start learning more about Javascript and the React ecosystem and over a few months we developed a much better intuition on writing clear and robust code.
On the one hand, React is quite easy to get started with and there are not that many rules a programmer has to follow in order to write a working React application. On the other hand, in order to write an application the “React way”, there are a number of conceptual guidelines to follow. The exact interpretation of these guidelines may vary, and the claims and suggestions of this article are thus based on our interpretation of the React way, with examples based on improvements done for our particular project.
The first two parts of this article presents practical and theoretical knowledge that we’ve collected after analyzing and refactoring our code base. The last part of the article contains a set of “best practices” that we used to identify and get rid of accidental complexity. We found that continuously applying these practices together with a bottom-up approach was a clear and straightforward way to make our application more robust and understandable for everyone.
Immutable Data and Abstract Trees
When the React team open sourced their project in 2013, there were already a large number of Javascript frameworks available, all promoting their own views on how to best structure web application. As with every new piece of technology, the React team had to answer the question: Why another framework[2]? What makes React different from what is already out there?
The most distinguishing feature of React is the focus on minimizing mutation. This is achieved by building on top of established REST principles such as separation of client-server concerns, stateless rendering, cacheable views and promoting a uniform client interface for reading and writing data.
It all boils down to a different approach for thinking about browser views: Instead of directly manipulating the DOM, React lets the programmer define an abstract representation of the view to be rendered. This abstraction is realized through a hierarchy of components, each responsible for their own rendering. Thus, the programmer only has to think about view updates limited to the context of an abstract component, not the entire DOM tree. Instead of doing stateful, in-place manipulation, we simply give React a description of how a component should look like, and how it should respond to events. The main purpose of React is to interpret these descriptions and generate actual DOM trees for the browser to render.
This new way of defining views means that the views and their implementation are decoupled, making it possible to plug-in the “React abstraction”[3] a frontend to any environment and not just the browser and the DOM. A less technical but nonetheless important advantage lies in the abstraction itself: decoupled from the DOM, we can see views as immutable data which can be passed around as value and operated on by standard functions.
The data, or the abstract component hierarchy, is internally represented as a tree data structure where each node corresponds to a component in the hierarchy. To render the root of the tree, you first have to recursively render all its children. When a node has to change, React makes changes in a persistent [4] way, meaning that it generates two references to two independent, cheap copies of the tree: one referencing the old, unchanged tree, and one referenced a new tree with that node changed. Both references are to immutable data, which means that they are completely disjoint and changes made to one tree cannot cause unforeseen changes in the other tree. By comparing the old with the new tree, React can quickly and deterministically find the minimal difference between those and use that to update the DOM with relatively little work needed.
