ActiveResource and Associations
Ok, it’s been quite a while since the last post popped up here; that’s because I struggled with the innoQ internal timereporting- and invoicing-application I’m working on, which is my diploma thesis, too.
And here’s one of my problems I had…
Preface
Concerning users that are going to use my application, there has been a change made, so my app is no longer responsible for user management. This is now all done by a separate application. And this applications has a REST interface which I have access to and should obtain my user data from, as well as handle authentication. I now look at the “obtain data” part, because the authentication part is definitely worth another blog post.
ActiveResource basics
Now: receiving data from another Rails app with a REST interface is quite simple. In the model (in my case User) you inherit from ActiveResource::Base instead of ActiveRecord::Base and specify a site url to the remote Rails application. Like this:
class User < ActiveResource::Base
self.site = "http://the.url.to/yourapp/"
end
Now you can obtain user data almost the same way you do with ActiveRecord classes:
User.find(2) # finds the user with the id of '2'
or even
User.find(:all) # finds all users in the remote app
if you like.
My problem
But what if your resource is somehow associated with your local model and database?
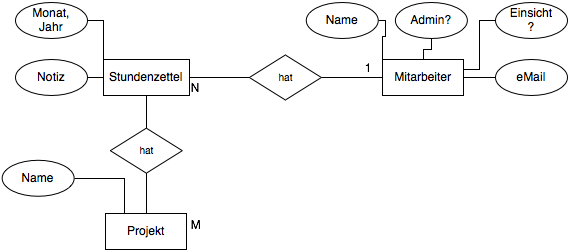
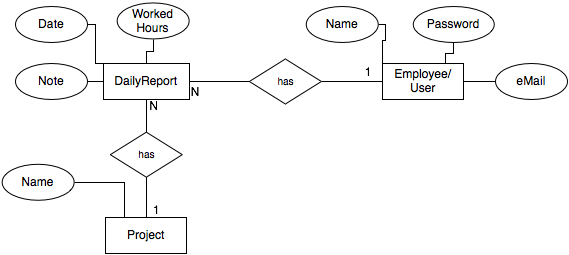
In my case an user has many projects and a project has many users. So here you have a many-to-many relationship.
That really is more difficult for problems like “I’d like to obtain all users for a specific project” and vice versa, because you can’t just make up a many-to-many relationship as you would with two ActiveRecord objects. Like this:
has_and_belongs_to_many :projects # or
has_many :projects, :through => 'projects_users'
In a class which inherits from ActiveResource this is not supported/allowed.
Ok, in my project model these statements would work, because it is an ActiveRecord object. But all the methods you gain through this won’t work either, because they don’t know the you are referencing a model of type ActiveResource and all finds will fail.
So what to do?
Here’s what works for me (so far).
But I’m sure there are many more ways out there to solve this, and I’d really appriciate every comment on this topic, ‘cause I am curious if there’s a more elegant solution. So, there you go:
My solution
Remember the initial situation:
Project (ActiveRecord - in my app) (M)—————-(has)—————(N) User (ActiveResource - remote app)
So first of all I created a join table and the corresponding join model by typing (in the console, of course):
script/generate model projects_users
This creates a model for me with along with a migration file. Inside this file I write these lines:
class CreateProjectsUsers < ActiveRecord::Migration
def self.up
create_table :projects_users do |t|
t.integer :project_id, :user_id, :null => false
t.string :color, :null => false
end
end
def self.down
drop_table :projects_users
end
end
An advantage of join models is that you can store additional attributes in the join table. The only thing I store along the project_id and the user_id is a color. That’s just relevant for the front-end to display the project in the correct color, so don’t get irritated. ;-)
Then, I ran the migration:
rake db:migrate
Now, let’s head over to the association part.
As you can’t put any associations in a ActiveResource model, there’s nothing to do in the User model.
In the Project model I put a has_many statement:
has_many :projects_users, :class_name => "ProjectsUsers"
(Note, that in my case I had to explicitly tell the class_name of the join model class, because Rails assumes this to be singular, i.e. ProjectUser.)
In the ProjectsUsers model I wrote the following two lines:
belongs_to :project
belongs_to :user # so far this isn't used by me, but it may be useful some day
Now the interesting part: How can you get all users for a given project in a way like project.users.find(:all)?
In project.rb, define a method called users:
def users
user_ids = self.projects_users.find(:all, :select => "user_id")
users = user_ids.collect { |projects_users| User.find(projects_users.user_id) }
end
Now via project.users you’ll get all the users you need.
(I’m pretty sure you can rewrite this, so that it works the railsway and you can call project.users.find(:all) instead, but I haven’t tried it, yet)
Ok, the other way round, meaning obtaining all projects for a specific user, I faked it a bit, and I’m sure you can do better here, too. But it works!
Instead of creating a projects method in the User model, I coded a method called self.find_by_user_id in the Projects model:
def self.find_by_user_id(userid)
project_ids = ProjectsUsers.find_all_by_user_id(userid, :select => "project_id")
projects = project_ids.collect { |projects_users| projects_users.project }
end
You can call it this way:
user_projects = Project.find_by_user_id(2)
And BOOM!, you have all projects for the user no. 2.
That’s all folks! This was my solution/workaround for integrating a REST-Resource via a many-to-many association in Rails. Hope you liked it. :-)


 Hi. I'm Daniel Pietzsch and this is my innoQ-Blog. I'm a 26y old student at
Hi. I'm Daniel Pietzsch and this is my innoQ-Blog. I'm a 26y old student at 
Recent Comments