

Nobody had slandered Josef K., but this week he was on call, again. And that mostly meant much trouble. He was a software developer with the travel service provider “30 Days of Happiness” and part of the team that had developed the flight booking system “Always Available”. This system enabled the company owned travel agencies to process flight bookings with all domestic air carriers using an integrated user interface. The systems of individual airlines were connected to “Always Available” with a variety of quite different technologies, and regrettably they were not always reliable.
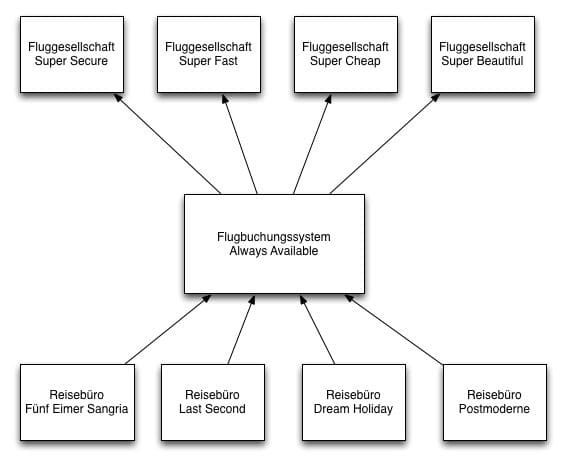
To work with the latest information, communications with airline systems always took place in real time. If, for instance, a customer of the agency “Dream Holiday” was looking for a flight from Cologne to Barcelona, a request was sent by the agency’s system to “Always Available”. This software then sent out requests to the individual airline systems to find a suitable flight within the desired time frame. It happened frequently that individual airline systems crashed the whole flight booking system because of threads being stuck while waiting for a non-responsive airline system.
And that’s the way how it was now. Everything was frozen, and the phone rang continuously. Although it was possible to disconnect the flight booking system from individual airline systems using configuration files, that required a restart of the whole application. And as always he did not know which of the airline systems was causing the problems this time.
Stability patterns to the rescue
Obviously some fundamental stability patterns for distributed applications had been disregarded during the development of “Always Available”. These are described in detail by Michael Nygard in his still highly recommendable book [1] and shall be briefly summarized here.
Timeout
Networks are never 100% reliable, therefore all external communication that can block threads should be subject to timeouts. If the client application does not receive a response from the external resource within a defined time period, the request will be cancelled to avoid destabilizing the client application.
Circuit breaker
Circuit breakers function like fuses in household devices, which protect electrical networks against overload. Applied to software development this means that for a certain time period all further requests to an external system will be suspended if it is found to be overloaded or to be temporarily unavailable. This avoids unnecessary waiting periods and the blockage of thread pools.
Bulkheads
Bulkheads are originally partitions that separate the hull of a ship into several areas. In case of a hull break the affected area can be isolated through a bulkhead to keep the water from spreading freely throughout the hull. Similar conditions prevail in the development of distributed applications. The resources needed by a system for its functioning are divided into separate groups which remain completely independent from each other. The resources could for example be thread pools or application instances. Bulkheads prevent problems from cascading by locally limiting their effects.
Steady state
Every application should treat its needed resources sustainably by releasing just as many resources over time as it uses. The objective must be to keep the system, once deployed, in a stable condition (“steady state”) throughout its run time.
Fail fast
Requests that cannot be successfully processed should be interrupted by the server as quickly as possible and answered with an informative error description. This procedure will protect the resources of the system itself as well as all dependent systems.
Handshaking
Before flooding a server with requests, the client should get confirmation from the server that it is actually ready to process these requests.
Test harness
Remote access can cause unpredictable behaviour. Such behaviour however often occurs only in production environments, not in controlled integration testing environments. To safeguard one’s application against corner cases, one should explicitly take these scenarios into consideration while testing and intentionally trigger these cases.
Decoupling middleware
In order to decouple systems from each other, messaging systems can be used. Temporary failure of a subsystem can be compensated by persistent message storage.
Curtains up for Hystrix
The stability of a system should be considered an important non-functional requirement right from the start. The aforementioned stability patterns can serve as helpful guidelines on which a sensible design decisions can be developed. Unfortunately, this insight come too late for Mr. K. The system is already in production, and we all know how difficult it is to change the architecture of a system retroactively. But perhaps he should take a look at Hystrix .
Hystrix was developed by the video-on-demand provider Netflix and is made available to the developer community under the Apache license. The library supports the programmer in the development of robust distributed applications by encapsulating interactions with external systems, services or libraries, thus isolating them from one’s own system, which will continue to function even if its dependencies temporarily fail.