When I started learning React, I knew very little about the DOM and which problems programmers usually faced dealing with it. I still know very little about the inner workings of the DOM, which is completely fine as long as React takes care of the dirty work. React solves the essential problem of “what” a view is rather than “how” to render it, that is, it solves the more important problem for most users. The fact that React lets the user describe views in a declarative, deterministic way is a huge plus as we will see in later sections of this article.
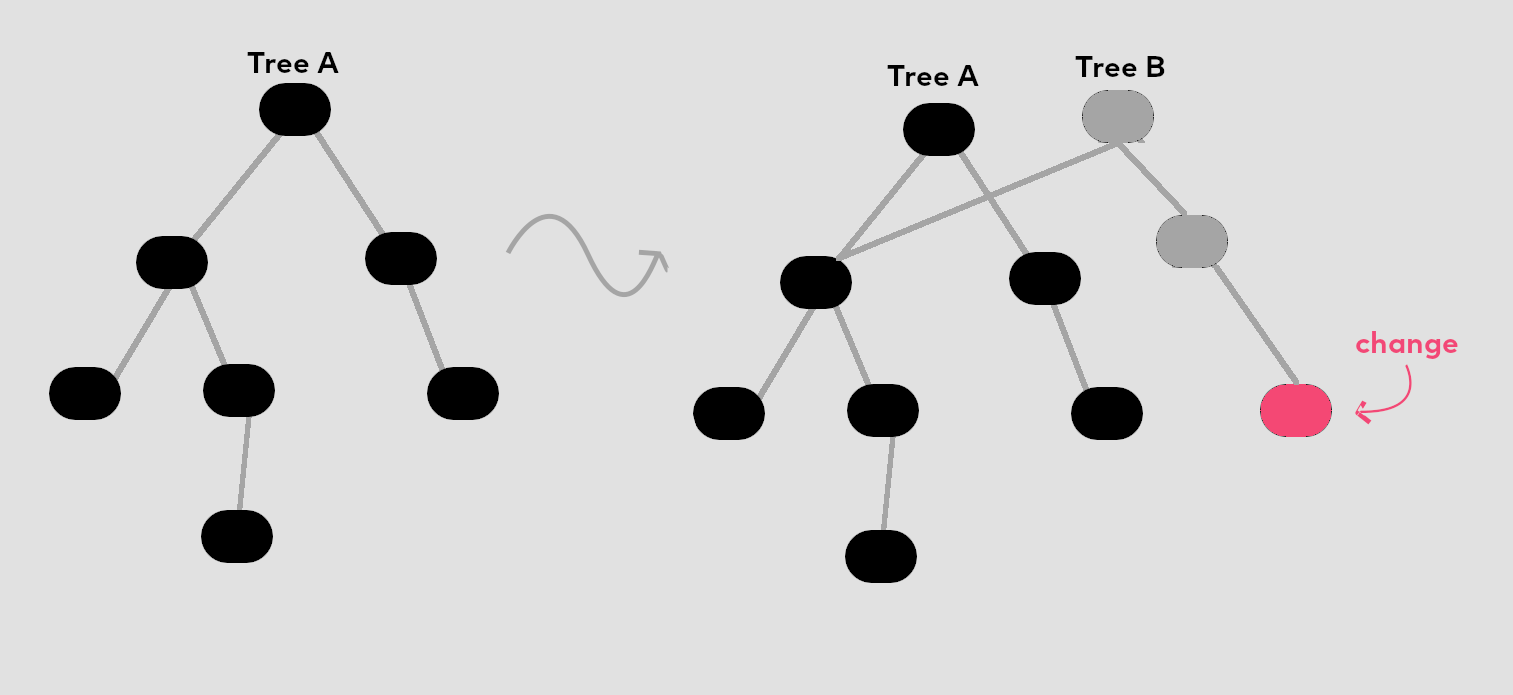
The image shows a change made to the persistent, immutable Tree A.
Notice that after changing one node, the newly created Tree B references a
new tree, even though it still shares a large part of Tree A’s
structure. This example shows how changing immutable data structures mostly
almost never requires fully copying the original data.
Programming Structure and Data
Structure
Each node in the React component tree is defined by a React Component.
Programmatically, it can be described using a class[5]
as in the example below.
import React, { Component } from 'react';
class Dialog extends Component {
const config = { color: 'red' };
render() {
return (
<div>
<p>Click the button, if you dare</p>
<Button text={'do it'} color={config.color}/>
</div>
);
}
}To define a component, we have to say how to render it. To do this, we use the
special render function, whose return type is JSX, described by a HTML-like
syntax. From a syntactic view, JSX and HTML are almost interchangeable, making
it easy to pick up for anyone familiar with HTML. The main difference is the
context in which it is used: JSX is declared as a part of a React component
while HTML exists on its own. As a result, we can define rendering logic
side-by-side with other UI logic like user events and state changes[6].
In Example 1, we use JSX to declare the structure of Dialog by composing a
div, a p and a Button - another React Component. Button, and any
other subcomponents might have their own subcomponents and so on, and in this
way React users describe application structure by defining a tree like the one
from the previous section.
Data
In this section, we discuss two ways to look at data in react: state and properties (props)[7]. Both state and props are ordinary Javascript objects and are not special in any technical sense. On the other hand, state and props are special in how they should be treated by the user - more on that in the two following subsections.
Given a particular state and properties object, React always[8] renders the same view. In other words, the rendering process can be seen as a pure function with the signature:
(state, props) : Model -> jsx : ViewProperties
Properties are an immutable, unchangeable set of values, passed down to a
component from its parent upon declaration. In the first example, the Dialog
component passes the props text and config.color to the Button component.
This turns into the concrete object { text: 'do it', color: 'red' }, which
Button is able to access via the special reference this.props.
Note that while the React convention declares these properties to be immutable, they are still plain old Javascript objects, and very mutable indeed.
State
State is, in contrast to props, intended to represent data that can change over time, for example as a response to to user input. Even though React provides the user with tools for changing state in an efficient and dynamic way, these tools do not allow mutation. Mutating state can be powerful, but with great power comes great responsibility! Mutation is complicated for many reasons and React avoids it at all costs.
State in React is seen as a flow of immutable data: when rendering a component,
we simply take the latest snapshot of this flow and pass it to the render
function together with the props. Programmatically, changing state is done by
calling the setState function, a pure function from the previous state to new
state.
Having only one way to change state is important, because it allows us to
search a file for setState and quickly determine all[9] places in a component
state can change. Similarly, we only read state from the single reference
this.state, and thus do not have to manage state that is scattered around all
over the place[10].
