Generate Text with loremipsum.de
On loremipsum.de:
[...] Simply generate as much Lorem ipsum text as you require [...]
Really useful once you need a specific amount of text. Much of the background of Lorem Ipsum is also well described on the site.
On loremipsum.de:
[...] Simply generate as much Lorem ipsum text as you require [...]
Really useful once you need a specific amount of text. Much of the background of Lorem Ipsum is also well described on the site.
Really interesting eclipse plugins there, especially EclipseMetrics, I'll definitively turn back and try the others soon.
I was recently involved in code reviews on a project. During the review activity, I came to the following levels of code review:
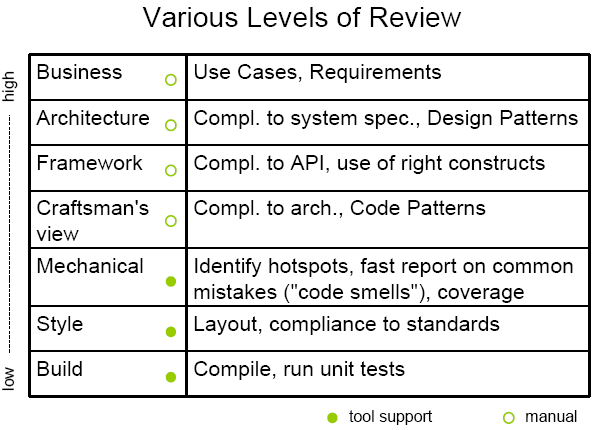
The lower you are, the better is the tool support for finding hot spots. Nevertheless, I fint it interesting to have this layering in mind when reviewing code. Depending on the layer, you have a different focus and the range of code you are looking at may vary as well.
This table may be not exhaustive, so I would be happy to get feedback on that.
I propose here a simple approach for testing your generator written using oAW and the JUnit test framework. A generator usually consists of model to model transformations and model to code transformations. It would be nice if one could test these steps independently, without having to run the whole generator (or workflow in oAW terms).
Let's consider this simple example: convert from an object model (a class) to a relational model (a table) and finally create text (SQL statements).
For the first transformation (M2M, from class to table), we have an Xtend extension (in the file obj2rel.ext). Please note that the code has been simplified in the next listings for readability.
Table transformClass( Class c ): setName( c.name ) -> getColumns().add( c.attributes.transformAttribute() ) ;
For the second one (M2T, from Table to text), we have an XPand template (in the file rel2sql.xpt):
«DEFINE sql for Table» create table «name» ( «EXPAND sql for columns » ) «ENDDEFINE»
First of all I would like to test if the table created after the M2M transformation is right. For that, I define a unit test:
public class TestTable {
private XtendCaller ext;
@Before
public void init(){
ext = new XtendCaller("my::package::obj2rel",
"metamodelPackage_Object",
"metamodelPackage_Relational");
}
@Test
public void testObj2Rel(){
Class c = createTestClass("TestClass", "att1",
"String", "att2", "Integer");
Table t = (Table)ext.call("transformClass", c );
assertEquals( c.getName(), t.getName() );
assertEquals( c.getAttributes().size(),
t.getColumns().size() );
// more asserts ...
}
}
Then, as I did it for my extensions, I test the model to text transformation by defining another unit test:
public class TestSql {
private XpandCaller xpt;
@Before
public void init(){
xpt = new XpandCaller("metamodelPackage_Relational");
}
@Test
public void testObj2Rel(){
Table t = createTestTable("...");
xpt.evaluate("my::package::rel2sql", pl1dt);
String expexted = IOUtils.toString(
new FileInputStream(new File("reference.file")) );
assertEquals(expected, xpand.getOutput() );
}
}
As you can see, the various unit tests can cover different parts of the transformation independently. You can also combine a model to model transformation and a model to text transformation in one test if you do not want to use intermediate test data. The real advantage comes by leveraging the JUnit framework in an IDE like Eclipse where you can simply use the diff feature to see where a test fails. This is extremely helpful for comparing string objects such as a text file (which contains the reference artefact) and the result of a M2T template transformation (see next figure).
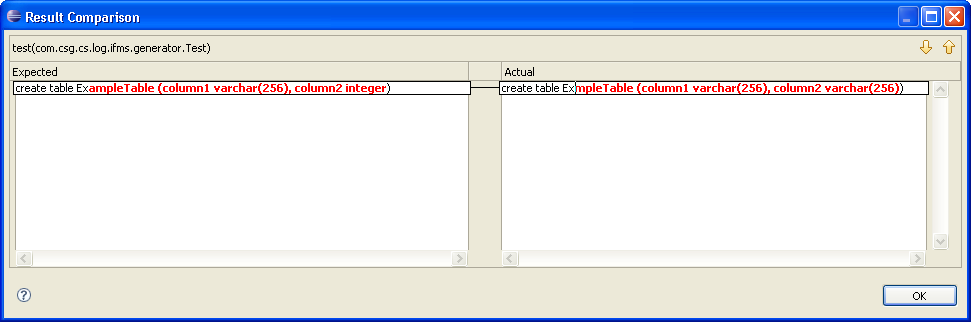
The two helper classes XtendCaller and XpandCaller are helpful decorators over the two classes XtendFacade resp. XpandFacade already available within the oAW framework. You will the code for these classes here:
XtendCaller
XpandCaller
StringOutput
Thanks to Antoine Logean for his feedback on this approach.
I recently spent an hour figuring out why my Xtend/Xpand code did not produce what I expected. I'm writing a code generator that generates PL/I source code for call level interfaces based on abstract service specifications. A service has an input structure and an output structure.
simplified PL/I service signature:input: Structure
- typeName: Field
- businessAttribute1: Field
- ...
- businessAttributeN: Fieldoutput: Structure
- typeName: Field
- further attributes...
In each of them there is a structure field containing the type name among other business attributes. Both input and output structures should have this typeName field. During model transformation, first the input and then the output structure is created. Nevertheless, as soon as the output structure was created, the input structure kind of lost the typeName field.
After debugging (and thinking a little bit about the causes), I found out that it was due to some features of both Xtend and Ecore. I have an Xtend create expression for creating the typeName field:
create Field createTypeNameField():
// code omitted
;
In the Ecore model, there is a containment association between Structure and Field, i.e. a structure contains a list of fields.
And there we are, the create expression caches the Field instance, the key is "empty" since the create expression has no parameter (kind of singleton). Hence, during the second assignment of the typeName field (to the output structure), the first containment reference to the input structure gets "overwritten" (aka Ecore containment feature).
I solved the problem by assuring the creation of a separate instance of the typeName field each time. For this, the create expression has now a key parameter which is different for the input and for the output structures. Now the cache for the typeName field is parametrized with the key, even if the key is not used within the code of the expression:
create Field createTypeNameField(String key): // code omitted ;
As a summary, be aware of create expression with objects involved in containment associations.
I recently faced the following error message on my PC:
This definitely made me take a turn in my computer career...