Hystrix and the patterns
With Hystrix some of the described stability patterns can easily be integrated into one’s own system. Potentially dangerous actions are encapsulated within Hystrix command objects. Besides the primary action, each command can also define a fallback action that will be called if the primary action cannot be executed successfully.
Each Hystrix command is monitored by a circuit breaker which logs the success of each call and checks if a predefined threshold for failed calls is exceeded. In this case the circuit opens and further calls will be blocked. When the circuit breaker is open the fallback action will executed instead. To check if the other system has become available again, a small number of calls to this Hystrix command will be periodically issued. If they succeed repeatedly the circuit will be closed and the external system can be called again as usual.
To isolate dependencies between systems, Hystrix uses bulkheads. Each Hystrix command is executed in its own thread by default. An independent thread pool is assigned individually to each dependent system, so that other systems can still be called if the thread pool for a particular external system has already been blocked.
For each Hystrix command timeouts can be specified. But timeouts require careful attention. The Hystrix timeout only determines the period after which Hystrix returns control to the calling application thread. The thread of the particular client continues running and can only be released if it has managed its own timeout, or otherwise when it returns to normal completion or an error condition. Thus the Hystrix thread does not prevent overflow of the corresponding thread pool, but it does permit blocking of the application thread.
“Always Available” will be always available
But enough of the dry theory. Mr K.’s flight booking system is an ideal candidate for experiencing Hystrix out in the wild. Within the current, very fragile condition the flight information systems of the individual airlines are accessible by remote calls. Listing 1 shows a simplified implementation of a call.
// Unsecured call to an airline system for requesting flight data
public List<FlightOffer> findFlightOffers(String destination, DateTime departure) {
ClientResponse clientResponse = Client.create()
.resource("http://super-cheap/flights/")
.queryParam("departure", departure.toString())
.queryParam("destination", destination.toString())
.get(ClientResponse.class);
return toFlightOffers(clientResponse);
}This quite harmless looking piece of code is one of the reasons for Mr. K’s nightly troubles. The Jersey client does not set a timeout by default and the whole call is executed within the web server’s general thread pool. If the airline system does not respond, or responds too slowly, all the application threads will be blocked after some time. A classic example of a cascading error. The failure probability then increases with the number of accessed external airline systems.
As explained, Hystrix can prevent this problem by encapsulating the unsecured call within the run method of a Hystrix command (see listing 2).
// The same call encapsulated in a Hystrix command and
// thus secured though a circuit breaker.
public class SuperCheapFlightOffers extends HystrixCommand<List<FlightOffer>> {
private final String destination;
private final DateTime departure;
protected SuperCheapFlightOffers(String destination, DateTime departure) {
super(HystrixCommandGroupKey.Factory.asKey("SuperCheap"));
this.destination = destination;
this.departure = departure;
}
@Override
protected List<FlightOffer> run() throws Exception {
// potentially insecure call
return findFlightOffers(destination, departure);
}
}Hystrix sets a timeout and relocates execution into a separate thread pool which is determined by setting a group key (here “SuperCheap”). Thereby the danger of blocked threads within the application’s thread pool is averted. As explained, it is sensible to additionally set the Jersey timeout in order to prevent blocking the particular Hystrix thread.
On the resource level “Always Available” is now encapsulated. In case of a timeout, an error or an open circuit breaker, a Hystrix runtime exception would be triggered which would have to be handled by each caller. That makes sense if the attempted action is to be seen as failed and no sensible fallback is possible. In Nygard’s stability patterns this approach is described as a “fail fast pattern”.
For “Always Available” however, a sensible functional fallback can be added by overriding the getFallback method (listing 3).
public class SuperCheapFlightOffers extends HystrixCommand<List<FlightOffer>> {
private final String destination;
private final DateTime departure;
protected SuperCheapFlightOffers(String destination, DateTime departure) {
// ...
}
@Override
protected List<FlightOffer> run() throws Exception {
// ...
}
@Override
protected List<FlightOffer> getFallback() {
// Fail silent
return Collections.emptyList();
}In case of an error a simple, empty list is returned, as the particular system after could not deliver any offers in a timely manner. A meaningful result is returned and the search can continue. A fail-silent-strategy is functionally a clean solution here.
More refined fallback strategies are also conceivable. Instead of an empty list, the last cached data could be returned or a call to a backup system could be issued. This call could again be executed through a Hystrix command, as nesting of commands is also possible.