The restrictions React enforces on its state model allows the users to focus their attention to the actual component currently being worked on, making it much more comfortable to work with compared to more conventional state models.
Passing state across components
In some cases, it is necessary to share state between components. In the case of sharing a parent’s state to a child, we simply pass the state of the parent as props to the child.
class Dialog extends Component {
render() {
return (
<div>
<Button text={this.state.buttonContent}
color={this.state.buttonColor}/>
</div>
);
}
}In the case of sharing a child’s state with its parent, we can pass a callback function as props to the child, triggered on inner state update.
// Child
class Button extends Component {
constructor(props) {
super(props);
this.state = { counter: 0 };
}
return <button onClick={() => {
this.setState({ counter: this.state.counter + 1 });
this.props.callback(this.state.counter}
}} />
}
// Parent
class Dialog extends Component {
handleButtonStateChange(count) {
console.log('button clicked: ' + count + ' times');
}
render() {
return (
<div>
<Button text={this.state.employees[0].name}
age={this.state.employees[0].age}
callback={(count) => this.handleButtonStateChange(count)}/>
</div>
);
}
}Note that this approach encourages us to share the minimal amount of state
needed. In the third example, we are only sharing the value we are interested in - the
count - and this is passed as value to our callback function.
Be careful reading and writing state
As mentioned, all state writes should be handled by the same special function
setState, and all state reads should be through the special reference
this.state. Trying to write values directly to this.state is object is
undefined behaviour.
We should also never try to set state as a part of the rendering logic in the
render function. Doing so anyways will result in our browser crashing, as we
just defined a state-update triggered by a re-rendering and re-rendering
triggered by a state-update. setState is correctly used as a part of event
handlers, which are triggered on e.g. user events, not re-renderings.
In some cases, we might want to update state automatically and
dynamically after some condition is met. Example 4 shows how to trigger one
single HTTP call per rendering, and only when the data is available. Such
operations are not logically coupled to the rendering of a component, so we
define this separately in the built-in, special component* functions that lets us
define side-effectful build-up and tear-down of components. In this particular
case, we’ll use the componentDidUpdate function.
componentDidUpdate is triggered every time the component is updated through
state changes and similar events. By properly checking on each component
update if (1) the data is available for load and (2) the data has not already
been loaded, we can ensure that the HTTP in this example call happens once per component
rendering and our state is loaded exactly once.
constructor(props) {
super(props);
this.state = { foo: null, fooLoaded: false };
}
componentDidUpdate(prevProps, prevState) {
if (this.props.fooAvailable && !prevState.fooLoaded) {
this.setState({ foo: this.fetchScoresHTTP(), fooLoaded: true });
}
}As seen in Example 4, componentDidUpdate gives us access to both
previous props and state and we can use it to detect changes in state.
Understandability: Ten Commandments
So far we have seen an introduction to the React way of defining structure, handling data and managing component lifecycles. The rest of this article discusses things that React does not directly influence or enforce. The list of ideas presented here are meant to help write applications that are more consistent with the general React “philosophy”, based on our interpretation of this philosophy. The motivation is as follows: If we keep component and framework logic consistent, we encourage different developers to think about solving problems in a similar way, which leads to an increased understanding of the entire system.
1. Write dumb components
If we ever ask ourselves if we should break up a component in two, the answer is almost always yes. Focus on writing “dumb” components with as minimal logic, state and props as possible. The hierarchical nature of React makes it natural to compose these into a larger structure.
2. Pass explicit arguments to helper functions
By passing explicit arguments to helper functions instead of accessing global
variables such as this.state or this.props, it becomes clearer when to
split logic in two separate functions, and when to compose them. For example,
a function that depends on more than a handful parameters can not as easily be
understood on its own and might need to be split up. Passing explicit
arguments rather than using global variables make this more obvious.
I found it helpful to think of helper functions as pseudo-components which have not yet gotten their own component definition. Passing each function its explicit set of data will make the transition easier once we decide to actually refactor the logic into its own component.
To summarize, using the global this object all over the component is confusing,
so I’d suggest doing all reading of this.state and this.props in the render
function.
// Good
helper(label, count) {
return (
<label>{label}</label>
<p>{count}</p>
);
}
render() {
return <div>{this.helper(this.props.label, this.state.count)}</div>;
}
// Not so good
helper() {
return (
<label>{this.props.label}</label>
<p>{this.state.counter}</p>
);
}
render() {
return <div>{this.helper()}</div>;
}3. Treat collections as immutable
Regardless of how the data handling is split between backend and frontend, there will be collections on the frontend to be dealt with.
To avoid the temptation of using mutation, Immutable.js is a library that allows us to efficiently create immutable collections with a uniform interface from standard Javascript collections. The advantage of these immutable collections is that each operation returns a modified copy of the original instead of mutating the collection in place, so modifying one collection can not lead to breaking other collections. Implementation-wise, Immutable.js takes the same approach as React, representing maps, sets and lists as persistent, immutable data structures.
import { List } from immutable;
const array = [1,2,3,4,5];
// `array` is still accessable as it was originally defined
const reverse = List(array).reverse()Of course, when adding additional dependencies to our project we have to
consider the tradeoffs. In the case of Immutable.js, the most evident
tradeoff[11] is the need for converting each native object to an
immutable object (for example by using List as in the example above) and then
back to another native object. Thus, we should primarily consider using
Immutable.js in the case we have long and frequent data transformation chains
in our component logic. If not, we should stick to standard javascript but
still treat collections as immutable.
4. Read values in a standardized way
To avoid the Javascript error undefined is not a function it is common to see these kind of
sequences in Javascript code.
const nestedVal = foo && foo.bar && foo.bar.baz && foo.bar.baz.buzz && foo.bar.baz.buzz.length > 0 &&
foo.bar.baz.buzz[0]Lodash is a widely used utility library that standardizes many common
operations. We usually import import it as _.
import * as _ from 'lodash';With lodash, we standardize the way we read nested values.
const nestedVal = _.get(foo, 'bar.baz.buzz[0]')This has the same effect as the long chain of checks above: if any field on the path is null or
undefined, _.get will return undefined. Note that this effect can also be
achieved by optional chaining, but using _.get is
arguably more clear, succinct, and more consistent with a functional[12] style.
Being a dynamic language with dynamic type conversion, we never really
know what to expect from Javascript - even less so from the Javascript
written by our co-worker. In my case, a lot of refactoring work was
identifying and removing repetitive, often redundant pre- and post-condition
checks. By using _.get, we immediately remove the need for a large amount of
checks and using it also makes clear that the read variable is allowed to be
null or undefined.
Checking values in Javascript can be done in many different ways, but using
Lodash we can replace most checks by _.isNil and _.isEmpty.
_.isNil(data) is true if data is null or undefined. _.isEmpty(data)
is true for all values of data except a non-empty object, string, array, map,
set, and so on.
5. Destruct composite values and make them immutable by default
There is a reason why most modern languages[13] make all
variables immutable by default. Adopting the same approach in Javascript,
const is to be preferred over let and var when declaring references to
data. In the rare case where we need to use a mutable variable, we should use
let. let was introduced to Javascript in order to mitigate some of the
confusion arising from the usage of vars: allowing multiple declarations of
the same variable name, variable hosting and other odd scoping rules and
properties[14].
To retrieve multiple fields from a variable in the same scope, we should use destructuring. Descructuring makes the structure of a variable clear and succinct and pulls the desired values into the current scope at the same time, as seen in the example below.
// Good
const {foo, bar, baz} = this.state;
// Not so good
const foo = this.state.foo;
const bar = this.state.bar;
const baz = this.state.baz;6. Prefer the conditional operator over if/else and switch
For branching, we should prefer the conditional operator over if/else. There are two main problems with if/else in Javascript. First, the else branch is optional, making it implicit and thus confusing. Secondly, if/else is a statement rather than expression, encouraging mutation.
let phrase = 'hello'
// many unrelated lines of code
if (number == 42) {
phrase = 'goodbye';
}
console.log(phrase + ' world');A branching structure is in general much easier to understand if both branches is coupled to the same expression, and the expression returns two immutable values.
const phrase = number == 42 ? 'goodbye' : 'hello';7. Avoid indexing in general
We should never ever, ever need to write an indexing for loop in Javascript.
Standard Javascript has more than enough support for robust iteration
through map, filter and reduce.
- To update each element in a collection, use
map - To select a subset of a collection, use
filter - For reducing (and its dual expanding) values , use
reduce - If we really need an index, these functions take an additional argument for the index
items.map((item, i) => ...)Indexing is error prone and almost always unnecessary. Avoid “Java-style” constructing in Javascript and instead use direct constructing and avoid mutation and unnecessary naming problems.
// Not so good
let arr = []
arr[0] = 'foo'
arr[1] = 'bar'
return arr;
// Good
return ['foo', 'bar'];8. Use implicit returns
Use implicit returns whenever possible. This emphasizes the value being returned, rather than the how it is done (by returning something), which is less important. Implicit returns also encourages smaller, more manageable functions and reduces syntax.