Hystrix commands can be issued in various ways. The most simple is synchronous execution via execute (listing 4).
public List<FlightOffer> search(String dest, DateTime depa) {
List<FlightOffer> ofs1 = new SuperCheapFlightOffers(dest, depa).execute();
List<FlightOffer> ofs2 = new SuperBeautifulFlightOffers(dest, depa).execute();
List<FlightOffer> ofs3 = new SuperFastFlightOffers(dest, depa).execute();
List<FlightOffer> ofs4 = new SuperSecureFlightOffers(dest, depa).execute();
return collectAll(ofs1, ofs2, ofs3, ofs4);
}Interrogation of individual airline systems is thus serialized. This generates much idle time through unnecessary waiting for processes that actually could run in parallel. Parallel processing is enabled through the method queue. As results futures will be returned that only need to be evaluated when the results must be integrated (listing 5).
public Iterable<FlightOffer> search(String dest, DateTime dep) {
Future<List<FlightOffer>> future1 = new SuperCheapFlightOffers(dest, dep).queue();
Future<List<FlightOffer>> future2 = new SuperBeautifulFlightOffers(dest, dep).queue();
...
try {
List<FlightOffer> offers1 = future1.get();
List<FlightOffer> offers2 = future2.get();
...
return CollectionUtils.union(offers1, offers2,...);
} catch (InterruptedException | ExecutionException e) {
logger.error("unexpected exception", e);
return Collections.emptyList();
}
}In this version first all requests are issued sequentially without waiting for results, so that they can be processed in parallel by individual systems. Then all results are collected sequentially. The get-method of the futures may be blocking the application thread as long as a result has not been returned, but that is no problem as, in the meantime, further futures can be gathered.
But the whole problem can be solved even more elegantly. By calling the observe method Hystrix can be executed reactively. This is no coincidence as [2] is also provided by Netflix. With RXJava asynchronous operations can be elegantly linked within the code. Thus the previous call can be implemented in a significantly more compact and less error prone fashion.
public Iterable<FlightOffer> search(String dest, DateTime dep) {
Observable<List<FlightOffer>> obs1 = new SuperCheapFlightOffers(dest, dep).observe();
Observable<List<FlightOffer>> obs2 = new SuperBeautifulFlightOffers(dest, dep).observe();
// Parallel interrogation of all systems with a combined result
Collection<FlightOffer> combinedResult = Observable
.combineLatest(obs1, obs2, CollectionUtils::union)
.toBlockingObservable()
.first();
return combinedResult;
}All queries, secured through Hystrix, will continue to be executed in parallel. And the bulk of all results will be received in a simpler manner. Unfortunately a detailed discussion of RXJava is out of scope here. But we want to encourage you to take a look at the the excellent RXJava documentation, to understand its wide ranging application possibilities. For example, with RXJava it would also be very easy to only include the first responding system, or the first 20 flight offers.
Iterating towards the perfect configuration
The default configurations of Hystrix are based on how it is used by Netflix and are therefore mostly well chosen, but do not fit all applications. For optimization of performance and stability, individual values for particular commands and pools must be specified. For that it is necessary to have metrics from production that will provide information about the real behavior of a system.
Here another feature of Hystrix comes into play. Each Hystrix object, for example commands, circuit breakers or thread pools, publishes events as well as their current state through a continuous activity stream. This can be provided in various formats and presented visually in different ways. For this purpose Netflix offers an out of the box dashboard, the so called [3], which presents the actual state of each command in a visually clear manner (Dashboard). If there are further instances of the application the activity streams can be bundled using [4] for presentation within the dashboard. Also supported are libraries like [5]or [6], which then can be visually presented through [7].
The obtained metrics are not just pleasing to statisticians but can be used to adjust configuration within the production environment. If it is noticed that for example a thread pool was sized insufficiently, it can be optimized iteratively until better performance is observed. This is possible because Hystrix is monitoring changes to the configuration files as well as publishing all properties via JMX. This way Hystrix offers many ways of fine tuning to affect the behavior of a system. Only through this iterative improvement one can arrive at a truly stable and performant system.
Hystrix Performance Features
- Semaphore: Instead of limiting the number of calls through thread pools, this can also be accomplished by using semaphores. This should only be done if a really high load on the command leaves no alternatives. Timeouts are not supported in this case.
- Request Collapser: To reduce the number of requests, inquiries can be gathered into packages, a good optimization when network connections are in short supply at high code complexity.