// Good
onchange={() => makeTitle(this.state.title)}
// Not so Good
onchange={() => ({
return makeTitle(this.state.title);
})}9. Use declarative naming
In the same spirit, we should use declarative names for our functions and
components, and we should keep the context in mind. A function responsible for returning
the view of a HTML-select element inside a Dialog component, doesn’t need to
be called renderDialogSelectElement. We simply call it select.
We should only prepend a function name with a verb like render or get when
the function is side-effectful, because it allows for encoding more information
into narrow names. If a function is called getModel, we can encode (1) that
it returns a model and (2) that it does something effectful like a GET HTTP
request in order to retrieve the data. Again, if the function is “just”
returning an immutable data structure on the language level, and the function
is placed in a sensical namespace, simply call the function after the noun, in
this case: model [15].
10. Standardize code formatting and linting
Having standardized the model, view and application logic, we should also standardize how to format code. For a team of developers, formatting code is important for the practical reason of having clean diffs to compare. For a single developer, having automated, standardized formatting is arguably even more important, because it lets the developer care less about syntax and more about the semantic meaning of the code. In short: always use a standardized formatter and linter across the team, and make sure these tools fires automatically on each save for every developer. Prettier is a good code formatter and EsLint is a good linter for Javascript. Both require minimal configuration and are easy to use and plug in to standard text editors.
Conclusion
Before using a new technology, we must make an effort understanding the underlying principles and guidelines the authors of that technology provide. In the case of React, the main idea is minimizing mutation and thereby encouraging the user to think about views, state and events in a declarative, rather than imperative way. Keeping only this key idea in mind helps us write more idiomatic React code.
Writing idiomatic React code improves the arguably most important quality criterion of modern software systems: understandability. Removing mutation from our application means that we only have to think about data structures as they were originally defined and not about all their mutations that can occur during runtime. Our method for removing mutation includes well known concepts from functional programming such as decoupling data and functionality, first class functions and pure transformations.
The benefits of these functional programming concepts have long been known, and has been often rediscovered and emphasized. Unfortunately, the term “functional programming” often seem to drop adoption rate of new technologies when linked with the term. React takes the perfect approach delivering ideas from the functional programming world into a more mainstream audience, barely mentioning word “functional” at all.
If you find yourself working on a React application where the React philosophy has not been implemented yet, start with a bottom-up approach with the practices from this article. Standardize common operations, compose and decompose often and treat collections as immutable. The rest will follow.
-
The code base included ~ 40.000 LOC, including tests. ↩
-
Wether React is a “framework” or “library” is a debated topic. Even though React is a relatively small set of functionalities, it largely influences how we write our application. Therefore, I refer to React as a “framework” in this post. ↩
-
In this paragraph, I refer to React as the “React abstraction” rather than the web–framework React. For example, [React Native] uses the idea of the React abstraction on a different backend – namely mobile. ↩
-
With persistent data structures, we mean persistent in the sense of immutable, not persisted to disk. For more information on persistent data structures and structural sharing, refer to Purely Functional Data Structures by Chris Okasaki. ↩
-
A React component does not need to be defined in a class. A class in React is just a special function that (1) accepts one argument
propsas input, (2) has implicit state and (3) returns the JSX data which describes rendering the component the function represents. ↩ -
Although considered standard in modern React applications, JSX was not always a part of React. Early versions of react only provided a less visually pleasing syntax for declaring React elements with the
React.createElement()call. Babel compiles JSX down tocreateElementcalls. ↩ -
In addition to state and props, React also provides Context. This allows for sharing data between components without explicitly passing it as a prop through every level of the tree. ↩
-
By “always”, we do not take into consideration any non–deterministic logic users write on the component level, as well as any React–Context. ↩
-
There are other ways of using state in react, for example
useStatewith React Hooks, but for our intents and purposes,setStateis enough. ↩ -
In classical object–oriented programming languages, state is, by the definition of object, scattered all over the place. ↩
-
Another tradeoff is size. Immutable.js compile down to around 40Kb (the same case with Lodash). In our case, the combined size of these two libraries corresponds to less than ~ 0.5% of the total bundled frontend application. ↩
-
In terms of “functional programming”, not “it is working” ↩
-
Clojure, Rust, Swift, Kotlin, ReasonML, Elm, ReasonML ↩
-
For a detailed differentiation between
varandlet, I'd refer to this discussion: https://stackoverflow.com/questions/762011/whats–the–difference–between–using–let–and–var ↩ -
For a great chapter on naming, see the first chapter of Elements of Clojure by Zach Tellman. ↩