- Caching: Requests can be fitted with a cache key to satisfy identical inquiries directly from the internal Hystrix cache.
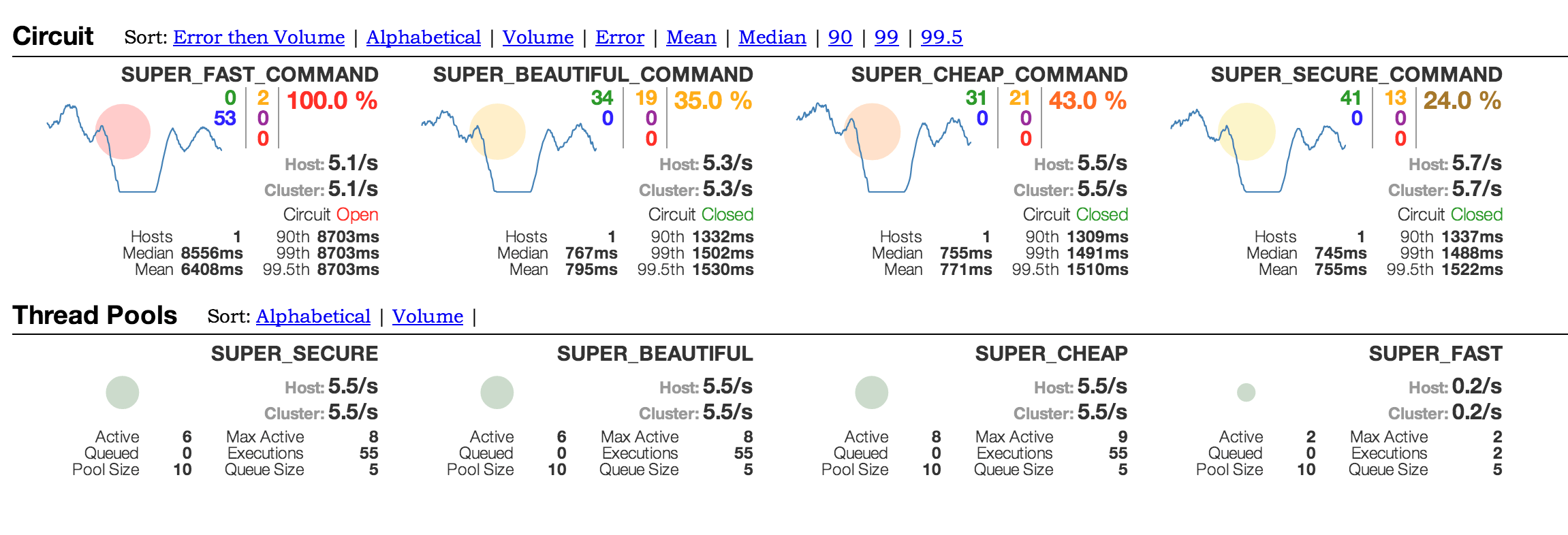
A conclusion
Distributed systems that do not implement the shown stability patterns are shaky at best. The comprehensive implementation of all patterns however involves considerable effort and requires great diligence. Using an appropriate library is therefore recommendable and facilitates implementation.
In our view Hystrix is a good choice. The software has been put to the test and proven itself through its application by Netflix and in our own projects as well. That Hystrix requires integration via command patterns instead of annotations is one of its advantages in our view. The code becomes more expressive and clearly signals that a call is potentially unsafe. Nonetheless retrofitting existing applications is possible without problems. What really convinces is the built-in monitoring system which makes system resources visible by default.
Should this overview have triggered your curiosity, we can recommend reading the Hystrix documentation. Comprehensively and in-depth it presents all the details for which there was no room here.
But if you now decide for Hystrix or achieve stability of your applications through other approaches (as for example [8] or [9]‚) we shall leave up to you. But Mr. K could, after retrofitting Hystrix, finally sleep in peace again.
References
-
Michael T. Nygard, Release It!: Design and Deploy Production-Ready Software, 2007 ↩︎
-
https://github.com/Netflix/RxJava ↩︎
-
https://github.com/Netflix/Hystrix/wiki/Dashboard ↩︎
-
https://github.com/Netflix/Turbine ↩︎
-
http://metrics.codahale.com/ ↩︎
-
https://github.com/Netflix/servo/wiki ↩︎
-
http://graphite.wikidot.com/ ↩︎
-
https://code.google.com/p/kite-lib/ ↩︎
-
http://doc.akka.io/docs/akka/snapshot/common/circuitbreaker.html ↩︎